1. 解压http://builds.nightly.webkit.org/files/trunk/src/WebKit-r100089.tar.bz2到cygwin目录下
2. 下载win32预编译依赖库: ./Tools/Scripts/update-webkit
3. 修改WebKitLibraries\win\tools\vsprops\common.vsprops(DisableSpecificWarnings=4819), 解决在中文操作系统里编译与某些英文符号不兼容问题。某些新版本的WebCore\platform\DefaultLocalizationStrategy.cpp中引号也要修改一下。
4. 检查系统环境变量:
WEBKITLIBRARIESDIR D:\cygwin\WebKit-r100089\WebKitLibraries\win
WEBKITOUTPUTDIR D:\cygwin\WebKit-r100089\WebKitBuild
DXSDK_DIR D:\cygwin\WebKit-r100089\DXSDK_Feb10
SystemDrive D:
其中SystemDrive对应cygwin安装盘符,DXSDK_DIR是dx9sdk的路径,还需要安装QuickTime SDK。
5. 开始命令行编译:./Tools/Scripts/build-webkit --debug,全部通过之后再用vc2005 ide打开项目并调试,否则某些脚本会有问题。
6. 安装Safari,复制相关运行时文件到WEBKITOUTPUTDIR子目录,运行MiniBrowser
ps1: vc2005需要安装sp1, 否则stl链接会出错。智能分析造成cpu太卡,可通过改名C:\Program Files\Microsoft Visual Studio 8\VC\vcpackages\feacp.dll来屏蔽。
ps2: dx9sdk可以用比较老的版本,但链接时需要删除common.vsprops里的/SAFESEH。
ps3: 编译Cairo版本: ./Tools/Scripts/build-webkit --debug --wincairo, 需要vista以上系统运行,否则会报WSAPoll找不到。
http://www.cnblogs.com/coffeestone/archive/2011/01/10/1931872.html
http://blog.csdn.net/elfylin/article/details/6769747
posted @
2011-12-31 00:55 foxriver 阅读(1592) |
评论 (0) |
编辑 收藏目前官方ffmpeg的最新版本为0.9, 我们就以此为例:
1. 下载最新git版本的源代码(http://ffmpeg.zeranoe.com/builds/, 本例下载的是2011-12-12版本)
2. 放到MSYS环境里配置,生成config.h文件。mingw gcc是能顺利编译通过整个项目的,并生成最新版的ffmpeg。
3. 建立vc6工程,把相关代码都加入到工程中。由于在vc生成的obj都在一个目录下,所以需要修改文件名,让其不重名。
4. 安装intel compiler 11编译器,单独提取其icl.exe及相关include目录,替换掉vc6自带的cl.exe, 在工程设置里加上/Qstd=c99,用于支持C99语法。
5. 安装intel compiler 10编译器,单独提取lib目录,因为此版本调试库的结构能完美支持vc6的调试信息。
6. 在vc6的options里设置include/exe/lib查找目录,指向intel编译器。
7. 开始修改代码,添加C99的相关linux头文件, 用于支持vc6, (unistd.h, stdint.h, inttypes.h, getopt.h)
8. 添加C99和linux的相关实现代码,ffmpeg需要用到: getopt_long, strtoll, gettimeofday, atoll, usleep等
9. 修改windows的相关兼容代码,GetWindowLongPtr -> GetWindowLong, GWLP_USERDATA
10. 去除硬件加速libavcodec代码,和依赖库代码。选择所需要的模块,修改相关的allcodec.c, alldevices.c, allfilters.c, allformats.c
11. 加上链接库,sdl.lib, winmm.lib, dxguid.lib, wsock32.lib
12. 在os_support.c里,把<winsock2.h>移动到文件最前面。
13. 如果是ffmpeg, 已经能顺利编译了。如果是ffplay,还需要编译静态sdl, 并链接。
14. 等等,音频运行不正确?有雪花声?因为还需要替换所有文件里的<math.h>为<mathimf.h>, 默认的rint等数学函数和gcc不兼容。
15. ok, 大功告成,纯C版本完美运行。
16. 由于ffmpeg0.9在c文件里,添加了一些intel compiler不支持的mmx语法,所以编译mmx/sse加速版本时,一小部分.c文件需要依赖mingw gcc编译成.o文件,再通过vc6的lib.exe工具转换成lib,让vc6链接上。当然还要加上yasm编译的很多汇编obj.
17. 有兴趣的,可以继续以此方法编译x264库,官方最新代码MMX版也可以顺利通过。
posted @
2011-12-17 02:09 foxriver 阅读(2642) |
评论 (0) |
编辑 收藏普通jpeg
8x8块编码DCT,熵编码=Huffman,
jpeg2000
有小波浮点或整数两种变换算法, 熵编码=MQ-Code,中等压缩比有良好的表现,衍生格式为ecw,用于压缩卫星图片。
jpeg-xr
john carmack在rage资源中使用的格式,他推荐的一般都不会差。微软定义的开源算法,比jpeg2000有所进化,主要改进有DCT块的层次保存格式,块之间后期接缝处理。有无损和有损模式,适合长期保存游戏贴图。
h264 iframe
使用单帧内预测技术,图片越大,越能体现超强的压缩比。熵编码=Gobomb-Code
其他一些游戏压缩格式:
pvrtx
iphone压缩格式, 效果比较理想,不开源。
etc1
android中普遍的压缩格式。
dxt1, dxt3, dxt5
早期的经典格式, 采用块状分割,恒定压缩比,适合二次压缩。
bc6, bc7
被微软强化的dx10压缩格式,和dxt1一个压缩比,图片质量非常好。
其他非游戏压缩格式:
1. 图片扫描文件二值压缩格式, JB2(djvu), JBIG2(pdf), TIFF C4
2. 数码相机里RAW压缩格式, 用于近无损压缩,大部分厂商都有自己的定义:Epson ERF, SGI Log24, Nikon NEF, Kodak DCR, Pentax PEF等
-------------------------
1:100的图片压缩效果对比

游戏贴图压缩质量对比图
posted @
2011-12-06 01:57 foxriver 阅读(4957) |
评论 (0) |
编辑 收藏所有涉及图片放大缩小,旋转或图片扭曲的操作,都会有Resample. 而插值算法,就是为了减少走样而。其中又分卷积和后置滤波。
1. 卷积,通常在源图片空间采样,但有时候warp算法复杂(比如RBF径向基函数),造成像素在源图片空间纵横比例不同,往往用后置滤波更简单。以下对比是1:1对象空间的旋转变换。
原图如下,目标质量对比图为中心旋转5度,重复72次,正好360度恢复原样。




posted @
2011-03-21 01:01 foxriver 阅读(2222) |
评论 (4) |
编辑 收藏crysis2 dx9一帧渲染流程:
1. TestCooperativeLevel()
2. 设置n-patch细分等级D3DRS_ADAPTIVETESS_Y
3. GPU同步设置,Query9::GetData(), Query9::Issue()
4. ShadowMap
5. ZPass, 生成GBuffer信息。
6. Depth_DownScale
7. SSAO
8. Scattering List
9. Deferred Lighting
9.1 Irradiance Volume Evaluate
9.2.1 Visares
9.2.2 Outdoor
9.3 Deferred CubeMaps
9.4 Deferred Lights
9.5 SSAO_BLUR
9.6 Deferred Lights
9.6.1 ShadowMap Pool
10. 不透明物体绘制。
10.1 General(BW)
10.2 地形(BW)
10.3 General(AW)
10.4 地形(AW)
10.5 细节(BW)
10.6 细节(AW)
10.7 皮肤生成
10.8 皮肤应用
11. 半透明物体绘制。
11.1 雾
12. Glow Gen(光晕生成)
13. HDR Post Proesss
13.1 Motion Blur, 运动模糊
13.1.1 Motion Vector Gen
13.1.2 Motion Vector Dilate
13.1.3 Motion Vector Apply
13.1.4 Motion Vector Apply Pass 2
13.2 HalfRes downsample
13.3 QuarterRes downsample
13.4 BrightPass
13.5 Bloom and Flares
13.5.1 TexBlur 16Taps
13.5.2 TexBlur Gaussian
13.5.3 TexBlur Gaussian
13.5.4 HDR flares
13.6 Sunshafts生成
13.7 MergeColorCharts
13.8 CombineColorGradingWithColorChart
13.9 ToneMapping
14. Post Effects
14.1 MSAA
14.2 3D HUD
15. 刷新绘制
16. 绘制界面
17. 绘制调试信息

posted @
2011-02-18 02:51 foxriver 阅读(2307) |
评论 (0) |
编辑 收藏网上开源RSA实现库:
openssl 强大的工具集合
crypto++ 过于复杂的封装,特别是rsa实现模块。
速度上有优势的:XySSL, CyaSSL(都使用的LibTomMath)
逻辑上有优势的:axcrypto, raknet
还有一些大数库: vlong,WinNTL
对于公钥签名认证, google android自带的libmincrypt有超快的实现方法,可惜代码只是为了一家优化,仅提供e=3的加速。而网上通常的ASN.1证书,都用了e=63357。
posted @
2011-02-10 07:11 foxriver 阅读(1715) |
评论 (0) |
编辑 收藏当QQ群聊天记录日积月累,达到一定数量级的时候,要查找某些单一文字,往往会花费10几秒甚至几分钟才有反应。除去磁盘读取的时间,是否对聊天记录做一个全局索引也是个重要的优化,这篇文章就是为了优化文本查找速度,介绍一个最简单的方法。
试着把QQ每条聊天记录看成SQL里单一记录,对单条记录做全文索引。这里用的方法是bit位快速匹配。假设一条聊天记录是"test", 转换成16进制,就是"74 65 73 74", 对单条记录,定义196位bit空间(占用24字节),定义为数组A, 然后按bit层(注意不是字节)做or操作: (A = A or N, 把A的第N个bit设置为1)
初始状态:
A = 0; // 【0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00】
A = A or 0x74; // 【0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x10,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00】
A = A or 0x65; // 【0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x20,0x00,0x10,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00】
A = A or 0x73; // 【0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x20,0x00,0x18,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00】
A = A or 0x74; // 【0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x20,0x00,0x18,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00】
使用时,给需要查找的字符串建立相同大小的bit索引B,对查找数据"es"做相同处理:
B = 0;
B = B or 0x65; // 【0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x20,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00】
B = B or 0x73; // 【0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x20,0x00,0x08,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00】
然后把A和B做and操作,如果结果为空(完全没有交集),则可以快速跳过这条记录,而不用去判断实际内容中是否包含了查找文本。
if (B & A)
{
// 两者索引存在交集,有一定的可能性,处理进一步文字查找操作。
}
else
{
// 两者不可能有包含关系,直接跳过本条记录内容,判断数据库下一条记录。
}
原理很简单,就是求两者的交集,但往往简单的索引,能带来意想不到的速度提升。实际测试中,只要输入的查找文本比较短小,大约30%~60%上下浮动的数据都能直接略过,大大节省了查找总耗时。
本人实现中,中文的查找方法相当于两个单字节的英文,为了最大效率利用空间,用算法把中文每个BYTE都压缩在196bit之内。
posted @
2011-01-14 01:22 foxriver 阅读(2207) |
评论 (6) |
编辑 收藏
算是对多重继承里,类型转换所做一个笔记。先看如下代码:
class A
{
public:
A() { m_data = 'A';}
~A() {}
char m_data;
};
class B
{
public:
B() { m_data = 'B';}
~B() {}
char m_data;
};
class C : public A, public B
{
public:
C() { m_data = 'C';}
~C() {}
char m_data;
};
class D : public C
{
public:
D() { m_data = 'D';}
~D() {}
void test()
{
DWORD value = (DWORD)this;
A* address1 = (A*)(value);// 编译通过,类型转换错误(仅在在虚拟继承的情况下),正确的写法:A* address1 = (A*)((D*)value);
B* address2 = (B*)(value);// 编译通过,类型转换错误,正确的写法:B* address2 = (B*)((D*)value);
C* address3 = (C*)(value);
D* address4 = (D*)(value);
printf("%c %c %c %c", address1->m_data, address2->m_data, address3->m_data, address4->m_data);
}
char m_data;
};
void main()
{
D d;
d.test();
}
代码运行后,结果为A A C D,显然B这个类没有正确转换。
A和B都是D的父类,为什么A* address1 = (A*)value这句转换正确,而B* address2 = (B*)(value)出错呢?这就是多重继承的不可判断性。
正因为这种特性的存在,我们在实际使用中,应该尽量避免多重继承,选择单一继承这种模式。JAVA就是如此,最初设计时就只能单一继承,而多重继承则演变为纯虚接口(interface),这样就规避了此类问题。但可惜,在C++里,WTL和QT都大量使用这种模型,想在实际项目中完全避免,也很困难。
要解决,有几种方法。
1. 把B* address2 = (B*)(value)这行,改写为B* address2 = (B*)((D*)value); 这样就能直观的传达给编译器,B正确的偏移量。
最终输出A B C D,正是我们想要的结果。
2. 显示使用static_cast,当编译器不能确定转换类型时,会提示编译错误信息。
例如:
B* address2 = static_cast<B*>(value); // 编译失败。
B* adddres2 = static_cast<B*>((D*)value); // 编译成功,并且结果正确。
3. 使用RTTI解决。
--------------------------------------------------
看似问题解决了,可如果一旦改写为
虚拟继承(class C : virtual public A, virtual public B)这种形式,A运行时还是会出错,必须写成A* address1 = (A*)((D*)value);。如程序里用到了多重继承,一定要小心+谨慎。
posted @
2011-01-12 15:53 foxriver 阅读(6365) |
评论 (10) |
编辑 收藏加入比较的4种方法有:
1. 快速高斯模糊。
2. 二次Summed Area Table Blur(适合gpu, 常用于DOF,http://www.gamasutra.com/view/feature/3102/four_tricks_for_fast_blurring_in_.php)
3. Alpha Blur(motionblur变种,优化过后的算法,严重依赖相邻像素之间累积关系,不适合gpu, http://freespace.virgin.net/hugo.elias/graphics/x_motion.htm)
4. SuperFastBoxBlur(http://incubator.quasimondo.com/processing/superfast_blur.php)
其中,这四种方法内,除了高斯模糊是O(n)之外,其他都是O(1)效率。也就是说,运算速度和模糊半径没有关系,只和图片大小有关。
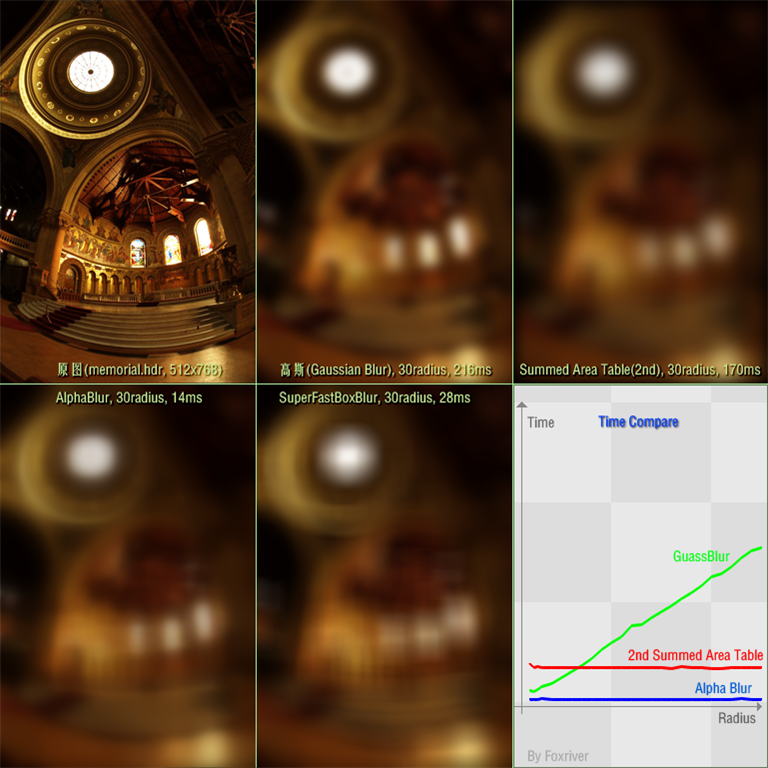
图上时间仅供参考,除了AlphaBlur代码优化过,其它方法仅仅是基本实现原理。SuperFastBoxBlur和SummedAreaTable实际使用中,要比图上更快些。
以下方法没有列入比较范围
1. 直接基于O(n*n)的高斯模糊核,速度太慢。图上方法采用纵向和横向高斯核分解。
2. Stack Blur, 比高斯快的方法,并且效果和效率兼备。(http://www.codeproject.com/KB/graphics/blurringwithcuda.aspx)
3. FFT gaussian blur
4. High-Dimensional Gaussian Filtering (bilateral)
5. constant time filters - heat diffusion.(Kass, 2006)
6. constant time filters - SVD, singular value decomposition (Gotsman 1994)
7. SAT衍生出来的一些方法,Fast Filter Spreading,Linear Filters and their Transposes。
---------------------------------------------------
关于2次Summed Area Table实现。
一次SAT采样4个点,二次SAT则需要9个点,三次需要16个点,以此类推。并且乘上对应的Weight Function,除以(面积^n, n = 几次). 详细公式见:Filtering By Repeated Integration
posted @
2011-01-11 01:33 foxriver 阅读(5087) |
评论 (0) |
编辑 收藏#ifndef __file_h__
extern const char table1[];
#else
const char table1[] = "\x30\xB8\xD1\xB8\x10\x68\x3D\xBC\x09\x04\x31\x94\x5C\x91\xAF\x6C";
#endif
#ifndef __file_h__
#define __file_h__
.........function
#endif
--------------------
用以上技巧的前提是,这个.H必须被不同的CPP包含两次以上。
posted @
2010-04-08 11:17 foxriver 阅读(6184) |
评论 (7) |
编辑 收藏