可以根据函数名进行排序,分类统计每个函数占用的代码量,把结果导出到Excel/HTML,查询奔溃地址。
简陋习作,目前只测试了VC6.0(个人比较守旧), 欢迎用过其他vc版本的同学反馈,以便改进。
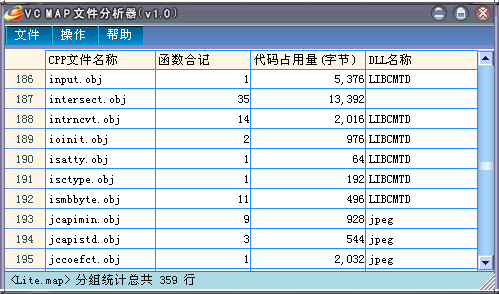
点我下载(300K) (更新1.1版本,支持文件拖移操作,修复字符过长BUG) 感谢Randy提供调试文本!
--------------------------
文件拖进窗体WIN32API实现笔记:
1. 加入头文件#include <shellapi.h>//DragAcceptFiles
2. 修改CreateWindowEx里的exsytle, 添加属性值WS_EX_ACCEPTFILES
3. 最后消息循环里加入处理函数
case WM_DROPFILES:
{
HDROP hDrop = (HDROP)wParam;
char buf[MAX_PATH];
for(int i=0; DragQueryFile(hDrop, i, buf, MAX_PATH); i++)
{
// MessageBox(0, buf, "Dropped File", MB_ICONINFORMATION); //此处处理文件,gbk编码文件名
}
DragFinish(hDrop);// 一定别忘了这句,否则会有内存泄露。
}
return 0;
posted @
2009-03-13 18:23 foxriver 阅读(6764) |
评论 (10) |
编辑 收藏1. 浮点数正确的累加方法。
运行下述代码段:
double value = 99999999.99;
double sum = 0.0;
for(int i=0;i<8192;i++)
{
sum += value; // 错误的浮点累加方法
}
printf("%18.2lf", sum); // 819199999918.02 --wrong
运行结果,sum是错误的, 和正确值相差0.06(99999999.99 * 8192 = 819199999918.08),对于报表之类的高精度的项目数据统计,这是不能容忍的,循环越多误差越大。解决方法之一,可以用高精度算法库来代替,比如doubledouble类型,或选择微软的解决方法:本意是,浮点相加硬件实现是减法。把加法改成减法,把误差也计算进去。
上述代码修改后:
double value = 99999999.99;
double sum = 0.0;
double C=0, Y, T;
for(int i=0;i<8192;i++)
{
Y = value - C;
T = sum + Y;
C = T - sum - Y; // 正确的浮点累加方法,做减法。
sum = T;
}
printf("%18.2lf", sum);// 819199999918.08 --correct
加了误差累计,这样结果就正确了。还有浮点运算法则最重要一点,是不符合实数算法相同的代数规则。 (sum+Y)-sum-Y ,结果是不等于零的。
参考:
http://blog.csdn.net/l1t/archive/2004/10/01/122777.aspx
http://msdn.microsoft.com/en-us/library/aa289157(VS.71).aspx
---------------------------------------------------------------
2. 转义符和字符串分离。
char* aaa1 = "e:\\12\xB2\xE2""file.txt";
char* aaa2 = "e:\\12\xB2\xE2file.txt"; // 编译失败, 0xE2File被识别为大字符进行转意。
切忌转义符后直接跟字符串,这种错误有时候编译器通过,但结果出错,很难查。
------------------------------------------------------------
3. 绘制unicode的surrogate pair
用TextOut可以绘制出来,直接用GetGlyphOutline会失败,以下是通过TTF文件的笔划ID号,来绘制UCS-4的方法。
3.1 在ttf文件里,寻找代码的笔划ID:
uint glyphid_code = 0;
uint n;
for (n=0; n<nGroups; n++)
{
uint startCharCode = vfile.getBigEndianInt();
uint endCharCode = vfile.getBigEndianInt();
uint startGlyphID = vfile.getBigEndianInt();
uint code;
for (code = startCharCode; code <= endCharCode; code++)
{
uint w1 = 0;
uint w2 = 0;
// http://en.wikipedia.org/wiki/UTF-16/UCS-2
if (code > 0x10000)
{
uint v = code;
uint v1 = v - 0x10000;
uint vh = v1 >> 10;
uint vl = v1 & 0x3FF;
w1 = 0xD800 + vh;
w2 = 0xDC00 + vl;
}
if (w1 == 0xD842 && w2 == 0xDF9F)
glyphid_code = (code - startCharCode) + startGlyphID;
}
}
3.2. 用笔划ID(glyphid_code)来直接绘制UCS-4文字.
---------------------
// must use GGO_GLYPH_INDEX
DWORD bufsize = GetGlyphOutline(hdc, glyphid_code, GGO_NATIVE|GGO_GLYPH_INDEX, &gm, 0, 0, &mat);
if (bufsize == 0 || bufsize == GDI_ERROR)
{
DWORD err = GetLastError();
continue;
}
byte* bufdata = new byte[bufsize];
if (GetGlyphOutline(hdc, r_glyphid_code, GGO_NATIVE|GGO_GLYPH_INDEX, &gm, bufsize, bufdata, &mat) == GDI_ERROR)
{
delete[] bufdata;
}
------------------------------------------------------------
4. 代码优化:
1. 在成员函数里,使用静态数组,避免每次都需要初始化。
2. 在IF判断时,使用likely/unlikely。
3. 减少malloc调用消耗,特别是算法循环中(比如RSA大数算法),使用stack代替。
------------------------------------------------------------
在VC里整合使用intel c compiler的好处:
1. 检查std::string str; printf("%s", str); 此类的致命错误;// non-POD (Plain Old Data) class type passed through ellipsis
2. 使用OpenMP优化代码
------------------------------------------------------------
性能:
1. 图片内存随机访问,在release模式下,data[y][x]二维数组访问和data[y*width+x]一维数组是一样快的,编译器会自动优化乘法。
posted @
2009-02-28 06:33 foxriver 阅读(1837) |
评论 (0) |
编辑 收藏