http://en.wikipedia.org/wiki/Gradient_descent http://zh.wikipedia.org/wiki/%E6%9C%80%E9%80%9F%E4%B8%8B%E9%99%8D%E6%B3%95
Gradient descent is based on the observation that if the multivariable function  is defined and differentiable in a neighborhood of a point
is defined and differentiable in a neighborhood of a point 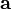 , then decreases fastest if one goes from in the direction of the negative gradient of
, then decreases fastest if one goes from in the direction of the negative gradient of  at ,
at , 
为啥步长要变化?Tianyi的解释很好:如果步长过大,可能使得函数值上升,故要减小步长 (下面这个图片是在纸上画好,然后scan的)。
Andrew NG的coursera课程Machine learning的
II. Linear Regression with One Variable的
Gradient descent Intuition中的解释很好,比如在下图在右侧的点,则梯度是正数, 是负数,即使当前的a减小
例1:Toward the Optimization of Normalized Graph Laplacian(TNN 2011)的Fig. 1. Normalized graph Laplacian learning algorithm是很好的梯度下降法的例子.只要看Fig1,其他不必看。Fig1陶Shuning老师课件 非线性优化第六页第四个ppt,对应教材P124,关键直线搜索策略,应用 非线性优化第四页第四个ppt,步长加倍或减倍。只要目标减少就到下一个搜索点,并且步长加倍;否则停留在原点,将步长减倍。
例2: Distance Metric Learning for Large Margin Nearest Neighbor Classification(JLMR),目标函数就是公式14,是矩阵M的二次型,展开后就会发现,关于M是线性的,故是凸的。对M求导的结果,附录公式18和19之间的公式中没有M
我自己额外的思考:如果是凸函数,对自变量求偏导为0,然后将自变量求出来不就行了嘛,为啥还要梯度下降?上述例二是不行的,因为对M求导后与M无关了。和tianyi讨论,正因为求导为0 没有解析解采用梯度下降,有解析解就结束了
http://blog.csdn.net/yudingjun0611/article/details/8147046
1. 梯度下降法
梯度下降法的原理可以参考:斯坦福机器学习第一讲。
我实验所用的数据是100个二维点。
如果梯度下降算法不能正常运行,考虑使用更小的步长(也就是学习率),这里需要注意两点:
1)对于足够小的, 能保证在每一步都减小;
2)但是如果太小,梯度下降算法收敛的会很慢;
总结:
1)如果太小,就会收敛很慢;
2)如果太大,就不能保证每一次迭代都减小,也就不能保证收敛;
如何选择-经验的方法:
..., 0.001, 0.003, 0.01, 0.03, 0.1, 0.3, 1...
约3倍于前一个数。
matlab源码:
- function [theta0,theta1]=Gradient_descent(X,Y);
- theta0=0;
- theta1=0;
- t0=0;
- t1=0;
- while(1)
- for i=1:1:100 %100个点
- t0=t0+(theta0+theta1*X(i,1)-Y(i,1))*1;
- t1=t1+(theta0+theta1*X(i,1)-Y(i,1))*X(i,1);
- end
- old_theta0=theta0;
- old_theta1=theta1;
- theta0=theta0-0.000001*t0 %0.000001表示学习率
- theta1=theta1-0.000001*t1
- t0=0;
- t1=0;
- if(sqrt((old_theta0-theta0)^2+(old_theta1-theta1)^2)<0.000001) % 这里是判断收敛的条件,当然可以有其他方法来做
- break;
- end
- end
2. 随机梯度下降法
随机梯度下降法适用于样本点数量非常庞大的情况,算法使得总体向着梯度下降快的方向下降。
matlab源码:
- function [theta0,theta1]=Gradient_descent_rand(X,Y);
- theta0=0;
- theta1=0;
- t0=theta0;
- t1=theta1;
- for i=1:1:100
- t0=theta0-0.01*(theta0+theta1*X(i,1)-Y(i,1))*1
- t1=theta1-0.01*(theta0+theta1*X(i,1)-Y(i,1))*X(i,1)
- theta0=t0
- theta1=t1
- end