大学毕业了!!上来感叹一下!并拿出自己的毕业设计分享一下。
这个小东西是用了一个星期完成的。BUG肯定不少,大家凑合着看一下吧。感觉有趣的就拿去玩玩。
说说基本思路。
1.对文件进行分词处理
2.通过统计训练文档当中的词频方差,构造评判矩阵
3.之后在构造待分类文档的评判向量
4.用评判向量和构造矩阵相乘,选出最接近的分类。
具体地方法大家可以参考一下这篇论文:《基于模糊理论的网页过滤算法的实现》
上图:
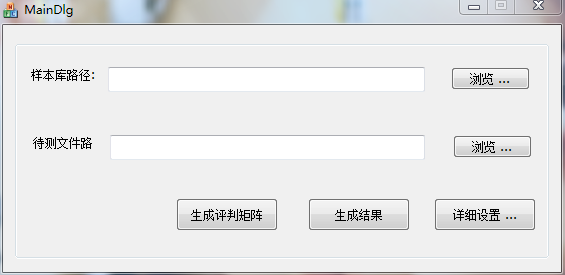
主界面
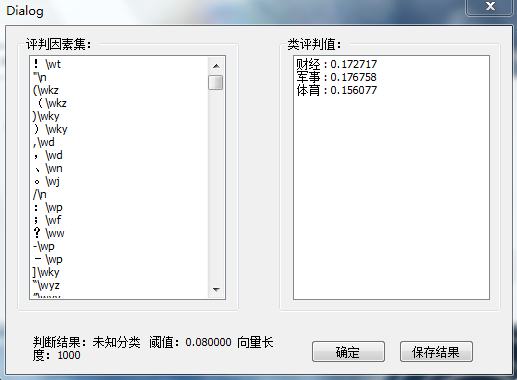
结果文件
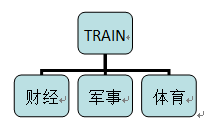
训练文档的目录结构
程序文件:
http://www.namipan.com/d/db9717e2153a1bc504dc597fee9ac32e92b428fcc4fe3900其实正确率还可以进一步提高的。以后有兴趣的时候再来重写一下这个程序吧。
总结:
我尽力优化了这个程序的速度。但还是不理想。
ICTCLAS分词系统的效率低是其中一个重要原因。
我使用了stlsoft中的aoto_buffer来优化内存的分配。
使所有的string在内存当中只存在一份拷贝。
map和vector容器永远只存放string*
无法解决的问题:
我想在一个double数组中存放1/N,2/N,3/N......N/N,以便后来使用。
我觉得这些常量应当能在编译时期确定。但是不知道如何通过定义宏来表示这些数值。
搞的我最后不得不启动一个线程来专门计算这些值。
有兴趣的邮件联系啊~!
posted on 2009-06-12 21:38
HIT@ME 阅读(1436)
评论(2) 编辑 收藏 引用