Bloom Filter 原理与应用
介绍
Bloom Filter是一种简单的节省空间的随机化的数据结构,支持用户查询的集合。一般我们使用STL的std::set, stdext::hash_set,std::set是用红黑树实现的,stdext::hash_set是用桶式哈希表。上述两种数据结构,都会需要保存原始数据信息,当数据量较大时,内存就会是个问题。如果应用场景中允许出现一定几率的误判,且不需要逆向遍历集合中的数据时,Bloom Filter是很好的结构。
优点
- 查询操作十分高效。
- 节省空间。
- 易于扩展成并行。
- 集合计算方便。
- 代码实现方便。
- 有误判的概率,即存在False Position。
- 无法获取集合中的元素数据。
- 不支持删除操作。
缺点
- 有误判的概率,即存在False Position。
- 无法获取集合中的元素数据。
- 不支持删除操作。
定义
Bloom Filter是一个有m位的位数组,初始全为0,并有k个各自独立的哈希函数。

图1
添加操作
每个元素,用k个哈希函数计算出大小为k的哈希向量  "\bg_white \left (H_{1},H_{2}\cdots ,H_{k} \right )")
,将向量里的每个哈希值对应的位设置为1。时间复杂度为  "\bg_white k\cdot O(F_{H})") ,一般字符串哈希函数的时间复杂度也就是
,一般字符串哈希函数的时间复杂度也就是 "\bg_white O(n)") 。
。
查询操作
和添加类似,先计算出哈希向量,如果每个哈希值对应的位都为1,则该元素存在。时间复杂度与添加操作相同。
示例
图2表示m=16,k=2的Bloom Filter, 和 的哈希值分别为(3, 6)和(10, 3)。

图2
False Position
如果某元素不在Bloom Filter中,但是它所有哈希值的位置均被设为1。这种情况就是False Position,也就是误判。
借用示例,如下:

图3
这个问题其实和哈希表中的冲突是相同的道理,哈希表中可以使用开散列和闭散列的方法,而Bloom Filter则允许这样的情况发生,它更关心于误判的发生概率。
概率
宏观上,我们能得出以下结论:
| 参数表 | 变量 | 减少 | 增加 |
| 哈希函数总数 | K | l 更少的哈希值计算 l 增加False Position的概率 | l 更多的计算 l 位值0减少 |
| Bloom Filter 大小 | M | l 更少的内存 l 增加False Position的概率 | l 更多的内存 l 降低概率 |
| 元素总数 | N | l 降低False Position的概率 | l 增加概率 |
False Position的概率为 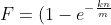^{k} "F=(1-e^{-\frac{kn}{m}})^{k}") 。
。
假设m和n已知,为了最小化False Position,则  。
。
数据

图4
扩展
Counter Bloom Filter
Bloom Filter有个缺点,就是不支持删除操作,因为它不知道某一个位从属于哪些向量。那我们可以给Bloom Filter加上计数器,添加时增加计数器,删除时减少计数器。
但这样的Filter需要考虑附加的计数器大小,假如同个元素多次插入的话,计数器位数较少的情况下,就会出现溢出问题。如果对计数器设置上限值的话,会导致Cache Miss,但对某些应用来说,这并不是什么问题,如Web Sharing。
Compressed Bloom Filter
为了能在服务器之间更快地通过网络传输Bloom Filter,我们有方法能在已完成Bloom Filter之后,得到一些实际参数的情况下进行压缩。
将元素全部添加入Bloom Filter后,我们能得到真实的空间使用率,用这个值代入公式计算出一个比m小的值,重新构造Bloom Filter,对原先的哈希值进行求余处理,在误判率不变的情况下,使得其内存大小更合适。
应用
加速查询
适用于一些key-value存储系统,当values存在硬盘时,查询就是件费时的事。
将Storage的数据都插入Filter,在Filter中查询都不存在时,那就不需要去Storage查询了。
当False Position出现时,只是会导致一次多余的Storage查询。

图5
l Google的BigTable也使用了Bloom Filter,以减少不存在的行或列在磁盘上的查询,大大提高了数据库的查询操作的性能。
l 在Internet Cache Protocol中的Proxy-Cache很多都是使用Bloom Filter存储URLs,除了高效的查询外,还能很方便得传输交换Cache信息。
网络应用
l P2P网络中查找资源操作,可以对每条网络通路保存Bloom Filter,当命中时,则选择该通路访问。
l 广播消息时,可以检测某个IP是否已发包。
l 检测广播消息包的环路,将Bloom Filter保存在包里,每个节点将自己添加入Bloom Filter。
l 信息队列管理,使用Counter Bloom Filter管理信息流量。
垃圾邮件地址过滤
来自于Google黑板报的例子。
像网易,QQ这样的公众电子邮件(email)提供商,总是需要过滤来自发送垃圾邮件的人(spamer)的垃圾邮件。
一个办法就是记录下那些发垃圾邮件的 email 地址。由于那些发送者不停地在注册新的地址,全世界少说也有几十亿个发垃圾邮件的地址,将他们都存起来则需要大量的网络服务器。
如果用哈希表,每存储一亿个 email 地址,就需要 1.6GB 的内存(用哈希表实现的具体办法是将每一个 email 地址对应成一个八字节的信息指纹,然后将这些信息指纹存入哈希表,由于哈希表的存储效率一般只有 50%,因此一个 email 地址需要占用十六个字节。一亿个地址大约要 1.6GB, 即十六亿字节的内存)。因此存贮几十亿个邮件地址可能需要上百 GB 的内存。
而Bloom Filter只需要哈希表 1/8 到 1/4 的大小就能解决同样的问题。
Bloom Filter决不会漏掉任何一个在黑名单中的可疑地址。而至于误判问题,常见的补救办法是在建立一个小的白名单,存储那些可能别误判的邮件地址。
引用
[1] Bloom filter; http://en.wikipedia.org/wiki/Bloom_filter
[2] Summary Cache: A Scalable Wide-Area Web Cache Sharing Protocol;http://pages.cs.wisc.edu/~cao/papers/summary-cache/
[3] Network Applications of Bloom Filters: A Survey;http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.127.9672&rep=rep1&type=pdf
[4] An Examination of Bloom Filters and their Applications;http://cs.unc.edu/~fabian/courses/CS600.624/slides/bloomslides.pdf
[5] 数学之美系列二十一 - 布隆过滤器(Bloom Filter);http://www.google.com.hk/ggblog/googlechinablog/2007/07/bloom-filter_7469.html