转自
http://www.codeproject.com/KB/string/cppstringguide1.aspx
Introduction
You've undoubtedly seen all these various string types like TCHAR, std::string, BSTR, and so on. And then there are those wacky macros starting with _tcs. And you're staring at the screen thinking "wha?" Well stare no more, this guide will outline the purpose of each string type, show some simple usages, and describe how to convert to other string types when necessary.
In Part I, I will cover the three types of character encodings. It is crucial that you understand how the encoding schemes work. Even if you already know that a string is an array of characters, read this part. Once you've learned this, it will be clearer how the various string classes are related.
In Part II I will describe the string classes themselves, when to use which ones, and how to convert among them.
The basics of characters - ASCII, DBCS, Unicode
All string classes eventually boil down to a C-style string, and C-style strings are arrays of characters, so I'll first cover the character types. There are three encoding schemes and three character types. The first scheme is the single-byte character set, or SBCS. In this encoding scheme, all characters are exactly one byte long. ASCII is an example of an SBCS. A single zero byte marks the end of a SBCS string.
The second scheme is the multi-byte character set, or MBCS. An MBCS encoding contains some characters that are one byte long, and others that are more than one byte long. The MBCS schemes used in Windows contain two character types, single-byte characters and double-byte characters. Since the largest multi-byte character used in Windows is two bytes long, the term double-byte character set, or DBCS, is commonly used in place of MBCS.
In a DBCS encoding, certain values are reserved to indicate that they are part of a double-byte character. For example, in the Shift-JIS encoding (a commonly-used Japanese scheme), values 0x81-0x9F and 0xE0-0xFC mean "this is a double-byte character, and the next byte is part of this character." Such values are called "lead bytes," and are always greater than 0x7F. The byte following a lead byte is called the "trail byte." In DBCS, the trail byte can be any non-zero value. Just as in SBCS, the end of a DBCS string is marked by a single zero byte.
The third scheme is Unicode. Unicode is an encoding standard in which all characters are two bytes long. Unicode characters are sometimes called wide characters because they are wider (use more storage) than single-byte characters. Note that Unicode is not considered an MBCS - the distinguishing feature of an MBCS encoding is that characters are of different lengths. A Unicode string is terminated by two zero bytes (the encoding of the value 0 in a wide character).
Single-byte characters are the Latin alphabet, accented characters, and graphics defined in the ASCII standard and DOS operating system. Double-byte characters are used in East Asian and Middle Eastern languages. Unicode is used in COM and internally in Windows NT.
You're certainly already familiar with single-byte characters. When you use the char data type, you are dealing with single-byte characters. Double-byte characters are also manipulated using the char data type (which is the first of many oddities that we'll encounter with double-byte characters). Unicode characters are represented by the wchar_t type. Unicode character and string literals are written by prefixing the literal with L, for example:
 Collapse
Collapse Copy Code
Copy Code wchar_t wch = L'1'; wchar_t* wsz = L"Hello";
How characters are stored in memory
Single-byte strings are stored one character after the next, with a single zero byte marking the end of the string. So for example, "Bob" is stored as:
The Unicode version, L"Bob", is stored as:
|
42 00
|
6F 00
|
62 00
|
00 00
|
|
B
|
o
|
b
|
EOS
|
with the character 0x0000 (the Unicode encoding of zero) marking the end.
DBCS strings look like SBCS strings at first glance, but we will see later that there are subtleties that make a difference when using string manipulating functions and traversing through the string with a pointer. The string " " ("nihongo") is stored as follows (with lead bytes and trail bytes indicated by LB and TB respectively):
" ("nihongo") is stored as follows (with lead bytes and trail bytes indicated by LB and TB respectively):
|
93 FA
|
96 7B
|
8C EA
|
00
|
|
LB TB
|
LB TB
|
LB TB
|
EOS
|
|

|

|

|
EOS
|
Keep in mind that the value of "ni" is not interpreted as the WORD value 0xFA93. The two values 93 and FA, in that order, together encode the character "ni". (So on a big-endian CPU, the bytes would still be in the order shown above.)
Using string handling functions
We've all seen the C string functions like strcpy(), sprintf(), atol(), etc. These functions must be used only with single-byte strings. The standard library also has versions for use with only Unicode strings, such as wcscpy(), swprintf(), _wtol().
Microsoft also added versions to their CRT (C runtime library) that operate on DBCS strings. The strxxx() functions have corresponding DBCS versions named _mbsxxx(). If you ever expect to encounter DBCS strings (and you will if your software is ever installed on Japanese, Chinese, or other language that uses DBCS), you should always use the _mbsxxx() functions, since they also accept SBCS strings. (A DBCS string might contain only one-byte characters, so that's why _mbsxxx() functions work with SBCS strings too.)
Let's look at a typical string to illustrate the need for the different versions of the string handling functions. Going back to our Unicode string L"Bob":
|
42 00
|
6F 00
|
62 00
|
00 00
|
|
B
|
o
|
b
|
EOS
|
Because x86 CPUs are little-endian, the value 0x0042 is stored in memory as 42 00. Can you see the problem here if this string were passed to strlen()? It would see the first byte 42, then 00, which to it means "end of the string," and it would return 1. The converse situation, passing "Bob" to wcslen(), is even worse. wcslen() would first see 0x6F42, then 0x0062, and then keep on reading past the end of your buffer until it happened to hit a 00 00 sequence or cause a GPF.
So we've covered the usage of strxxx() versus wcsxxx(). What about strxxx() versus _mbsxxx()? The difference there is extremely important, and has to do with the proper way of traversing through DBCS strings. I will cover traversing strings next, then return to the subject of strxxx() versus _mbsxxx().
Traversing and indexing into strings properly
Since most of us grew up using SBCS strings, we're used to using the ++ and -- operators on a pointer to traverse through a string. We've also used array notation to access any character in the string. Both these methods work perfectly well with SBCS and Unicode strings, because all characters are the same length and the compiler can properly return the character we're asking for.
However, you must break those habits for your code to work properly when it encounters DBCS strings. There are two rules for traversing through a DBCS string using a pointer. Breaking these rules will cause almost all of your DBCS-related bugs.
1. Don't traverse forwards with ++ unless you check for lead bytes along the way.
2. Never traverse backwards using --.
I'll illustrate rule 2 first, since it's easy to find a non-contrived example of code that breaks it. Say you have a program that stores a config file in its own directory, and you keep the install directory in the registry. At runtime, you read the install directory, tack on the config filename, and try to read it. So if you install to C:\Program Files\MyCoolApp, the filename that gets constructed is C:\Program Files\MyCoolApp\config.bin, and it works perfectly when you test it.
Now, imagine this is your code that constructs the filename:
Collapse Copy Code
bool GetConfigFileName ( char* pszName, size_t nBuffSize )
{
char szConfigFilename[MAX_PATH];
char* pLastChar = strchr ( szConfigFilename, '\0' );
pLastChar--;
if ( *pLastChar != '\\' )
strcat ( szConfigFilename, "\\" );
// Add on the name of the config file.
strcat ( szConfigFilename, "config.bin" );
// If the caller's buffer is big enough, return the filename.
if ( strlen ( szConfigFilename ) >= nBuffSize )
return false;
else
{
strcpy ( pszName, szConfigFilename );
return true;
}
}
This is very defensive code, yet it will break with particular DBCS characters. To see why, suppose a Japanese user gets hold of your program and changes the install directory to C:\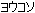 . Here is that directory name as stored in memory:
. Here is that directory name as stored in memory:
|
43
|
3A
|
5C
|
83 88
|
83 45
|
83 52
|
83 5C
|
00
|
|
|
|
|
LB TB
|
LB TB
|
LB TB
|
LB TB
|
|
|
C
|
:
|
\
|

|
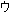
|

|
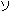
|
EOS
|
When GetConfigFileName() checks for the trailing backslash, it looks at the last non-zero byte of the install directory, sees that it equals '\\', and doesn't append another slash. The result is that the code returns the wrong filename.
So what went wrong? Look at the two bytes above highlighted in blue. The value of the backslash character is 0x5C. The value of '' is 83 5C. (The light bulb should be going on just about now...) The above code mistakenly read a trail byte and treated it as a character of its own.
The correct way to traverse backwards is to use functions that are aware of DBCS characters and move the pointer the correct number of bytes. Here is the correct code, with the pointer movement shown in red:
Collapse Copy Code
bool FixedGetConfigFileName ( char* pszName, size_t nBuffSize )
{
char szConfigFilename[MAX_PATH];
char* pLastChar = _mbschr ( szConfigFilename, '\0' );
pLastChar = CharPrev ( szConfigFilename, pLastChar );
if ( *pLastChar != '\\' )
_mbscat ( szConfigFilename, "\\" );
// Add on the name of the config file.
_mbscat ( szConfigFilename, "config.bin" );
// If the caller's buffer is big enough, return the filename.
if ( _mbslen ( szInstallDir ) >= nBuffSize )
return false;
else
{
_mbscpy ( pszName, szConfigFilename );
return true;
}
}
This fixed function uses the CharPrev() API to move pLastChar back one character, which might be two bytes long if the string ends in a double-byte character. In this version, the if condition works properly, since a lead byte will never equal 0x5C.
You can probably imagine a way to break rule 1 now. For example, you might validate a filename entered by the user by looking for multiple occurrences of the character ':'. If you use ++ to traverse the string instead of CharNext(), you may incorrectly generate errors if there happen to be trail bytes whose values equal that of ':'.
Related to rule 2 is this one about using array indexes:
2a. Never calculate an index into a string using subtraction.
Code that breaks this rule is very similar to code that breaks rule 2. For example, if pLastChar were set this way:
Collapse Copy Code
char* pLastChar = &szConfigFilename [strlen(szConfigFilename) - 1];
it would break in exactly the same situations, because subtracting 1 in the index expression is equivalent to moving backwards 1 byte, which breaks rule 2.
Back to strxxx() versus _mbsxxx()
It should be clear now why the _mbsxxx() functions are necessary. The strxxx() functions know nothing of DBCS characters, while _mbsxxx() do. If you called strrchr("C:\\", '\\') the return value would be wrong, whereas _mbsrchr() will recognize the double-byte characters at the end, and return a pointer to the last actual backslash.
One final point about string functions: the strxxx() and _mbsxxx() functions that take or return a length return the length in chars. So if a string contains three double-byte characters, _mbslen() will return 6. The Unicode functions return lengths in wchar_ts, so for example, wcslen(L"Bob") returns 3.
MBCS and Unicode in the Win32 API
The two sets of APIs
Although you might never have noticed, every API and message in Win32 that deals with strings has two versions. One version accepts MCBS strings, and the other Unicode strings. For example, there is no API called SetWindowText(); instead, there are SetWindowTextA() and SetWindowTextW(). The A suffix (for ANSI) indicates the MBCS function, while the W suffix (for wide) indicates the Unicode version.
When you build a Windows program, you can elect to use either the MBCS or Unicode APIs. If you've used the VC AppWizards and never touched the preprocessor settings, you've been using the MBCS versions all along. So how is it that we can write "SetWindowText" when there isn't an API by that name? The winuser.h header file contains some #defines, like this:
Collapse Copy Code
BOOL WINAPI SetWindowTextA ( HWND hWnd, LPCSTR lpString );
BOOL WINAPI SetWindowTextW ( HWND hWnd, LPCWSTR lpString );
#ifdef UNICODE
#define SetWindowText SetWindowTextW
#else
#define SetWindowText SetWindowTextA
#endif
When building for the MBCS APIs, UNICODE is not defined, so the preprocessor sees:
Collapse Copy Code
#define SetWindowText SetWindowTextA
and replaces calls to SetWindowText() with calls to the real API, SetWindowTextA(). (Note that you can, if you wanted to, call SetWindowTextA() or SetWindowTextW() directly, although you'd rarely need to do that.)
So, if you want to switch to using the Unicode APIs by default, you can go to the preprocessor settings and remove the _MBCS symbol from the list of predefined symbols, and add UNICODE and _UNICODE. (You should define both, as different headers use different symbols.) However, you will run into a snag if you've been using plain char for your strings. Consider this code:
Collapse Copy Code
HWND hwnd = GetSomeWindowHandle();
char szNewText[] = "we love Bob!";
SetWindowText ( hwnd, szNewText );
After the compiler replaces "SetWindowText" with "SetWindowTextW", the code becomes:
Collapse Copy Code
HWND hwnd = GetSomeWindowHandle();
char szNewText[] = "we love Bob!";
SetWindowTextW ( hwnd, szNewText );
See the problem here? We're passing a single-byte string to a function that takes a Unicode string. The first solution to this problem is to use #ifdefs around the definition of the string variable:
Collapse Copy Code
HWND hwnd = GetSomeWindowHandle();
#ifdef UNICODE
wchar_t szNewText[] = L"we love Bob!";
#else
char szNewText[] = "we love Bob!";
#endif
SetWindowText ( hwnd, szNewText );
You can probably imagine the headache you'd get having to do that around every string in your code. The solution to this is the TCHAR.
TCHAR to the rescue!
TCHAR is a character type that lets you use the same codebase for both MBCS and Unicode builds, without putting messy #defines all over your code. A definition of the TCHAR looks like this:
Collapse Copy Code
#ifdef UNICODE
typedef wchar_t TCHAR;
#else
typedef char TCHAR;
#endif
So a TCHAR is a char in MBCS builds, and a wchar_t in Unicode builds. There is also a macro _T() to deal with the L prefix needed for Unicode string literals:
Collapse Copy Code
#ifdef UNICODE
#define _T(x) L##x
#else
#define _T(x) x
#endif
The ## is a preprocessor operator that pastes the two arguments together. Whenever you have a string literal in your code, use the _T macro on it, and it will have the L prefix added on when you do a Unicode build.
Collapse Copy Code
TCHAR szNewText[] = _T("we love Bob!");
Just as there are macros to hide the SetWindowTextA/W details, there are also macros that you can use in place of the strxxx() and _mbsxxx() string functions. For example, you can use the _tcsrchr macro in place of strrchr() or _mbsrchr() or wcsrchr(). _tcsrchr expands to the right function based on whether you have the _MBCS or UNICODE symbol defined, just like SetWindowText does.
It's not just the strxxx() functions that have TCHAR macros. There are also, for example, _stprintf (replaces sprintf() and swprintf()) and _tfopen (replaces fopen() and _wfopen()). The full list of macros is in MSDN under the title "Generic-Text Routine Mappings."
String and TCHAR typedefs
Since the Win32 API documentation lists functions by their common names (for example, "SetWindowText"), all strings are given in terms of TCHARs. (The exception to this is Unicode-only APIs introduced in XP.) Here are the commonly-used typedefs that you will see in MSDN:
|
type
|
Meaning in MBCS builds
|
Meaning in Unicode builds
|
|
WCHAR
|
wchar_t
|
wchar_t
|
|
LPSTR
|
zero-terminated string of char (char*)
|
zero-terminated string of char (char*)
|
|
LPCSTR
|
constant zero-terminated string of char (const char*)
|
constant zero-terminated string of char (const char*)
|
|
LPWSTR
|
zero-terminated Unicode string (wchar_t*)
|
zero-terminated Unicode string (wchar_t*)
|
|
LPCWSTR
|
constant zero-terminated Unicode string (const wchar_t*)
|
constant zero-terminated Unicode string (const wchar_t*)
|
|
TCHAR
|
char
|
wchar_t
|
|
LPTSTR
|
zero-terminated string of TCHAR (TCHAR*)
|
zero-terminated string of TCHAR (TCHAR*)
|
|
LPCTSTR
|
constant zero-terminated string of TCHAR (const TCHAR*)
|
constant zero-terminated string of TCHAR (const TCHAR*)
|
When to use TCHAR and Unicode
So, after all this, you're probably wondering, "So why would I use Unicode? I've gotten by with plain chars for years." There are three cases where a Unicode build is beneficial:
- Your program will run only on Windows NT.
- Your program needs to handle filenames longer than
MAX_PATH characters.
- Your program uses some newer APIs introduced with Windows XP that do not have the separate A/W versions.
The vast majority of Unicode APIs are not implemented on Windows 9x, so if you intend your program to be run on 9x, you'll have to stick with the MBCS APIs. (There is a relatively new library from Microsoft called the Microsoft Layer for Unicode that lets you use Unicode on 9x, however I have not tried it myself yet, so I can't comment on how well it works.) However, since NT uses Unicode for everything internally, you will speed up your program by using the Unicode APIs. Every time you pass a string to an MBCS API, the operating system converts the string to Unicode and calls the corresponding Unicode API. If a string is returned, the OS has to convert the string back. While this conversion process is (hopefully) highly optimized to make as little impact as possible, it is still a speed penalty that is avoidable.
NT allows very long filenames (longer than the normal limit of MAX_PATH characters, which is 260) but only if you use the Unicode APIs. Once nice side benefit of using the Unicode APIs is that your program will automatically handle any language that the user enters. So a user could enter a filename using English, Chinese, and Japanese all together, and you wouldn't need any special code to deal with it; they all appear as Unicode characters to you.
Finally, with the end of the Windows 9x line, MS seems to be doing away with the MBCS APIs. For example, the SetWindowTheme() API, which takes two string parameters, only has a Unicode version. Using a Unicode build will simplify string handling as you won't have to convert from MBCS to Unicode and back.
And even if you don't go with Unicode builds now, you should definitely always use TCHAR and the associated macros. Not only will that go a long way to making your code DBCS-safe, but if you decide to make a Unicode build in the future, you'll just need to change a preprocessor setting to do it!