| |
常用链接
留言簿(1)
随笔分类
随笔档案
文章分类
文章档案
相册
搜索
最新评论

Powered by: 博客园
模板提供:沪江博客
|
|
|
|
|
发新文章 |
|
 | |
近些天来复习软考,看操作系统时又看到《操作系统:设计与实现》这本书,上学期看的时候由于日语二级,一直没有自己仔细研究,现在有些时间,顺便总结一下。
书上关于文件系统各个方面的介绍基本已经很完备了,然而我总感觉有点不足:不能从整体上理解文件系统。怎么从整体上理解文件系统呢?个人感觉应该象一个机器一样,能够在大脑勾画出它的大致的框架,再以一些基本的操作为例,观察一下它工作的流程。本文便由此着手,将MINIX文件系统给大家展示一下。
文件系统说白了就是外存的管理。操作系统有进程管理,内存管理,I/O管理,当然外存管理也必不可少,那么文件系统到底是个什么样子呢,请看下面这张图:
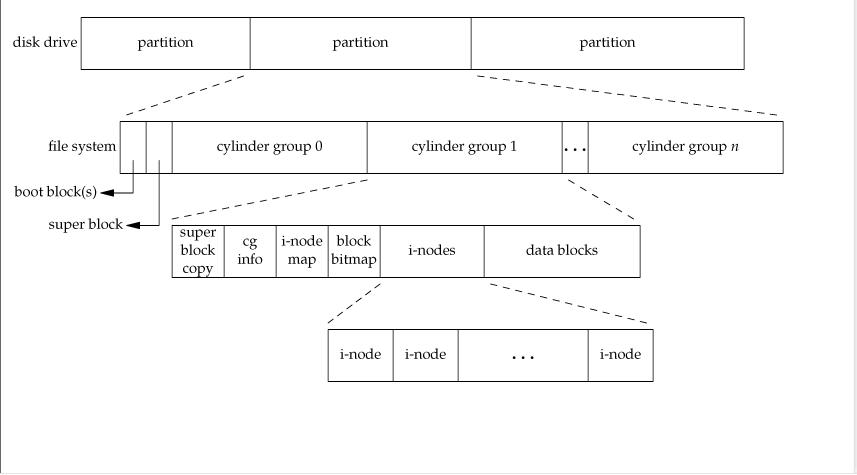
第一层,一个磁盘包含了几个分区(partition),每一个分区就代表一个文件系统(file system),就像我们刚买时电脑分区一样,比如我的电脑就分了四个区:C盘,D盘,E盘和G盘,那么我的电脑就包含了四个文件系统。而每个分区又包含了很多柱面(cylinder group)。关于硬盘的详细介绍请看这里。
第二层往下(包含第二层)这个图就是所呈现的文件系统的概述。从左至友,引导块,超块,然后是柱面,柱面里又有i结点位图,块位图,i结点数组,数据区等等。
引导块里面是电脑启动时用到的信息,下面直接抄书:
 Each file system begins with a boot block. This contains executable code. The size of a boot block is always 1024 bytes (two disk sectors), even though MINIX 3 may (and by default does) use a larger block size elsewhere. When the computer is turned on, the hardware reads the boot block from the boot device into memory, jumps to it, and begins executing its code. The boot block code begins the process of loading the operating system itself. Once the system has been booted, the boot block is not used any more. Not every disk drive can be used as a boot device, but to keep the structure uniform, every block device has a block reserved for boot block code. At worst this strategy wastes one block.To prevent the hardware from trying to boot an unbootable device, a magic number is placed at a known location in the boot block when and only when the executable code is written to the device. When booting from a device, the hardware (actually, the BIOS code) will refuse to attempt to load from a device lacking the magic number. Doing this prevents inadvertently using garbage as a boot program. Each file system begins with a boot block. This contains executable code. The size of a boot block is always 1024 bytes (two disk sectors), even though MINIX 3 may (and by default does) use a larger block size elsewhere. When the computer is turned on, the hardware reads the boot block from the boot device into memory, jumps to it, and begins executing its code. The boot block code begins the process of loading the operating system itself. Once the system has been booted, the boot block is not used any more. Not every disk drive can be used as a boot device, but to keep the structure uniform, every block device has a block reserved for boot block code. At worst this strategy wastes one block.To prevent the hardware from trying to boot an unbootable device, a magic number is placed at a known location in the boot block when and only when the executable code is written to the device. When booting from a device, the hardware (actually, the BIOS code) will refuse to attempt to load from a device lacking the magic number. Doing this prevents inadvertently using garbage as a boot program.
超块是比较重要的一个块,里面装入了文件系统的布局信息,它的主要功能是给出文件系统不同部分的大小。
The main function of the superblock is to tell the file system how big the various pieces of the file system are. Given the block size and the number of i-nodes, it is easy to calculate the size of the i-node bitmap and the number of blocks of inodes. For example, for a 1-KB block, each block of the bitmap has 1024 bytes (8192 bits), and thus can keep track of the status of up to 8192 i-nodes. (Actually the first block can handle only up to 8191 i-nodes, since there is no 0th i-node, but it is given a bit in the bitmap, anyway). For 10,000 i-nodes, two bitmap blocks are needed. Since i-nodes each occupy 64 bytes, a 1-KB block holds up to 16 i-nodes. With 64 i-nodes, four disk blocks are needed to contain them all.
为了防止本文成为国内大多数填鸭式文章(一味填充资料)的样子,这里我就不给出超块的详细图了,考虑到我们只是从整体上了解一下文件系统,并不深究其里,感兴趣的朋友可以下载《操作系统:设计与实现》这本书,上面讲的很清楚,另外,本文引用的那样e文也可略过。
i结点位图,块位图跟踪i结点和块的使用情况,比如创建文件时会看i结点位图哪位是0,创建后会把这一位置1。块位图也是如此管理存储区。然而实际上超块的内存副本里包含了指向了第一空闲的i结点位和第一个空闲区的指针,从而消除了查找时的麻烦,另外删除文件时,也要重新修改这个指针。
然后就是i结点数组和数据区,看下面这张图 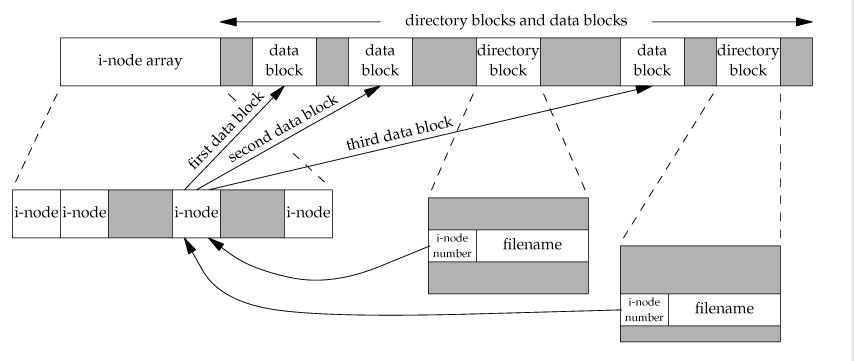
从哪开始看呢,不如自上而下,先从目录看起(图中directory block),在MINIX中每个目录项由文件名和i结点编号组成,看目录的各种实现见书上,i结点内包含了文件的大多数信息(访问权限,文件长度,等等)。当我们打开文件时,首先在目录内找到文件名,进而可以根据i结点号连接到相应的i结点。i结点最后三个域又可以指向数据区。再来张i结点图:
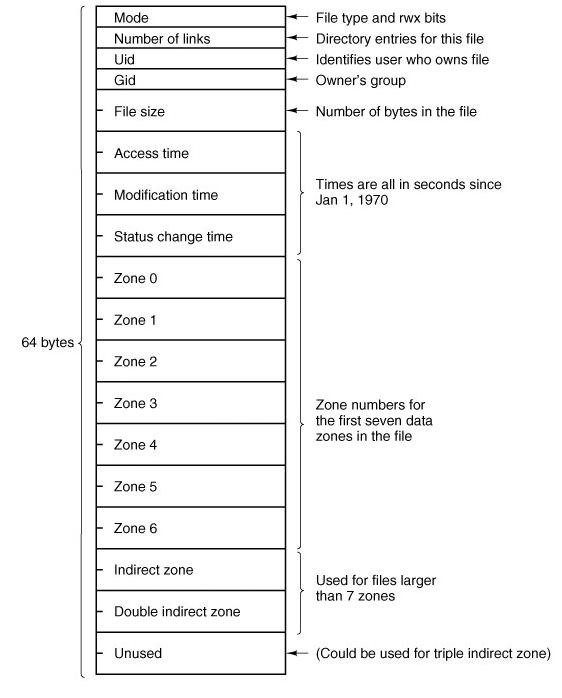 。 。
静态的文件系统的组成就大致如此了。再来看动态的,先来看一下文件系统工作时需要的数据结构:
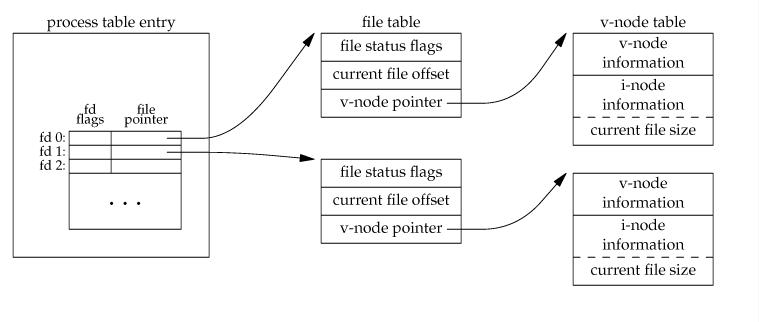
我们知道进程表一共由内核,内存管理器和文件系统管理器来维护(书中第一章)。进程表里面包含了打开的文件描述字,引用计数等一些信息。每个项对应于i结点表中的一项(内存中包含了关于文件系统的三个表,如上图)。恩?中间那个file table是干什么的,为什么会出现这个呢?看下面这个。大意就是说由于子进程需要和父进程的文件偏移位同步,放在进程表和i结点内都不行,所以多搞了个表:
 
5.6.7. File Descriptors
Once a file has been opened, a file descriptor is returned to the user process for use in subsequent read and write calls. In this section we will look at how file descriptors are managed within the file system.
Like the kernel and the process manager, the file system maintains part of the process table within its address space. Three of its fields are of particular interest. The first two are pointers to the i-nodes for the root directory and the working directory. Path searches, such as that of Fig. 5-16, always begin at one or the other, depending on whether the path is absolute or relative. These pointers are changed by the chroot and chdir system calls to point to the new root or new working directory, respectively.
--------------------------------------------------------------------------------
[Page 562]
The third interesting field in the process table is an array indexed by file descripttor number. It is used to locate the proper file when a file descriptor is presented. At first glance, it might seem sufficient to have the k-th entry in this array just point to the i-node for the file belonging to file descriptor k. After all, the i-node is fetched into memory when the file is opened and kept there until it is closed, so it is sure to be available.
Unfortunately, this simple plan fails because files can be shared in subtle ways in MINIX 3 (as well as in UNIX). The trouble arises because associated with each file is a 32-bit number that indicates the next byte to be read or written. It is this number, called the file position, that is changed by the lseek system call. The problem can be stated easily: "Where should the file pointer be stored?"
The first possibility is to put it in the i-node. Unfortunately, if two or more processes have the same file open at the same time, they must all have their own file pointers, since it would hardly do to have an lseek by one process affect the next read of a different process. Conclusion: the file position cannot go in the inode.
What about putting it in the process table? Why not have a second array, paralleling the file descriptor array, giving the current position of each file? This idea does not work either, but the reasoning is more subtle. Basically, the trouble comes from the semantics of the fork system call. When a process forks, both the parent and the child are required to share a single pointer giving the current position of each open file.
To better understand the problem, consider the case of a shell script whose output has been redirected to a file. When the shell forks off the first program, its file position for standard output is 0. This position is then inherited by the child, which writes, say, 1 KB of output. When the child terminates, the shared file position must now be 1024.
Now the shell reads some more of the shell script and forks off another child. It is essential that the second child inherit a file position of 1024 from the shell, so it will begin writing at the place where the first program left off. If the shell did not share the file position with its children, the second program would overwrite the output from the first one, instead of appending to it.
As a result, it is not possible to put the file position in the process table. It really must be shared. The solution used in UNIX and MINIX 3 is to introduce a new, shared table, filp, which contains all the file positions. Its use is illustrated in Fig. 5-39. By having the file position truly shared, the semantics of fork can be implemented correctly, and shell scripts work properly.
Although the only thing that the filp table really must contain is the shared file position, it is convenient to put the i-node pointer there, too. In this way, all that the file descriptor array in the process table contains is a pointer to a filp entry. The filp entry also contains the file mode (permission bits), some flags indicating whether the file was opened in a special mode, and a count of the number of processes using it, so the file system can tell when the last process using the entry has terminated, in order to reclaim the slot.
下面,好戏开始了: 开始动态的看看文件系统的工作过程,MINIX文件系统工作一般都是基于这么一个过程:用户调用一个系统函数,然后就创建一条消息,包含了相应的参数。这条消息然后被送到文件系统,并阻塞以等待文件系统的响应。文件系统在接收到消息后,以消息类型为索引查找过程表,并调用相应的过程处理请求。
比如打开文件的操作,文件系统从消息中提取相应的信息,比如绝对路径,然后它就根据目录进行查找(关于目录的查找,本文没有涉及,也参考书吧)。从目录中找到相应的i结点号(图2),然后得到相应的i结点,并把它载入内存的i节点表中。直到文件关闭前,它一直在内存的i结点表内。然后可以根据i结点的指针就可以得到数据了,加载到内存就行了。内存中的每个i结点还有一个计数器,当文件多次打开时,在内存中只保留一个i结点的副本,但是每次打开文件时,计数器加1,每次关闭该文件时,计数器减1。只有计数器为0时,才将它从i结点表中删除。。注意不要将这个计数器和硬盘上的i结点的计数器相混,那个i结点的引用计数为0时(没有目录指向该i结点),文件才从磁盘上删除。。
另外引用书中讲的一个read的调用来结束本文,这段e文还是很值得一读的,我就不自己敲了:
5.6.10. An Example: The READ System Call
As we shall see shortly, most of the code of the file system is devoted to carrying out system calls. Therefore, it is appropriate that we conclude this overview with a brief sketch of how the most important call, read, works.
When a user program executes the statement
n = read(fd, buffer, nbytes);
to read an ordinary file, the library procedure read is called with three parameters. It builds a message containing these parameters, along with the code for read as the message type, sends the message to the file system, and blocks waiting for the reply. When the message arrives, the file system uses the message type as an index into its tables to call the procedure that handles reading.
This procedure extracts the file descriptor from the message and uses it to locate the filp entry and then the i-node for the file to be read (see Fig. 5-39). The request is then broken up into pieces such that each piece fits within a block. For example, if the current file position is 600 and 1024 bytes have been requested, the request is split into two parts, for 600 to 1023, and for 1024 to 1623 (assuming 1-KB blocks).
For each of these pieces in turn, a check is made to see if the relevant block is in the cache. If the block is not present, the file system picks the least recently used buffer not currently in use and claims it, sending a message to the disk device driver to rewrite it if it is dirty. Then the disk driver is asked to fetch the block to be read.
--------------------------------------------------------------------------------
[Page 566]
Once the block is in the cache, the file system sends a message to the system task asking it to copy the data to the appropriate place in the user's buffer (i.e., bytes 600 to 1023 to the start of the buffer, and bytes 1024 to 1623 to offset 424 within the buffer). After the copy has been done, the file system sends a reply message to the user specifying how many bytes have been copied.
When the reply comes back to the user, the library function read extracts the reply code and returns it as the function value to the caller.
One extra step is not really part of the read call itself. After the file system completes a read and sends a reply, it initiates reading additional blocks, provided that the read is from a block device and certain other conditions are met. Since sequential file reads are common, it is reasonable to expect that the next blocks in a file will be requested in the next read request, and this makes it likely that the desired block will already be in the cache when it is needed. The number of blocks requested depends upon the size of the block cache; as many as 32 additional blocks may be requested. The device driver does not necessarily return this many blocks, and if at least one block is returned a request is considered successful.

|
|