每个分支节点的第一个字段是到以其为根的subtrie中元素(译注:应该是指子节点)的引用.我们可以用被引用的元素的首字符的索引代替元素引用.图3展示了替换后的树.我们将会用这种修改后的形式作为后缀树的表示.
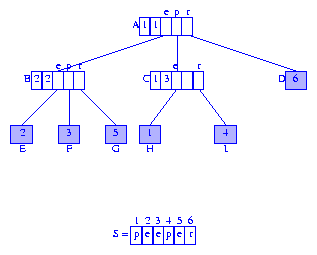
Figure 3 Suffix tree for peeper
如果后缀树的每条边用从分支节点到其子节点的字符(串)标注,可以更容易描述后缀树的查找和构建算法.标签的第一个字符用来确定要移到哪一个子节点,剩余的字符表示要跳过的字符(串).图4展示的就是图3用这种方式画出后得到的后缀树.
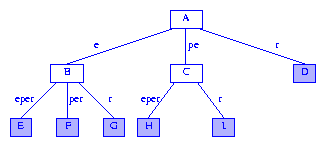
Figure 4 A more humane drawing of a suffix tree
在后缀树的更直观的画法中,从任意根节点到信息节点的路径上所有边的标签拼接在一起得到的就是信息节点表示的后缀.When the digit number for the root is not 1, the humane drawing of a suffix tree includes a head node with an edge to the former root. This edge is labeled with the digits that are skipped over.
后缀树的某个节点表示的字符串是由根节点到此节点的路径上的标签拼出来的.图4中的节点A表示空串epsilon,节点C表示字符串pe,节点F表示字符串eper.
由于后缀树的关键字长度不同,我们必须保证没有一个关键字是另一个的真前缀(proper prefix).当字符串S的最后一个字符在S中只出现一次,就不会出现S的其中一个后缀是另一个后缀的真前缀的情况.在字符串peeper中,最后的字符是r,并且只出现了一次.因此peeper的后缀中就不会出现真前缀的情况.字符串data的最后字符是a,并且出现了两次.因此,data有两个以a开始的后缀,ata和a.后缀a是ata的真前缀.
当字符串S的最后字符在S中出现多于一次,就必须在S的所有后缀后面附加一个新的字符(比如说#),这样任何一个后缀都不会是其他后缀的前缀.还有一种方法是,我们可以在S后面附加新的字符#,得到新的串$#,然后创建$#的后缀树.这样做之后得到的后缀树比直接在S的每个后缀后面附加#会多一个后缀#.
让我们查找那个子串吧
但是,首先要说明几个术语
用n=|S|表示要创建后缀树的字符串的长度.我们从左到右依次给S的字符编号,最左边的编号为1.S[i]表示S的第i个字符,suffix(i)表示从字符i开始的后缀S[i]...S[n],1<=i<=n.
关于查找
当在S中查找模式P时,用到的一个基本的观察(observation)是P在S中出现当且仅当P是S的某个后缀的前缀.
假设P = P[1]...P[k] = S[i]...S[i+k-1].则P是suffix(i)的前缀.既然suffix(i)在我们的压缩trie树中(也就是后缀树),我们可以利用在压缩trie树中查找关键字前缀的策略来查找P.
让我们在字符串S=peeper中查找模式P=per.假设我们已经为S创建好了后缀树(图4).查找从根结点A开始.因为P[1]=p,我们顺着标签以p开始的边.当顺着此边继续时,我们对边标签的剩余字符和P的后续字符做比较.由于标签的剩余字符跟P的字符相符,我们到达分支C.在到达C的过程中,我们已经使用了P的前两个字符.第三个字符是r,因此我们从节点C顺着以r开始的边继续.由于这条边没有其他字符,因此不需要其他比较,到达信息节点I.这时,P中的字符已经用完了,我们就断定P在S中.由于已经到达信息节点I,我们断定P实际上是S的后缀.在实际的后缀树表示中(而不是如图4这种人性化的表示),信息节点I包含索引4,这告诉我们模式P=per由S=peeper的第4个字符开始(也就是说,P=suffix(4)).更进一步,我们可以得到P在S中只出现一次;如果一个模式在字符串中出现多次,查找会在分支节点中止,而不是信息节点.(译注:例如查找pe,查找在节点C中止,说明它在S中出现了两次--C有两个叶子节点)
现在我们来查找模式P=eeee.还是从根结点开始.由于P的第一个字符是e,我们沿着以e开始的边到达B.下一个字符还是e,因此我们从B开始沿着以e开始的边继续.在沿着这条边向下的过程中,我们需要比较边标签的剩余字符per和P的剩余字符ee.比较第一对字符(p,e)时无法匹配,因此我们断定P不在S中.
假设我们查找模式P=p.从根开始,沿着以p开始的边往下.在向下的过程中,我们比较边的剩余字符(只有字符e)和模式的剩余字符.由于已经到P的结尾,我们断定P是以节点C为根的subtrie的所有关键字的前缀.可以通过遍历以C为根的subtrie、访问subtrie的所有信息节点找到P出现的所有位置。如果只需要P出现的一个位置,可以利用存储在节点C的第一部分的索引。当沿着到节点X的边查找时模式结束,我们就说已到达节点X;查找在节点X结束。
当查找模式P=rope,利用P的第一个字符r到达信息节点D。由于模式还没有结束,我们必须根据D的字符检查P的剩余字符。检查显示P不是D的关键字的前缀,因此P不在S=peeper中。
我们要做的最后一个查找是对模式P=pepe。从图4的根结点开始,我们沿着以p开始的边到达节点C。下一个未检查的字符是p。因此,从C开始,我们希望沿着以p开始的边继续。由于没有满足这个条件的边,我们断定pepe不在peeper中。
Other Nifty Things You Can Do with a Suffix Tree
一旦为字符串S创建好了后缀树,我们就可以在O(|P|)时间内判断S是否包含P。这意味着如果为莎士比亚的戏剧“罗密欧与朱丽叶”的内容创建了后缀树,我们就可以非常快的判断文章中是否存在短语wherefore art thou。事实上,只需话费比较18个字符的时间(模式的长度)。查找时间跟文章的长度无关。
其他可以快速完成的有趣事情:
1.查找模式P的所有出现。这是通过对P查找后缀树实现。如果P至少出现一次,查找会在信息节点或者分支节点中止。当中止于信息节点时,P只出现一次。如果中止于分支节点X,模式出现的所有地方可以通过访问以X为根的subtrie的信息节点来得到。如果我们按照下面的方式,这个访问操作可以在O(n)(n是模式出现的次数)时间内完成。
(a)
将所有的信息节点按照节点所表示的后缀的字典序链起来(这也是从左到右扫描信息节点时遇到这些节点的顺序)。图4的信息节点会按照E,F,G,H,I,D的顺序链接起来。
(b)
在每个分支节点内,保存以此节点为根的subtrie的第一个和最后一个信息节点的引用。图4中节点A,B和C分别保存序对(E,D),(E,G)和(H,I)。我们用序对(firstInformationNode, lastInformationNode)周游以firstInformationNode开始、以lastInformationNode结束的链。这个周游会得到模式P出现的所有位置。注意,当我们在分支节点中保存序对(firstInformationNode, lastInformationNode)时,就不需要再保存到subtrie中的信息节点的引用(也就是字段element)。
2.查找包含模式P的所有字符串。假设我们有一些字符串S1,S2,... Sk,我们想得到所有包含P的字符串。例如,基因库中包含数以万计的字符串,当一个研究员提交一个查询字符串,我们就要报告所有包含此模式的字符串。为了有效的执行这类查询,就需要创建一个包含字符串S1$S2$...$Sk#的所有后缀的压缩trie树(也称为多字符串后缀树),这里的$,#是两个不在字符串S1, S2, ..., Sk中出现的不同字符。在后缀树的每个(分支)结点N中,保存所有的字符串Si的链表,其中Si是以N为根的subtrie中所有的信息节点表示的字符串的开始点位于其中的字符串(译注:真拗口啊,这儿的意思就是对某个信息节点L,如果L表示的字符串从Si的某个位置开始,那就将Si的引用放到L的父辈节点的链表中)。
3.查找S中出现次数至少为m>1次的子串。这个查询可以按照下面的方式在O(|S|)时间内完成:
(a)周游后缀树,对每个分支节点X,保存从根节点到X节点的字符串的长度l和以X为根的subtrie中信息节点的数目m。
(b)周游后缀树,访问信息节点数>=m的分支节点。l最大的分支节点表示的就是出现次数>=m的最长子串。
注意步骤(a)只需要执行一次。完成后,我们可以对需要的任意m执行步骤(b)。另外还要注意,当m=2是,不需要确定subtrie中信息节点的数目。在后缀树中,每个分支节点之后有两个信息节点。
4.查找字符串S和T的最长公共子串。这可以按照下面的方式在O(|S|+|T|)时间内完成:
(a)为S和T创建多字符串后缀树(也就是S$T#的后缀树)
(b)周游后缀树,查找表示的字符串最长,并且以其为根的subtrie的信息节点表示的字符串中,至少有一个从S开始,另一个从T开始的字符串。
注意,有个相关的查找S和T的最长公共子序列的问题用动态规划算法在O(|S|*|T|)时间内完成。
如何创建你自己的后缀树
三个观察(observation)
为了更有效的创建后缀树,我们为每个分支节点添加字段longestProperSuffix。表示非空字符串Y的分支节点的longestProperSuffix字段指向表示Y的最长真后缀的分支节点(Y的最长真后缀通过去掉Y的首字符得到)。根结点的longestProperSuffix未使用。
图5表示的是给图4加上最长真后缀指针后得到(经常将最长真后缀指针简称为后缀指针)。后缀指针用红色箭头表示。节点C表示字符串pe。pe的最长后缀e由节点B表示。因此C的后缀指针指向B。e的最长后缀是空串。由于根结点A表示空串,因此B的后缀指针指向A。
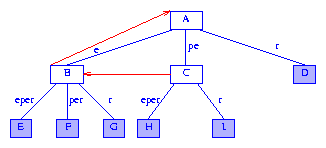
Figure 5 Suffix tree of Figure 4 augmented with suffix pointers
观察1 如果S的后缀树有一个表示字符串Y的分支节点,那么后缀树中也有一个表示Y的最长后缀Z的分支节点。
证明 设P为表示Y的分支节点。由于P是分支节点,至少有两个不同的字符x和y,使得S中有两个分别以Yx和Yy开始的后缀。因此,S有两个分别以Zx和Zy开始的后缀。因此,S的后缀树中必然有一个对应Z的分支节点。
观察2 如果S的后缀树有一个表示Y的分支节点,那么树中对Y的每个后缀都有一个对应的分支节点。
证明 由观察1即可得到。
注意图5中有一个表示pe的分支节点。因此,树中一定有表示e和epsilon的分支节点。
在描述后缀树的创建算法时,有两个概念很有用:last branch node和last branch index。后缀suffix(i)的last branch node是表示suffix(i)的信息节点的父节点。在图5中,suffix(1)...suffix(6)的last branch node分别是C,B,B,C,B和A。对任意后缀suffix(i),其last branch index lastBranchIndex(i)是在suffix(i)的last branch node中,产生分支的字符的索引。在图5中,lastBranchIndex(1)=3,因为:suffix(1)=peeper,suffix(1)由信息节点H表示,H的父节点是C;C的分支是在suffix(1)的第三个字符产生的;suffix(1)的第三个字符是S[3]。可以验证一下,lastBranIndex[1:6] = [3,3,4,6,6,6]。
观察3 在S的后缀树中, lastBranchIndex(i) <= lastBranchIndex(i+1), 1 <= i < n。
证明作为练习。
Get Out That Hammer and Saw, and Start Building
为了创建你自己的后缀树,你必须由你自己的字符串开始。我们使用R = ababbabbaabbabb来阐述后缀树的构建过程。由于R的最后字符b出现了不止一次,我们在R后面附加字符#,为新的字符串S=R#创建后缀树。
创建策略
后缀树的创建算法从表示空串的根结点开始。根结点是一个分支节点。创建后缀树过程的任何时候,都有一个分支节点被指定位活动节点(active node)。这是插入下一个后缀的起始节点。用activeLength表示根结点对应的字符串的长度。开始时,根节点是活动节点,activeLength=0。图6展示了开始时的状态,绿色的节点是活动节点。

Figure 6 Initial configuration for suffix tree construction
随着处理的进行,我们会不断往树中添加分支节点和信息节点。新添加的分支节点用品红色表示,新添加的信息节点用青色表示。后缀指针为红色。
后缀按照suffix(1), suffix(2), ..., suffix(n)的顺序依次插入到树中。后缀以这种顺序插入是通过从左到右扫描字符串S的方氏完成。用tree(i)表示插入后缀suffix(1), ..., suffix(i)之后形成的树,lastBranchIndex(j, i)表示tree(i)中后缀suffix(j)的last branch index。minDistance表示从活动节点到即将插入的后缀的last branch index的距离的下界(译注:感觉这个东西在实现的时候没啥意义)。开始时,minDistance = 0并且lastBranchIndex(1,1) = 1。当插入suffix(i)时,满足条件lastBranchIndex(i,i) >= i + activeLength + minDistance。
为了向tree(i)中插入suffix(i+1),我们必须遵循如下步骤:
1.确定lastBranchIndex(i+1, i+1)。为了完成这点,我们从当前活动节点开始。新后缀的开始的activeLength个字符(也就是字符S[i+1], S[i+2], ..., S[i + activeLength])已知是跟当前活动节点表示的字符串相匹配的。因此,为了确定lastBranchIndex(i+1,i+1),需要检测新后缀的activeLength + 1, activeLength + 2, ...字符。这些字符用于确定tree(i)中进一步处理时要经过的路径,此路径始于活动节点,当lastBranchIndex(i+1,i+1)确定时中止。根据已知的lastBranchIndex(i+1,i+1) >= i + 1 + activeLength + minDistance,这个过程可以简化,从而得到效率提升。
2.如果tree(i)中没有表示字符串S[i]...S[lastBranchIndex(i+1,i+1)-1]的节点X,则创建一个。
3.为suffix(i+1)添加一个信息节点。这个信息节点是X的孩子,从X到信息节点的边上的标签是S[lastBranchIndex(i+1, i+1)]...S[n]。
回到例子
我们从向图6中的树tree(0)插入suffix(1)开始。根结点是活动节点,activeLength = minDistance = 0。suffix(1)的第一个字符是S[1]=a。从tree(0)的活动节点开始没有以a开始的边(事实上,此时活动节点没有任何边)。因此,lastBranchIndex(1,1) = 1。我们创建一个新的信息节点和一条边,边的标签是整个字符串。图7展示了结果tree(1)。根结点依然是活动节点,activeLength和minDistance没有变化。
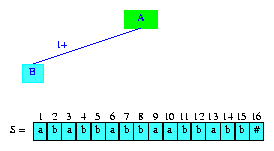
Figure 7 After the insertion of the suffix ababbabbaabbabb#
在我们的画法中,信息节点的入边的标签标记为i+,i表示标签在S中的开始位置,+表示标签一直到字符串的结尾。因此,在图7中,1+表示字符串S[1]...S[n]。图7也展示了字符串S。新插入的后缀用青色表示。
为了插入后缀suffix(2),我们再次从根结点开始检查后缀的activeLength + 1 = 1, activeLength + 2 = 2, ...,字符。因为suffix(2)的第一个字符是S[2]=b,活动节点没有以S[2]=b开始的边,所以lastBranchIndex(2,2) = 2。因此我们创建新的信息节点和标记为2+的边。结果如图8所示。根结点依然是活动节点,activeLength和minDistance依旧没有变化。
Figure 8 After the insertion of the suffix babbabbaabbabb#
注意图8是关于suffix(1)和suffix(2)的压缩trie树tree(2)。
下一个后缀suffix(3)开始于S[3]=a。由于tree(2)的活动节点有一个以a开始的边,所以lastBranchIndex(3,3) > 3。为了确定lastBranchIndex(3,3),必需要查看suffix(3)的更过字符。尤其是,我们需要查看尽可能多的字符,以便区分suffix(1)和suffix(3)。首先比较后缀的第二个字符S[4]=b和边1+的第二个字符S[2]=b。由于S[4]=S[2],必须做进一步的比较。下一步比较S[5]和S[3]。由于这两个字符不同,我们可以确定lastBranchIndex(3,3)是5。这时,我们需要更新minDistance为2.注意,因为lastBranchIndex(3,3) = 5 = 3 + activeLength + minDistance,这是minDistance的最大可能值。
为了插入suffix(3),我们将tree(2)的边1+一分为二。第一条边的标签是1,2;第一条边的标签是3+。这两个边之间插入新的分支节点。另外,还要为新插入的后缀添加信息节点。结果如图9所示。边标签1,2显示为字符S[1]S[2] = ab。
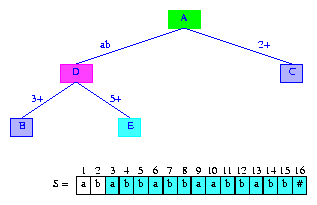
Figure 9 After the insertion of the suffix abbabbaabbabb#
tree(3)还没完成,因为还没有确定新加的分支节点的后缀指针。这个分支节点的最长后缀是b,但是对应b的分支节点不存在。别惊慌,下一个要创建的分支节点就是对应b的节点。
下一个要插入的后缀是suffix(4)。这是刚插入的suffix(3)的最长后缀。新后缀的插入过程由根据当前活动节点的后缀指针确定新的活动节点开始。由于根结点没有后缀指针,活动节点没有变化。因此activeLength也没有变化。但是,我们必须更新minDistance以满足lastBranchIndex(4,4) >= 4 + activeLength + minDistance。显然,对于所有的i<= lastBranchIndex(i+1,i+1)。因此,lastBranchIndex(i+1,i+1) >= lastBranchIndex(i,i) >= i + activeLength + minDistance。为了保证lastBranchIndex(i+1,i+1) >= i + 1 + activeLength + minDistance,我们必须将minDistance减小1.
因为minDistance = 1,我们从活动节点开始,沿着S[4]S[5]...指定的路径记录。我们不需要比较开始的minDistance个字符,因为在minDistance+1之前的字符都已经保证是匹配的了。由于活动节点以S[4]=b开始的边的长度大于1,我们比较S[5]和边的第二个字符S[3]。因为这两个字符不同,这条边也要一分为二。第一条边的标签为2,2=b;第二条棉的标签为3+。在两条边之间添加新的分支节点F,还要为新插入的后缀创建信息节点G。G跟F之间通过标签为5+的边连接。结果如图所示。
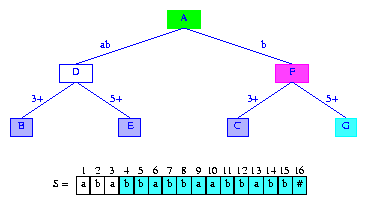
Figure 10 After the insertion of the suffix bbabbaabbabb#
现在我们要为插入后缀suffix(3)时创建的分支节点D设置后缀指针。这个后缀指针就是新创建的分支节点F。
节点F表示的字符串b的最长后缀是空串。因此F的后缀指针指向根结点。图11是添加了后缀指针的结果。
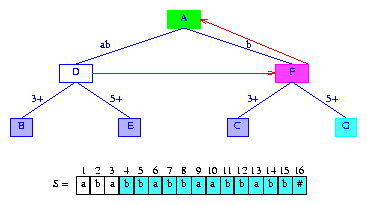
Figure 11 Trie of Figure 10 with suffix pointers added
下一个要插入的是suffix(5)。由于suffix(5)是刚插入的后缀suffix(4)的最长后缀,我们从活动节点的后缀指针开始。但是当前作为活动节点的根结点没有后缀指针。因此,活动节点不变。为了保持lastBranchIndex, activeLength, minDistance以及将插入的后缀的索引(5)之间的关系,需要将minDistance减少1.因此,minDistance变为0.
因为activeLength=0,我们需要从suffix(5)的首字符S[5]开始检查。活动节点有一条以S[5]=b开始的边。我们沿着这条边比较后缀字符和标签字符。由于所有的字符都匹配,我们到达节点F。现在F成为活动节点(在检查后缀字符的过程中,遇到的分支节点都成为新的活动节点),activeLength=1。我们从当前活动节点的某条边开始继续比较。由于下一个要比较的后缀字符是S[6]=a,我们使用以a开始的边(如果这样的边不存在,新后缀的lastBranchIndex是activeLength+1)。这条边的标签是3+。当比较到新后缀的字符S[10]=a和边的字符S[7]=b时,比较结束。因此,lastBranchIndex(5,5) = 10. minDistance设置为允许的最大值,也就是lastBranchIndex(5,5) - (index of suffix to be inserted) - activeLength = 10 - 5 - 1 = 4.。
为了插入suffix(5),我们将节点F和C之间的边分裂为二。分裂出现在边(F,C)的splitDigit=5的字符位置。
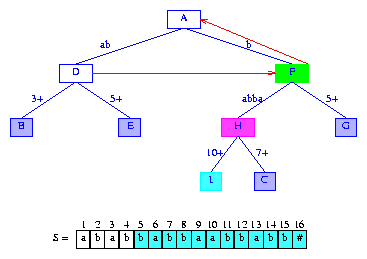
Figure 12 After the insertion of the suffix babbaabbabb#
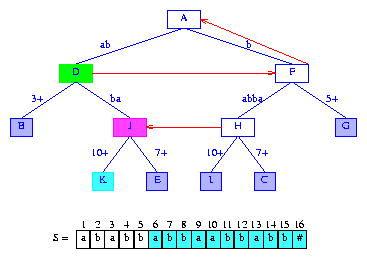
Figure 13 After the insertion of the suffix abbaabbabb#
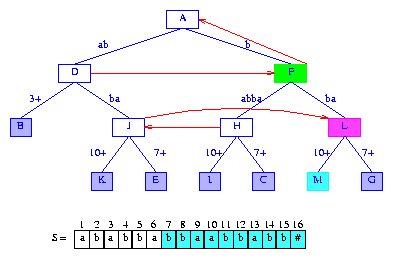
Figure 14 After the insertion of the suffix bbaabbabb#
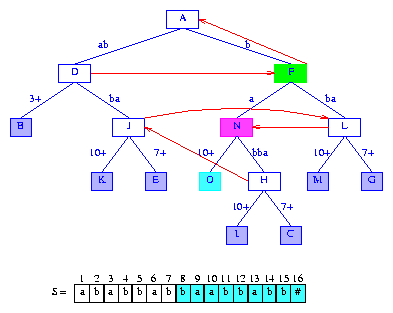
Figure 15 After the insertion of the suffix baabbabb#
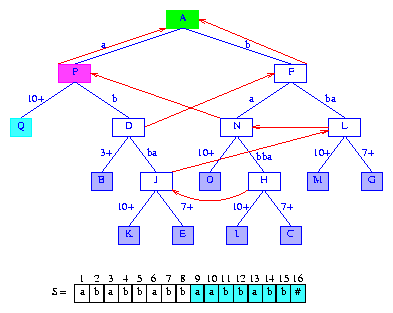
Figure 16 After the insertion of the suffix aabbabb#

Figure 17 After the insertion of the suffix abbabb#
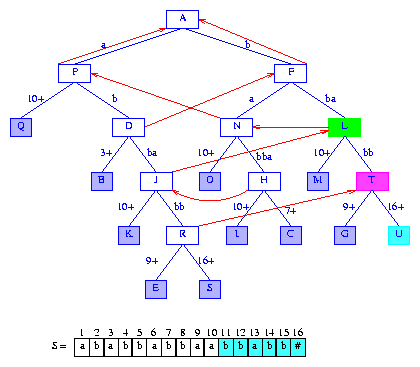
Figure 18 After the insertion of the suffix bbabb#
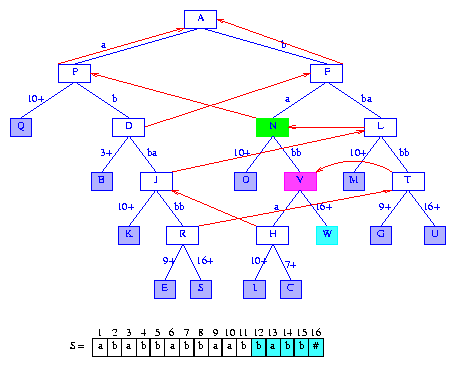
Figure 19 After the insertion of the suffix babb#
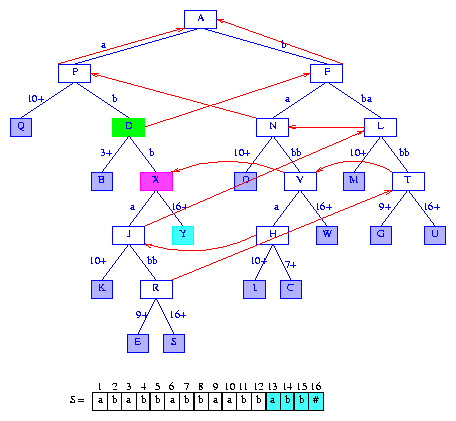
Figure 20 After the insertion of the suffix abb#
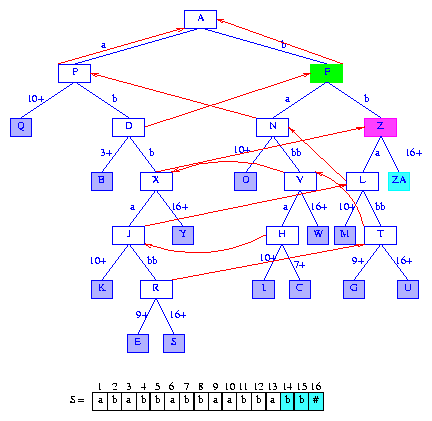
Figure 21 After the insertion of the suffix bb#
复杂度分析用r表示字符串S的字符集的大小,n表示S的长度(也就是后缀的数目)。为了插入suffix(i),我们(a)沿着活动节点的后缀指针(除非活动节点是根结点)。(b)在已创建的后缀树中向下移动,直到经过了minDistance个字符。(c)然后依次比较后缀和边的字符,直到确定了lastBranchIndex(i,i)为止。(d)最后插入新的信息节点和可能的分支节点。(a)部分消耗的总的时间是O(n)(一共有n此插入)(b)
部分中,在后缀树中往下移动时,不需要做比较。每次移动到下级分支节点需要O(1)时间。另外,每次移动都会使minDistance减少1.由于开始时
minDistance为0,并且永远不会小于0,(b)消耗的时间是O(n + n次插入操作中minDistance增加的总数). (c)
部分中,确定lastBranchIndex(i,i) 跟 i + activeLength +
minDistance是否相等需要的时间是O(1)。这只有在minDistance = 0或者位于suffix(i)的activeLength
+ minDistance + 1位置的字符x跟活动节点的合适的边的minDistance +
1位置的字符不同的时候才满足。当lastBranchIndex(i,i) != i + activeLength +
minDistance时,lastBranchIndex(i,i) > i + activeLength +
minDistance,lastBranchIndex(i,i)的值通过对后缀字符和边的字符之间做一系列的比较来确定。每进行一次这种比
较,minDistance加1.本算法中,只有在这种情景下,minDistance才会增加。由于minDistance的每次递增都是S的新的位置
(也就是此位置开始的字符还未比较过的位置)的字符和边的字符相等的情形的结果,因此在n次插入中,minDistance增加的总数是O(n)。每次插入时,(d)消耗的时间是O(r),因为我们需要初始化要创建的分支节点的O(r)个字段。因此步骤(d)消耗的总的时间是O(nr)。因此,创建后缀树消耗的总的时间是O(nr)。如果假定字符集的大小r是常数,算法的复杂度就是O(n)。只有在字符集的大小r很小的情况下,才推荐每个分支节点有r个指向子节点的字段。当字符集很大的时候(可能会跟n一样大,这时上述算法的复杂度是O(n^2)),使用哈希表能够得到O(n)复杂度的算法。空间复杂度有O(nr)变为O(n)。这里有一个分治算法实现的后缀树,时间和空间复杂度都是O(n)(即使字符集的大小是O(n))。
References and Selected Readings
- NIH's Web site for the human genome project
- Department of Energy's Web site for the human genomics project
- Biocomputing Hypertext Coursebook.
Linear
time algorithms to search for a single pattern in a given string can be
found in most algorithm's texts. See, for example, the texts:
- Computer Algorithms, by E. Horowitz, S. Sahni, and S. Rajasekeran, Computer Science Press, New York, 1998.
- Introduction to Algorithms, by T. Cormen, C. Leiserson, and R. Rivest, McGraw-Hill Book Company, New York, 1992.
For more on suffix tree construction, see the papers:
- ``A space economical suffix tree construction algorithm,'' by E. McCreight, Journal of the ACM, 23, 2, 1976, 262-272.
- ``On-line construction of suffix trees,'' by E. Ukkonen, Algorithmica, 14, 3, 1995, 249-260.
- Fast string searching with suffix trees,'' by M. Nelson, Dr. Dobb's Journal, August 1996.
- Optimal suffix tree construction with large alphabets, by M. Farach, IEEE Symposium on the Foundations of Computer Science, 1997.