跟着开源/来学习源C语言代码的读法
http://itpro.nikkeibp.co.jp/article/COLUMN/20070622/275606/
|
まつもと ゆきひろ
(Yukihiro "Matz" Matsumoto)
翻译: Lymons
|
|
「Code Reading―从开源里学习软件开发的技法」有这样一本书。我是这本书日本版的译者, 呵呵有点王婆卖瓜---自卖自夸的感觉,但是把读源代码作为主题的在市面还没有其他的书。我认为这是一本网罗了从技法到工具,数据结构,构架,还有利用代码的实际读法的实例的好书。
|

|
|
照片1●「Code Reading―跟着开源来学习软件的开发技法」
|
这本书的前言里,编程高手Dave Thomas写下了下面的话。
没有研读过其他作家作品的伟大作家,没有研究过其他画家笔法的伟大画家,没有盗取过并肩作战的同事的技术的技巧高明的外科医生,没有在副驾驶的位置积累实际经验的波音767的机长,在现实生活中真的会存在他们这样的人吗?
的确是不存在上面降到的那些人。我们通常说的,在软件开发以外的领域里进行的修炼,也就是去观摩他人的工作,先是去模仿,然后是尽全力的做而后拿出自己的独有特点。在拳术里有句话就叫”守.破.离“。
注:
“守破离“ 就是指:
遵从继承过来的东西
摒弃与现代不合适的东西
加入新的东西,独自专研,而后超越了前人
|
『守(しゅ)』『破(は)』『離(り)』とは 指導者から何かを学び始めてから、ひとり立ちしていくまでに人は、『守』・『破』・『離』という順に段階を進んでいきます。
|
|
『守』
|
最初の段階では、指導者の教えを守っていきます。 できるだけ多くの話を聞き、指導者の行動を見習って、指導者の価値観をも自分のものにしていきます。 学ぶ人は、すべてを習得できたと感じるまでは、指導者の指導の通りの行動をします。 そして、指導者が「疑問に対して自分で考えろ」と言うことが多くなったら、次の段階に移っていきます。
|
|
『破』
|
次の段階では、指導者の教えを守るだけではなく、破る行為をしてみます。 自分独自に工夫して、指導者の教えになかった方法を試してみます。 そして、うまくいけば、自分なりの発展を試みていきます。
|
|
『離』
|
最後の段階では、指導者のもとから離れて、自分自身で学んだ内容を発展させていきます。
|
先去模仿别人这是当然的,但是在IT业界里却不必遵守的一面也有.在商用软件的世界里源代码是一个企业生存的饭碗,外界的人是看不到它们的.商用软件里,这些私有的代码也就是财产,这些代码是无论如何也不能被读到的.软件开发的很多技术,在各个软件公司中都是前辈通过口头教授的方式来传递给后辈.
多亏了开源.软件,我们才能把这些实际的代码看的一清二楚,能够对它们进行学习了.虽然是这样,但是仅仅通过毫无目的地去读代码,并不能让谁都能成为一名优秀的程序员.很遗憾,源代码并不像小说,音乐,电影一样,能够根据人类的感性直接进行运转起来的.源代码是在让人和计算机都能理解的,用编程语言这种稍微特殊的形式来描写出来的.因此,不能像普通小说那样去读它.在有数万行的代码,如果漫无目的地从最开头去读,我想几乎没有人能够去轻而易举地理解其中的内容.但是,因为在源代码中并没有像小说那样的故事,所以没有必要把源代码全部的通读一遍*1.还不如只截取非常有意思的地方,或者有必要的地方,来学习先人的智慧就足够了.
那么,阅读源代码有各种各样的必要的东西,最开始的一个必要的东西恐怕就是目的了吧.根据想要学习什么来阅读源代码,可以富有成效地去理解它,学习到其中的知识. 例如,”学习递归下降语句解析的实现方法”啊,”处理系中垃圾回收机制是如何实现”的啦,”这个处理系为什么运行速度会这么快”等. 把哪些东西学到手作为阅读的目的,是一个在膨胀的代码中要选择阅读那个地方的方针.
读代码的目的,不仅仅是为了学习. 例如, 在软件维护和调试的时候,必须要读懂相关的源代码. 因为工作的原因去维护其他人写的软件的情况并不是一间稀奇的事情. 为了又要改善软件,又要追加功能,又要修正BUG, 必要要对目标的源代码进行阅读和理解. 即使是自己写过的源代码,经过很长的一段时间后它的内容和背景也几乎记不清楚的情况也经常发生. 在软件业里,有”半年前的自己就是别人”的这样一个谚语. 因此, 即使自己写过的软件, 最终自己也有必要去阅读它.
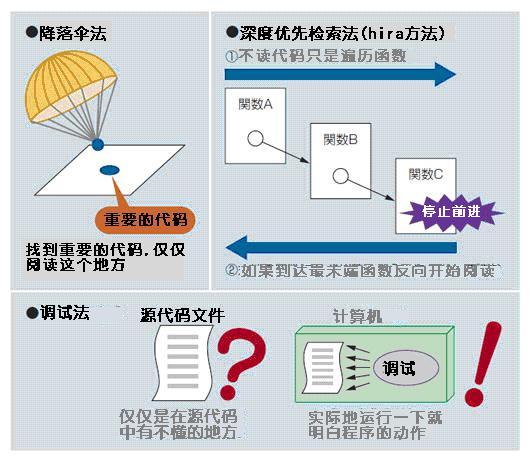
即使完全地了解目的了,胡乱地对源代码瞎读一通也是不能达成目的的. 读代码的测试有好几种, 但是我只给大家介绍我经常使用的那几种(图1)。
|
|
|
图1●阅读源代码的的三种策略
|
●降落伞法
有目的地去阅读源代码的时候, 必须要读完程序的全部代码是非常少见的事情.实际上是, 那些想要知道的知识是代码中被隐藏的部分, 存在BUG的部分, 从全体看来,找到只不过是其中的一小部分而已的地方, 仅仅阅读这部分代码就足够了. 所谓“降落伞法”就是, 找到其中的重要的地方, 仅仅阅读这个地方的源代码的策略. 就像降落伞部队在突袭某个重要据点一样. 降落伞法的本质则是, 要找到哪个部分是重要的. 实际的例子在后面要介绍,但是检索是这里的关键.
●深度优先探索法
极其少见地,想要把握程序的全体流程的情况也是有的. 例如想要把握Linux启动时的控制流程时. 在这个场合, 从程序启动时最开始被执行的main函数开始, 按照深度优先的方式一个一个地去遍历被调用的函数, 一直到不再调用其他的函数的最末端函数为止, 然后是开始反向遍历阅读这个路径上的代码. 利用像这样的自底向上的阅读方式,在”不知道的函数假设它不存在”的状态下能够进行阅读, 能够高效率地去阅读源代码. 为了肯定这个方法的发明人,根据他的名字这种方式也被叫做”hira方法”,实际上,在阅读Linux源代码的时候经常会使用这种方法*2。
●调试法
程序的状态是伴随着运行有这个各种各样的变化. 因此, 虽说读解程序, 但是仅仅通过阅读程序的字面意思并不能理解它的真意. 有时候,阅读者有必要把自己想象成一台计算机来判断变量和对象的状态.
但是, 试着考虑一下, 即使我们不用想象, 计算机最终还是要执行这个程序, 所以如果我们能观察它在执行时候的样子的话, 就能正确的知道运行时候的状态了. 这就是调试(debug). 使用调试的话,能让程序在任意的地点停止,就可以调查这个时侯的变量的状态. 调试就是为了找到BUG而被引入的软件, 但是为了能够知道软件在运行时候的状态, Code.Reading也同样有效.
阅读源代码的时候,必须要得到关键的源代码. 可以利用互联网无限制的得到免费的源代码. 在这里介绍几种开源.软件的获取方法.
●freshmeat 略
●SourceForge 略
●Google 略
●源代码检索
最近,即使不下载全部的源代码,也能登陆即刻检索源代码的Web网站. 有代表的网站如, Koders(http://www.koders.com/,图3)和Google CodeSearch(http://www.google.com/codesearch,图4).
在检索源代码的时候, 必须要注意以下的几点.
●OS 略
●语言 略
●许可证 略
软件的源代码, 大体都有预想以上的规模. 超过600万行的Linux是一个非常极端的例子, 但是, Ruby那样并不是很庞大的软件也超过了10万行. 想这样庞大的规模, 阅读所有的代码是一件不现实的事情. 阅读源代码的时候, 找到掩藏这必要信息的关键场所是非常重要的.
在读解源代码的时候, 首先要理解程序的全体框架是非常有必要的. 程序的所有代码没有必要阅读, 但是, 为了找到自己想要查找的信息在被安放在什么地方, 制作出程序全体的结构图就可以让阅读变得非常方便的.
因此,最有用的是源代码的文件名。大体的软件的源代码都被分成很多的文件.在各个文件被应该命名成跟程序机能相关联的名字. 例如, 想要读取内存管理的源代码的时候, “就可以怀疑memory.c和gc.c这样的文件”就是我们要找的.
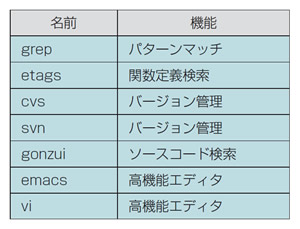
检索源代码的工具也是必不可少的. 这些工具被总结在表2里.
|
|
|
表2●源代码检索必备的工具一览
|
那么让我们找实际的代码试一试阅读它吧.
Code.Reading的实际演练
1:读pom程序
2年前,在生产我的小儿子的时候, 清晨4点就要带着妻子去医院而出了门,正好看见空中美丽的照耀大地的满月. 有那么一说,孩子的分娩与月亮的圆缺有关系. 在UNIX中有pom(phase of the moon)这样一个C语言的程序, 用来表示月亮的圆缺(月龄).
根据列表1可以看出来是满月。 我共有4个孩子, 其他的三个中一个几乎是新月(5%), 一个几乎是满月(98%), 另一个是介于半月和满月之间(62%). 4人里有3人是满月活新月,所以这是非常高的几率哦. 然而, UNIX的pom不能计算1970年以前的月龄。因此,我妻子的月龄也就不能计算.
|
% pom 04102804
Thu 2004 Oct 28 04:00:00 (JST): The Moon was Full
|
|
列表1●表示月龄的软件pom的执行结果
|
在这里读它的源代码吧. 首先, 从找它的源代码开始. 我们试着使用GoogleCodeSearch*5。访问网站http://www.google.com/codesearch后输入查找关键字。如,”phase of the moon pom”这样的词就行. 检索的结果有好几个候补. 找了几个后我想我找到了pom.c的文件.
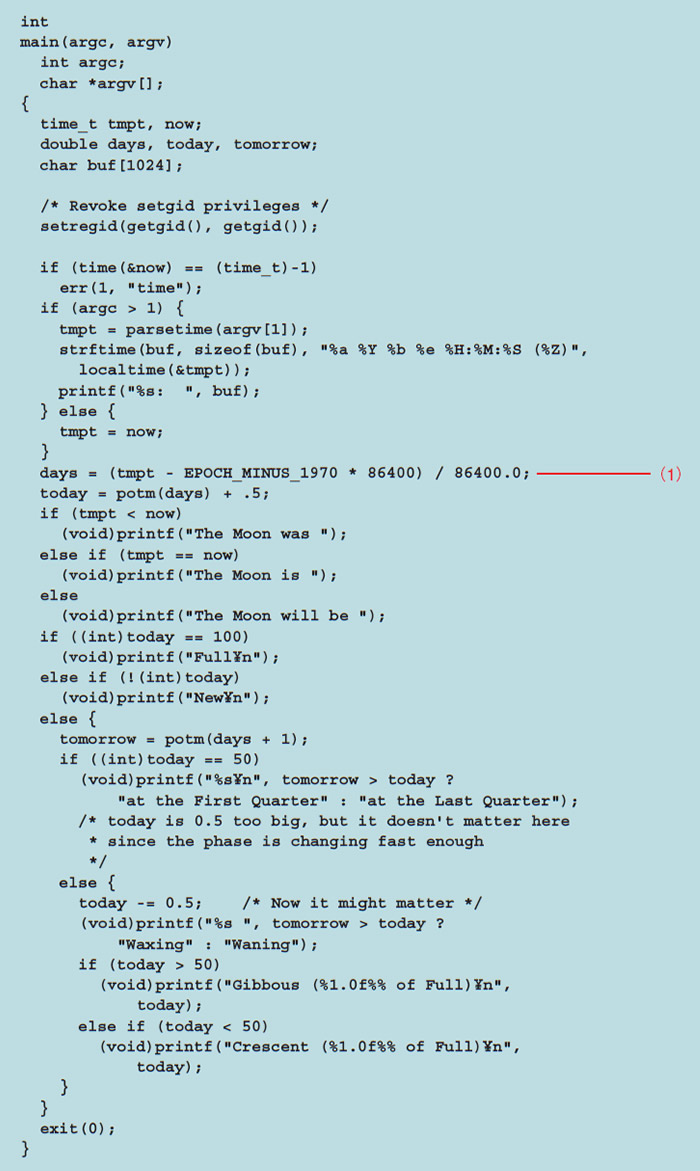
pom.c是一个有286行的小程序。文件头是表示许可证和被包含的头文件的地方,暂且略过. 要了解全体的动作则必须先从main( )函数开始看(列表2)。
|
|
|
列表 2●pom.c的main函数
[点击图像放大]
|
上面能够看到代码的大部分内容(英语的时制,满月/新月等), 也就明白了正在使用的东西。包括, 月龄的计算使用通过potm( )函数来进行的. 叫做days的浮点数被传递到potm( )函数中. Days是从基准点(1989年12月31日)开始的一个日数.
在计算days的那行代码(列表2(1))中,调整了UNIX的时刻(1970年1月1日开始的描述)和被potm( )处理的时刻. 在这里出现的常量86400等于24小时×60分×60秒,也就是1整天的描述. 暂且把potm( )的处理逻辑作为黑盒(black box)先搁置在一边.
我们关心的是”为什么1970年以前的不能计算呢”。在pom程序里一处理1970年以前的日期的话, 会出现 列表3那样的错误消息. 一检索这个消息字符串我们会找到在列表4中表示的代码.
|
pom: specified date is outside allowed range
|
|
列表3●把1970年以前的日期传递到pom中会打印出来的错误消息
|
|
if ((tval = mktime(lt)) == -1)
errx(1, "specified date is outside allowed range");
|
|
列表4●包含列表3中错误消息的代码
|
似乎是因为C的库函数mktime( )不能处理1970年以前的时间的这个理由,pom才不能计算的. 如果是1970年以后的时间,在基准点以前的月龄也能计算, 那就说明potm( )的算法里好像没有对1970年的限制.
|
|
|
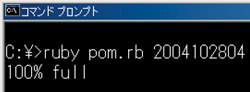
图6●Ruby版本的pom中2004年10月28日4时的月龄的表示结果
|
总而言之,如果不使用mktime()就能计算days的话那当然好了. 但在C中不使用mktime()来计算时间好像很困难. 于是, 试着使用Ruby来实现吧。Ruby的DateTime类对于日期的计算是非常拿手的. 1970年的限制没有了,反而公元前数千年到公元数万年的日期都能轻而易举的计算出来.
列表5是把pom.c的代码翻译成Ruby代码的结果。potm( )函数的算法是原封不动的转换成了Ruby代码. 在main( )中的代码的逻辑在前面已经表示过了所以这里全部都省略掉了,该程序也能用百分比的形式来表示月龄(图6)。
|
# Copyright (c) 1989, # Copyright (c) 1989, 1993
# The Regents of the University of California.
# All rights reserved.
require 'date'
EPOCH_MINUS_1970=(20 * 365 + 5 - 1)
# 20 years, 5 leaps, back 1 day to Jan 0
EPSILONg=279.403303 # solar ecliptic long at EPOCH
RHOg=282.768422 # solar ecliptic long of perigee at EPOCH
ECCEN=0.016713 # solar orbit eccentricity
LZERO=318.351648 # lunar mean long at EPOCH
Pzero=36.340410 # lunar mean long of perigee at EPOCH
Nzero=318.510107 # lunar mean long of node at EPOCH
include Math
def potm(days)
n = 360 * days / 365.242191
n = adj360(n)
msol = n + EPSILONg - RHOg
msol = adj360(msol)
ec = 360 / PI * ECCEN * sin(dtor(msol))
lambdasol = n + ec + EPSILONg
lambdasol = adj360(lambdasol)
l = 13.1763966 * days + LZERO
l = adj360(l);
mm = l - (0.1114041 * days) - Pzero
mm = adj360(mm);
nm = Nzero - (0.0529539 * days)
nm = adj360(nm);
ev = 1.2739 * sin(dtor(2*(l - lambdasol) - mm))
ac = 0.1858 * sin(dtor(msol))
a3 = 0.37 * sin(dtor(msol))
mmprime = mm + ev - ac - a3
ec = 6.2886 * sin(dtor(mmprime))
a4 = 0.214 * sin(dtor(2 * mmprime))
lprime = l + ev + ec - ac + a4
v = 0.6583 * sin(dtor(2 * (lprime - lambdasol)))
ldprime = lprime + v
d = ldprime - lambdasol
return(50.0 * (1 - cos(dtor(d))))
end
def dtor(deg)
deg * Math::PI / 180
end
def adj360(deg)
loop do
if (deg < 0)
deg += 360;
elsif (deg > 360)
deg -= 360;
else
return deg
end
end
end
tmpt = ARGV[0] ? DateTime.parse(ARGV[0]) : DateTime.now
days = tmpt - DateTime.parse("1989-12-31T00:00Z")
printf "%d%% full\n", (potm(days.to_f) + 0.5).to_i
|
|
列表5●pom程序的Ruby版代码
|
用它来计算的话,我家的男性们结果是60%的满月, 而女性们结果几乎都是新月和满月. 虽然就凭我们家里的这么点儿例子也不能说明什么或得出什么结论…
另外,列表5中的程序和原始的pom程序一样按照BSD协议许可来公开.
Code.Reading的实际例子
2:阅读语言的UTF-8处理
在看看别的例子吧。pom例子中的代码规模实在是太小了, 所以这次咱们试一试在大规模的代码中来查找目标代码.
Unicode字符串的编码方式之一就有UTF-8格式. 很少有人知道, 实际上UTF-8并没有限定在Unicode之内. 把任意的31位的整数数列符号化成可变长的字节序列*6 . 図7表示的是它的比特位.模式.
|

|
|
図7●UTF-8比特位.模式
[点击这里放大图像]
|
那么,我们考虑实现一个把1个字符从整数转换成字节序列,或者从字节序列转换成整数的函数。按照图7的比特位.模式,拼了老命好像也能实现这个功能, 但是为了方便期间, 还是参考一下前人写过的代码吧.
作为参考, 只要是实现了处理UTF-8的字符串这个功能, 不管这个程序用什么语言来编制都没有关系.从各方面来考虑,在本文中将对脚本语言的代码进行说明. 因此,我们在这里准备了Perl,Python,Ruby的源代码.
因为想要查找UTF-8关联的机能, 暂且从使用grep命令来检索源代码开始. 首先是看Perl的源代码, 在UTF-8中含有在C语言标识符不能识别的横线, 所以忽略掉它用utf8作为关键字来进行检索. 。使用命令行 “grep -i utf8 *.c”来检索的话, 在utf8.c文件里找到了uvchr_to_utf8_flags( )和utf8n_to_uvchr( )这两个函数. 但是, 一看这个文件的源代码的话, 因为不了解Perl的内部结构它的源代码非常难读(列表6)。在Python中调查了也是同样, 在文件Object/unicodeobject.c中有PyUnicode_EncodeUTF8( )和PyUnicode_DecodeUTF8( )」这两个函数. 虽然不讲它的代码,但是也有必要了解Python的内部结构的相关知识.
|
UV
Perl_utf8n_to_uvchr(pTHX_ U8 *s, STRLEN curlen, STRLEN *retlen, U32 flags)
{
UV uv = Perl_utf8n_to_uvuni(aTHX_ s, curlen, retlen, flags);
return UNI_TO_NATIVE(uv);
}
|
|
列表6●Perl的utf8n_to_uvchr( )函数的源代码片段
|
在最后让我们看看Ruby的代码, 比较好的是在文件pack.c里的函数uv_to_utf8( )とutf8_to_uv( )不依赖于Ruby的内部结构, 可以简单的留用下来作为我们的参考(列表7)*7。
|

|
|
列表7●Ruby里的uv_to_utf8( )和utf8_to_uv( )函数的源代码片段
|
一读这里的实际代码,就能发现UTF-8的定义了。虽然这样, utf8_to_uv函数中输入的字节序列很有可能不正确, 所以对于不正确的输入要进行严格的检查。 特别是在utf8_to_uv函数的末尾追加了对”冗余的UTF-8序列”的处理是很重要的. 滥用冗余的UTF-8序列的话,那就会有含有危险字符会被黑客钻空子的危险. 可以说只能通过阅读实际的代码才能得到这些知识.
在这个函数中使用了Ruby的内部错误报告函数rb_raise( )。如果想延用上面的代码的话, 则需要把rb_raise( )函数换成其他的错误报告函数.
Code.Reading是, 程序员进行学习, 修炼, 代码Review, 软件维护, 调试等等, 在编程的所有领域都要掌握的基本工作方式。这次是因为篇幅有限, 在这里只能介绍Code.Reading的最有价值的部分了. 有机会的话, Code.Reading和调试这部分我也想再详尽的讲一讲. 那这样的话,看看Code Reading的书籍, 再考虑考虑自己的代码阅读能力, 好吗.
就到这里,下次再见。
[2007/06/29]