Posted on 2011-03-12 16:03
乱78糟 阅读(3359)
评论(12) 编辑 收藏 引用 所属分类:
免费小软件 、
开源

闲暇之余,小哥我爱泡在天涯论坛上看帖,最常逛的就是煮酒论史和经济杂谈。
天涯就像一个热闹的大茶馆,泡上一杯热茶,放着自己喜欢的音乐,悠然的点开自己关注的帖子。巴特,广告,吵杂的顶贴让小哥我悠闲的心情大打折扣。
从开始的无视,到后来的忍受,到最后的爆发,小哥我终于愤怒了——难道就没有一款好用的工具吗?
百度、谷歌、必硬之,结果都不满意。
奶奶的,咱好歹也是一写程序的,不就是一个抓帖子的小软件吗?小哥自己捣鼓一个!
经过5天的分析,编码,测试,终于,小哥我满意的笑了。
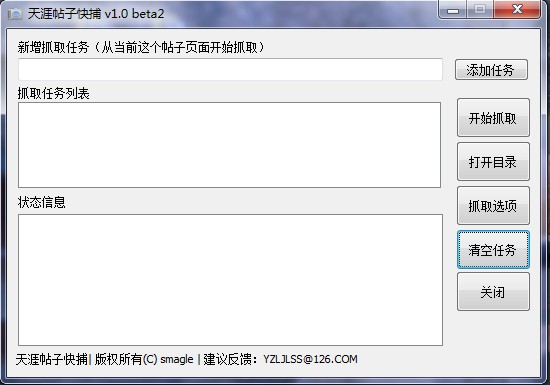
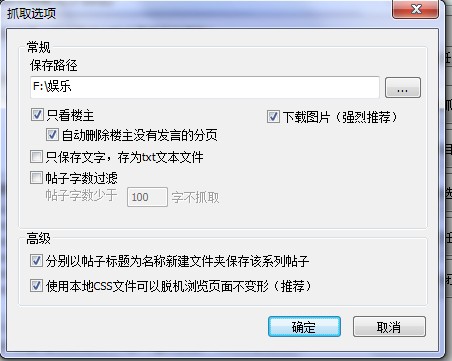
抓贴截图:
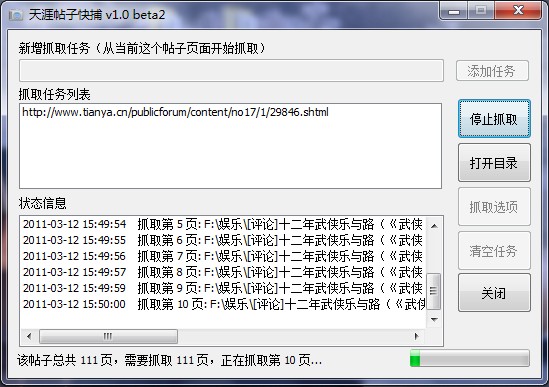
这里提供下载,希望能够帮助同是天涯客一点小忙。如果发现了BUG,或者有好的建议,一定要告诉小哥我哦,呵呵。
已经在XP,2003,WIN7下测试过,解压即可运行。
最新版本:1.0 beta3 (图不再更新了,等v1.0正式版推出,代码一并提供)
点击下载
既然有人想要代码,那么等程序版本稳定了,代码一定奉上,到时候别嫌小哥我代码写的臭哈,呵呵。
=======================[2011.3.28]=============================
额,实在是抱歉,大脑一发热这玩意就整出来了,可是热情一消散,加上最近挺忙,小哥立即跟泄了气的皮球一样,再也不想去碰这东西。
其实在使用的时候也发现不少BUG,还有不少网友提出很多颇有建设性的建议和意见,我觉得都很好,但是,整个人就是懒得去修复和新增新的功能,1.0正式版也不会再出(至少是在我手上不会出了)。
不少网友想要代码,其实代码的原理和流程非常简单,小哥觉得说破了就是哄人的小把戏,可能大家没有忘这方面想把:)。
我想我还是在提供代码之前就代码原理和路程先啰嗦几句吧:
1)利用IHTMLDocument2获取网页信息;
2)根据天涯帖子的格式内容(分析网页得出),解析、获取、修改需要网页信息内容,移除不需要的内容比如广告之类;
3)将已经重新构造的html数据流保存为相应的文件(html或者txt)。
整理出来的一些还未实现的新功能和有待改善的地方:
1)指定页面抓取(很简单,含有页面跳转按钮时你会发现天涯的程序员把所有分页的链接全部按顺序隐藏到了html代码里,稍加遍历就可得到)
2)分页合并,将多个分页的内容合并到一个分页里面
3)自动跟踪抓取,记录用户已经抓取的帖子和页数,以后从这个地方自动抓取,很实用的功能吧:)
4)删除回复某人的帖子冗余内容(比如,LZ回复某用户通常是:
作者:xxxx 回复日期:2011-02-11 14:47:36
LZ这帖子写的也忒好了!
=========
谢谢)
5)自动回帖,这个功能太邪恶鸟,其实实现起来也灰常简单(原理不透露也不要问我,自己慢慢琢磨和分析天涯的html的代码就明白了)
6)多线程抓取,当前为一个线程抓,貌似有点慢- -
7)。。。很多细微的功能,不一一道出了,感兴趣的拿到代码自己尝试去吧。
已经发现的BUG:
1)极少数帖子会导致无法抓取,原因是IHTMLDocument2无法顺利下载页面,程序无法收到FINISH消息,导致挂死,只能终止程序,原因小哥还没弄清楚,热切盼望懂的哥们给个解答,感激涕零!!
2)部分帖子,比如上了红黑板的(就是标题颜色为红脸或者黑脸,而且前面还有相颜色的小人笑脸标记的帖子),HTML格式和通常的不一样,导致抓取不到帖子实质内容,很好改的
3)IE6内核的浏览器脱机浏览抓取的帖子会变形,CSS文件导致,也比较好改
目前发现的就这么多。
废话了这么多,希望的就是有能力有时间有兴趣的同学可以搞个好用的抓取工具来,我也好偷懒享享福:)。
代码仓促完成,里面有大段C-V的重复代码,也懒得改了,毕竟这是一个小玩具而已,对吧?
代码已经提交到在googlecode上,注意,svn checkout需要密码,而获取密码那个链接被Q掉了,记得先翻Q把密码搞到手(qiang在c++ blog上尽然是一个违禁字,OMG, 伟大的天……朝!)。
代码本来想随便用的,国人对版权木有概念,后来想想,算了,还是GPL吧,共同学习而已,感兴趣的同学可以修改维护该代码,你可以联系我: yzljlss#126.com,我把你加到开发者列表里。你也可以自己另起炉灶,公不公布源代码木有关系,记得好用的工具给我邮一个呀:)
google code 主页:http://code.google.com/p/ty-bbs-capture/
代码版权:GPL
最后de呼唤:有好用的抓取工具记得一定要给小哥我U一个!