In statistics, Mahalanobis distance is a distance measure introduced by P. C. Mahalanobis in 1936.[1] It is based on correlations between variables by which different patterns can be identified and analyzed. It is a useful way of determining similarity of an unknown sample set to a known one. It differs from Euclidean distance in that it takes into account the correlations of the data set and is scale-invariant, i.e. not dependent on the scale of measurements.
Formally, the Mahalanobis distance of a multivariate vector  from a group of values with mean
from a group of values with mean 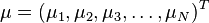 and covariance matrix S is defined as:
and covariance matrix S is defined as:
 [2]
[2]
Mahalanobis distance (or "generalized squared interpoint distance" for its squared value[3]) can also be defined as a dissimilarity measure between two random vectors 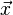 and
and  of the same distribution with thecovariance matrix S :
of the same distribution with thecovariance matrix S :
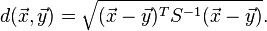
If the covariance matrix is the identity matrix, the Mahalanobis distance reduces to the Euclidean distance. If the covariance matrix is diagonal, then the resulting distance measure is called the normalized Euclidean distance:

where σi is the standard deviation of the xi over the sample set.
Intuitive explanation
Consider the problem of estimating the probability that a test point in N-dimensional Euclidean space belongs to a set, where we are given sample points that definitely belong to that set. Our first step would be to find the average or center of mass of the sample points. Intuitively, the closer the point in question is to this center of mass, the more likely it is to belong to the set.
However, we also need to know if the set is spread out over a large range or a small range, so that we can decide whether a given distance from the center is noteworthy or not. The simplistic approach is to estimate the standard deviation of the distances of the sample points from the center of mass. If the distance between the test point and the center of mass is less than one standard deviation, then we might conclude that it is highly probable that the test point belongs to the set. The further away it is, the more likely that the test point should not be classified as belonging to the set.
This intuitive approach can be made quantitative by defining the normalized distance between the test point and the set to be  . By plugging this into the normal distribution we can derive the probability of the test point belonging to the set.
. By plugging this into the normal distribution we can derive the probability of the test point belonging to the set.
The drawback of the above approach was that we assumed that the sample points are distributed about the center of mass in a spherical manner. Were the distribution to be decidedly non-spherical, for instance ellipsoidal, then we would expect the probability of the test point belonging to the set to depend not only on the distance from the center of mass, but also on the direction. In those directions where the ellipsoid has a short axis the test point must be closer, while in those where the axis is long the test point can be further away from the center.
Putting this on a mathematical basis, the ellipsoid that best represents the set's probability distribution can be estimated by building the covariance matrix of the samples. The Mahalanobis distance is simply the distance of the test point from the center of mass divided by the width of the ellipsoid in the direction of the test point.
Relationship to leverage
Mahalanobis distance is closely related to the leverage statistic, h, but has a different scale:[4]
- Mahalanobis distance = (N − 1)(h − 1/N).
Applications
Mahalanobis' discovery was prompted by the problem of identifying the similarities of skulls based on measurements in 1927.[5]
Mahalanobis distance is widely used in cluster analysis and classification techniques. It is closely related to Hotelling's T-square distribution used for multivariate statistical testing and Fisher's Linear Discriminant Analysis that is used for supervised classification.[6]
In order to use the Mahalanobis distance to classify a test point as belonging to one of N classes, one first estimates the covariance matrix of each class, usually based on samples known to belong to each class. Then, given a test sample, one computes the Mahalanobis distance to each class, and classifies the test point as belonging to that class for which the Mahalanobis distance is minimal.
Mahalanobis distance and leverage are often used to detect outliers, especially in the development of linear regression models. A point that has a greater Mahalanobis distance from the rest of the sample population of points is said to have higher leverage since it has a greater influence on the slope or coefficients of the regression equation. Mahalanobis distance is also used to determine multivariate outliers. Regression techniques can be used to determine if a specific case within a sample population is an outlier via the combination of two or more variable scores. A point can be an multivariate outlier even if it is not a univariate outlier on any variable.
Mahalanobis distance was also widely used in biology, such as predicting protein structural class[7], predicting membrane protein type [8], predicting protein subcellular localization [9], as well as predicting many other attributes of proteins through their pseudo amino acid composition [10].
多维高斯分布的指数项!做分类聚类的时候用的比较多