1 doxygen是大名鼎鼎代码文档工具。
下载地址:www.doxygen.org
安装它。http://www.stack.nl/~dimitri/doxygen/download.html 可下载.
2 Graphviz
这个工具配合doxygen使用,可以提取函数,模块之间的调用关,非常清晰。
下载地址:http://www.graphviz.org/Download..php
下面是Graphviz提取出来的一些关系图:
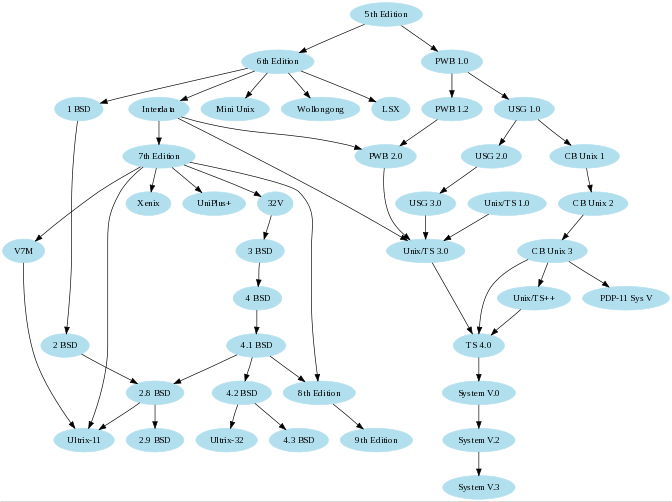
3 htmlhelp
这个工具把doxygen生成的html文件,转化为一个CHM文件,看起来方便些。
下载地址:http://www.microsoft.com/downloads/details.aspx?FamilyID=00535334-c8a6-452f-9aa0-d597d16580cc&displaylang=en
安装它。
全部安装后就可以开始使用了。
运行doxygen wizard.exe
运行doxywizard.exe,这时按照doxygen根目录下的文档(doxygen_manual-1.5.2.chm)中 Doxywizard usage一节的说明设置即可。主要包括,源码路径、工作路径、输出路径等。
点开始,即可生成文档
最后对文档生成过程中遇到的一些问题进行说明:
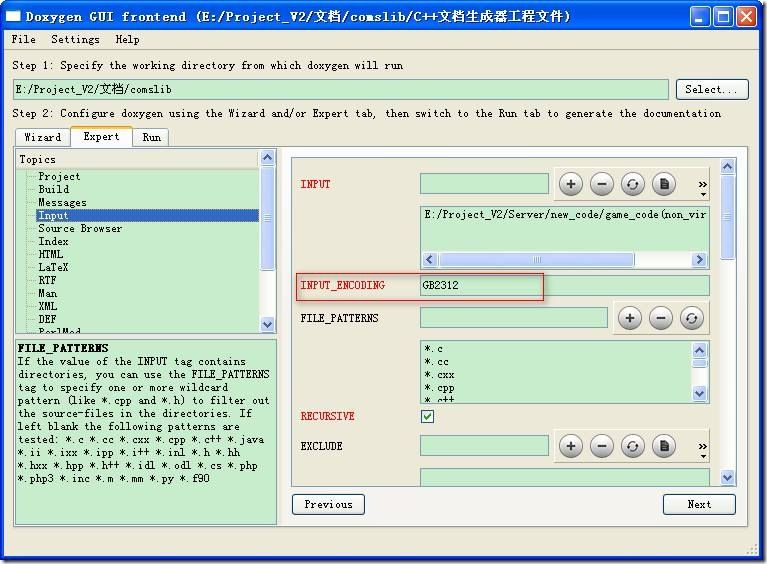
1 中文问题:中文注释在文档中是乱码。
解决:在expert中的INPUT选项页的INPUT_ENCODEING中填入“GB2312”,这样基于GB的文本编辑器生成的代码就可以正常使用了。
2 图形问题:无法绘制类图协作图等图形。
首先确保安装了graphviz,注意不是wingraphviz,后者是一个graphviz的com封装,但是doxygen并不是基于它开发的,所以装了也没用。然后在 expert的Dot页DOT_PATH中填入graphviz的安装路径。接着在wizard的diagram中选择需要生成的图形类别就可以了。
如果出现无法包含.map文件的错误,可以将工作目录设置成html,并将html中所有文件都清除再试。这个问题的原因还不太确定。
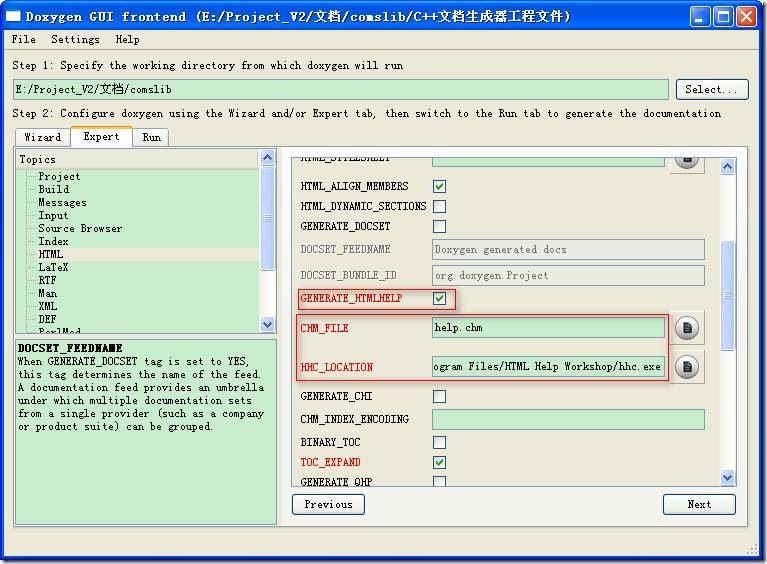
3 输出chm的问题:如何输出.chm文件
1. 你必须安装微软或其相兼容的chm编译系统。通常为HTML Help Workshop。
2. 首先在[Wizard]的Output页面中,选择HTML,然后选择到prepare for compressed HTML(.chm)。
3. 其次在[Expert]的HTML页面中,将HHC_LOCATION指向微软的hhc工具。通常为C:/Program Files/HTML Help Workshop/hhc.exe。然后点击OK,保存,编译即可。
HHC_LOCATION中输入hhc.exe文件的路径。hhc.exe可以通过安装HTML Help Workshop获得。
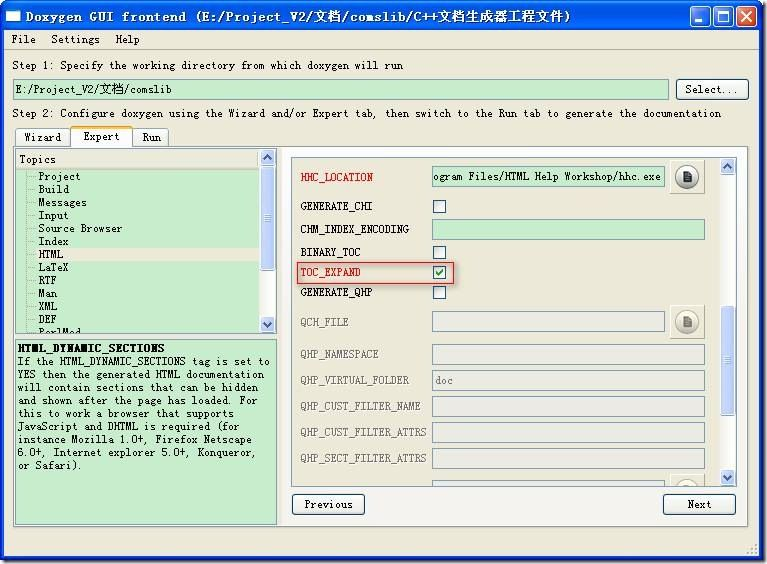
4 如何像MSDN那样在左边的树中显示函数列表?
打开[Expert]的HTML页面,然后选中TOC_EXPAND即可。
5 如何去掉CHM附带的CHI文件?
注 意在默认情况下,CHM会有一个CHI文件,似乎是用来加速索引的。我本人也遇到过很多用户仅仅上传了CHM,而没有上传CHI文件,导致无法正常显示的 情况。我不知道是否可以通过工具重建CHI文件,但是我觉得关闭这个功能即可。打开[Expert]的HTML页面,取消GENERATE_CHI 即可。
6 如何像MSDN那样右边每页显示一个函数?
这 个问题其实比较棘手,在[Expert]中的 Project页面,下面有一个选项叫做SEPARATE_MEMBER_PAGES,把这个选项选中,这样每个函数就是一个页。但是会有一个问题,那就 是右边页面的旁边多了所有函数的列表。很遗憾,经过研究,这个确实无法去掉。我的解决方法就是自己编译一下doxygen,在 memberlist.cpp的writeDocumentationPage函数中将 container->writeQuickMemberLinks(ol,md);连同附近几行屏蔽掉即可。
7 如何在CHM中去掉当选择SUBGROUPING后去掉分组的组信息?
这 个功能就是在chm的左边树中直接列出函数列表,而不用点击看右边页面了。这个功能需要修改源代码。在index.cpp中,屏蔽 writeGroupIndexItem函数的 Doxygen::indexList.addContentsItem,Doxygen::indexList.incContentsDepth和 Doxygen::indexList.decContentsDepth();即可。
8 如何修改或者去掉右下脚Generated at ...的文字?
打 开[Expert...]的HTML页面,然后在HTML_FOOTER中指定相应的HTML文件即可。注意HTML_FOOTER中至少包含BODY和 HTML结束标记。即一个最小的尾部HTML至少是这样</BODY></HTML>。同理,如果你要指定了 HTML_HEADER,他至少包含<HTML><HEAD></HEAD><BODY>
9 如何生成组?
组 就是可以把同类的函数放到一个根下的显示方式。doxygen支持grouping,即你可以把相关的代码通过标志,放到同一个组中,便于查看。这主要是 通过几个内置语法命令。首先通过@defgroup定义一个组,然后要把分组的函数或者类等,通过标志@ingroup加入相应的组。这样,相应的函数就 被放置在同一个组中。
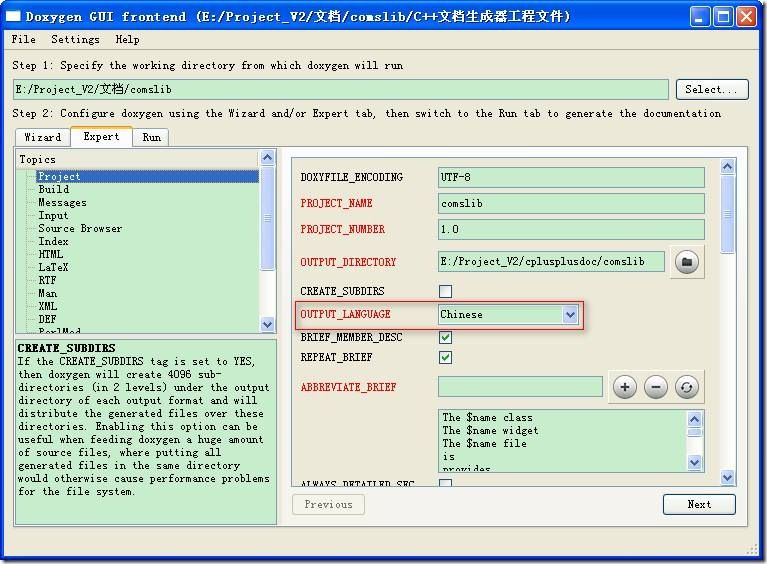
10 如何生成中文帮助?
点击[Expert],在页Project 的OUTPUT_LANGUAGE,选择Chinese,这样输出的帮助提示信息就是中文。具体中文提示信息的文字在源代码中。
11 如何彻底解决DoxyGen的输出中文chm的乱码问题?
DoxyGen的实现中大概有三处编码的设置。首先是,doxyfile,也就是配置文件。其次,INPUT_ENCODING,也就是DoxyGen需要解析的输入文件的编码。最后,就是输出的编码。譬如CHM左边的索引编码。
首先是chm的标题乱码,这个比较好解决,因为DoxyWizard使用QT做的界面,它内部做了转换,所以在DoxyWizard中输入中文,在保存的时 候,他自己做了转码,导致doxyfile中的最终的保存信息不正确。这个时候只需要用记事本打开doxyfile配置文件,输入相应中文即可。注意保存 的时候保存成ANSI编码即可。保存成其他格式的话可能需要去掉BOM,比较麻烦,没研究了。这个相应的编码设置在[Expert...]中,页 Project 的 DOXYFILE_ENCODING,不输入或者默认为UTF-8都行。
其次是右边内容乱码,这个多半是因为你没有配置好输入的文件编码类型造成的。在[Expert...]的Input页面中,有一个 INPUT_ENCODING,这个选项表示输入文件的编码方式,这要和你处理的源文件格式一致。对于我们来说(使用vs的人),一般设置为 GB2312。当然,再次声明,编码方式取决于源文件的编码方式。如果文件编码已经是UTF-8了,然而你还将其设置成GB2312,那么DoxyGen 会将UTF-8当成ANSI再进行一次UTF-8转换,自然会出错了。
最后也是经常遇到的问题就是DoxyGen生成的CHM文件的左边树目录的中文变成了乱码。这个只需要将chm索引的编码类型修改为GB2312即可。在 HTML的CHM_INDEX_ENCODING中输入GB2312即可。然而这种方法下,还有一个瑕疵之处,就是chm的搜索页的搜索结果中显示的中文 文字却变成乱码了。这是因为DoxyGen默认开启了HTML Help Workshop的Full-text search全文搜索选项,他在进行全文搜索的时候,应该是打开文件然后按照ANSI进行搜索的,(资料表示HHW不支持UTF-8,仅支持ISO- 8859-1或者windows-1252编码。)而Doxygen生成的右边界面统一是UTF-8,这自然出现了问题。而在这种情况下做全文搜索,理论 上只能搜索英文。
我们的解决方案只能是重新编译DoxyGen代码,为了满足搜索,只要保证右边的页面文件不是UTF-8即可。我们首先修改 writeDefaultHeaderFile这个函数的代码,将其charset=GB2312。然后在 TranslatorDecoder的构造函数中修改m_toUtf8 = (void*)-1;即屏蔽文本写入时最终的转换函数。最后删除INPUT_ENCODING的设置或者输入UTF-8。这样会使DoxyGen认为我们 的文本是UTF-8的,从而不用进行转换。生成替换原始的DoxyGen即可。
另外需要补充的是,还有一种方案是不用修改作者的源代码,但是需要将DoxyGen生成的右边的HTML文件使用工具(如iconv)手工转换成GB2312,然后再使用HTML Help Workshop生成,网上有篇文章介绍过,我测试一下,也是没有问题的。
最后,doxygen是一个开源项目,并且支持vs2005项目,这样一来,如果你觉得哪里不顺手,完全可以把代码下载后自行编译。
这样,基本上就能够用doxygen生成漂亮的文档了。代码方面,doxygen支持多种格式的注释风格,根据manual选择自己喜欢的就好。