手把手教你写脚本引擎(一)——挑选语言的特性
陈梓瀚
华南理工大学软件本科05级
vczh@163.com
http://www.cppblog.com/vczh/
脚本引擎的作用在于增强程序的可配置性。从游戏到管理系统都需要脚本,甚至连工业级产品的Office、3DS Max以及AutoCAD等都添加了属于自己的脚本语言。DHTML的出现让我们可以在网页代码中嵌入脚本语言,PHP和ASP等技术的出现让我们可以将一个应用程序的界面换成网页,而逻辑使用脚本语言编写。现在脚本语言的种类繁多,Python的发展让BOOST库拥有了对Python的支持,Rails框架的出现壮大了Ruby的实力,LUA更是被大量应用在游戏开发中。Windows甚至提供了wscript以便让我们能够调用javascript和vbscript的代码。
既然有了这么多可供选择的脚本引擎,为什么我们仍然要开发自己的脚本引擎呢?首先,我们并不能保证现有的脚本引擎能够满足我们做出来的系统。因为我们所需要的脚本可能很简单,用现有的脚本引擎比较浪费。或者我们的脚本复杂,但是功能比较“神奇”(譬如SQL)以至于没有能够满足我们需要的脚本引擎。因为脚本并不一定是通用语言,脚本仅仅是为了满足我们增强系统的可配置性而出现的。其次,脚本引擎足够复杂,可以训练我们的编程能力。在我们的业余时间里面开发出来的程序并不完全是为了满足某个应用的需要而产生的,有可能是我们为了自身的提高而进行的摸索。开发脚本引擎足以成为锻炼的方法之一。
计算机语言作为一个计算的定义,在我们开发脚本引擎之前需要先进行了解。对于目前流行的若干种语言,我们可以抽象出一组正交属性来描述他们。
一、命令式与描述式
一门语言是命令式或者描述式取决于这门语言是用来告诉计算机怎样做还是做什么的。举个例子,SQL和Prolog是描述式语言,而C++、C#等则是命令式语言。我们在使用SQL的时候告诉服务器的是我们需要满足什么条件的数据项,而不是告诉服务器我们需要通过什么计算来获得自己所需要的数据项。描述式的语言的优点在于其可读性好。C# 3.0为数据查询加入了LINQ让我们可以在C#中书写类似SQL的代码查询数据。
另一个比较模糊的例子则是Haskell。Haskell很难区分是命令式语言还是描述式语言。因为从形式上来说我们告诉编译器的是我们想做什么而不是我们想怎么做,但是Haskell给我们的工具的粒度太细以至于我们为了告诉编译器做什么的同时仍然需要考虑一个问题是如何被解决的。
二、按值计算与惰性计算
惰性计算的语言很少出现以至于可能很多人都不知道“原来语言可以是这个样子的”。惰性计算的精神是不去执行没用的代码。什么是没用的代码呢?只要是这段代码的值不对外界产生任何影响,譬如没有往屏幕、硬盘或者是其他什么地方写点什么数据,就是没有用的。当然,至于这段代码中间做了些什么事情那是不管的。
举一个比较简单的例子,假设现在有如下代码:
function PrintAndReturn(Message,Result)
{
Print(Message);
return Result;
}
function DoSomething(BoolA,BoolB)
{
If(BoolA || BoolB) Print(“!”);
}
DoSomething(PrintAndReturn(“Hello”,true),PrintAndReturn(“World”,false));
DoSomething函数传入两个参数,都是布尔类型的。如果这两个参数其中有一个是true的话那么就往屏幕上打出一个感叹号。PrintAndReturn函数接受两个参数,往屏幕上打出第一个参数,函数返回第二个参数。
对于一门按值计算的语言,也就是我们平常见到的那种,执行的结果是“HelloWorld!”。因为为了调用DoSomething我们需要首先获得两个布尔值。
对于一门惰性计算的语言,执行的结果是“Hello!”。因为DoSomething在对BoolA || BoolB进行求值的时候计算了BoolA,发现是true,于是BoolB这个参数就没有用了,因此PrintAndReturn(“World”,false)也就不会执行了,导致“World”不会显示在屏幕上。
当然,对于上面举的这个例子来说,这种语言有着惰性计算的属性并不合理。一门语言为了不具有二义性,在存在惰性计算的同时必须对自己的类型系统进行改造。关于这方面的资料可以查阅Haskell语言中Monad的原理。Haskell作为一门惰性计算的语言,在不关心求值顺序的同时,仍然保证结果的一致性。上面这个例子,如果程序对||的求值是从右操作数开始的话,那么输出的结果就变成“HelloWorld!”了。惰性计算的好处在于可以在逻辑上表达无穷大的对象,而在实际的计算过程中并不需要将这个无穷大的对象一次性计算出来,而是需要哪里算到哪里。举个例子:
function MakeArray(Index)
{
return [Index]++MakeArray(Index+1);
}
function Sum(Array,Count)
{
Result=0;
for i=0 to Count-1
Result+=Array[i];
return Result;
}
Print(Sum(MakeArray(1),10));
在这个例子中,[Index]代表一个只有一个元素的数组,其内容是Index,而++操作符将两个数组接起来。于是MakeArray(1)就产生了一个无穷长的数组,其内容是[1,2,3,4,…]。Sum计算数组的前若干个数字的和。对于一门惰性计算的语言,这个例子将输出55,因为我们需要的仅仅是前10个数字,因此MakeArray只需要递归10次就自动挺下来了。而对于一门按值计算的语言来说,将发生死循环而出现不可停机现象。
三、强类型、弱类型与无类型
一门语言是无类型当且仅当一个固定的符号的类型可以在运行时改变。譬如如下代码:
TheVariable=1;
TheVariable=”I am a string!”;
第一行创建了一个int类型的TheVariable变量,而第二行则将TheVariable修改成了字符串类型。一门无类型语言的对象类型可以是数值、字符串、数组、类、闭包、函数指针等等的东西。
只要不是无类型的,那必然就是强类型或者弱类型的了。强类型与弱类型的分界线比较明显。只要存在隐式类型转换的语言则是弱类型的,譬如C语言能将int隐式转换为double。不存在隐式转换的语言也是存在的,譬如Haskell。在Haskell里面不能创建一个实数类型的名字但是绑定一个整数的值上去。因为整数跟实数的类型是不同的,而且不存在隐式转换。
四、函数与闭包
凡是支持闭包的语言必然是支持函数的,但是并不是所有支持函数的语言都支持闭包,而且也并不是所有的语言都有函数。Windows的批处理文件所能理解的语言就是不支持函数的语言的一个例子。
至于什么是闭包呢?闭包就是可以保持函数执行的上下文的一种强大的函数指针。举个例子:
function Add(a)
{
return function(b)
{
Return a+b;
}
}
Inc=Add(1);
Inc10=Add(10);
Print(Inc(5));
Print(Inc10(5));
这个例子将输出6和15。执行Inc=Add(1);的时候,Add函数返回了一个新的函数,这个函数接受参数b并返回参数a和b相加的结果。返回的这个函数将参数a记了下来。所以Inc和Inc10在执行的时候,虽然执行的是同一个函数,但是这个函数所看到的a确是不同的。a的值的不同代表着Inc和Inc10执行函数的不同。这也就是闭包是可以保持函数执行的上下文的由来了。当然,一门不支持闭包的语言是不能允许上面这种写法的。
这四种属性是区分语言特征的重要属性。至于一门语言是否支持面向对象的写法或者支持元编程或者泛型之类的东西,并不是十分重要的特性,虽然我们使用起来的感觉非常不同。
那么我们如何选择我们所需要的特性呢?对于一个简单的事务脚本来说,我们只需要非常简单的特性诸如选择结构和循环结构,和简单的计算功能。计算功能可以支持表达式也可以不支持表达式。一门不支持表达式的语言看起来就像MASM支持的那种有宏的汇编语言。就像前些日子CSDN抄得很热的概念DSL一样,我们在设计一门脚本语言的时候,想的不应该是这门语言如何如何强大,而应该是这门语言应该如何更好地表达领域相关的信息。
下面这幅图片显示的是笔者在高中的时候开发的一款RPG的地图编辑器。众所周知,RPG是需要剧情的,因此编辑器需要在地板上或人物上设置陷阱引发脚本的执行。
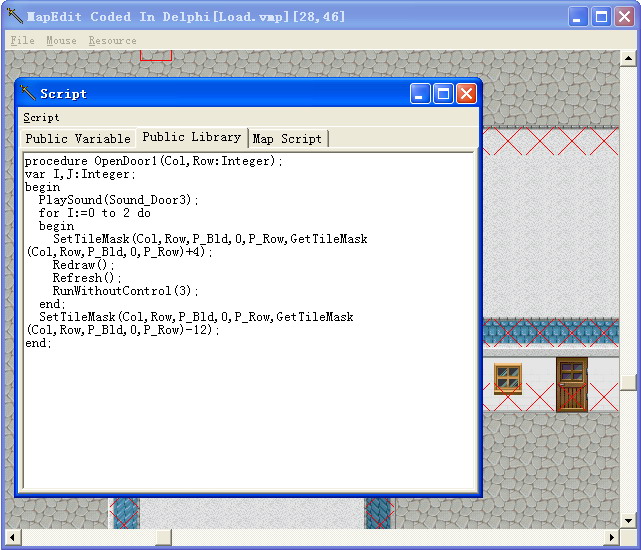
RPG由于剧情复杂,需要的控制方法也就很多,因此供给RPG使用的脚本至少应该支持选择和循环等。而且有的时候需要使用脚本来完成某些动画(譬如上图中的开门脚本),因此脚本也就需要函数了。至于为什么上面的脚本使用Pascal的语法仅仅是因为笔者当时Delphi用得比较多。这也是笔者第一次实现的一款脚本引擎。
那么,我们如何选择脚本语言的特性呢?我们要考虑一下系统的复杂度,因为脚本语言的特性跟我们想提供给脚本语言的库是有很大关系的。
举个例子,如果提供给脚本的库经常需要调用到脚本的函数的话(比如GUI,比如可以给脚本用的类似YACC的东西等),那么脚本最好具有闭包的特性,没有的话至少也得有函数指针这种类型。如果提供给脚本的库的大部分函数都可以接受很多种不同类型的对象的话,那么脚本最好是无类型的。如果库很庞大,大到不得不用命名空间和类来提供的话,那脚本无论如何都要有类的。
对于某些专用领域的语言,一般都采用类似自然语言(但是具有严格定义)的外观来组织脚本,最好的例子就是SQL了。如果从语言的角度看,SQL的select是一个具有很多参数,而且大部分参数都具有缺省值的函数,而且大部分函数都是一些lambda表达式。因为lambda表达式出现得太多,因此就需要简化lambda表达式的语法了。所以最终出现在我们面前的语法就是select中到处都可以写有参数的表达式,而且这些参数来自于select的表名和重命名。
如果脚本本身需要非常快的话,那么最好使用强类型或者弱类型。因为这两种特性的语言的每一个符号都是有确定的类型的,虚拟机的开发不仅有很多方法,而且还有可能做成JIT(也就是编译成机器码)。在这种情况下,库的供给就要非常注意了。因为在大部分情况下脚本都是在跟库打交道的,所以交互的部分要详细考虑。
如果脚本仅仅是用来做一些简单的配置工作的话,那么表达式可以全免,用命令的外观设计语法。而且在大多数情况下连函数都可以免。这样的话这门语言就剩下变量、分支和循环了,就跟Windows的批处理一样。
最后一个需要提及但是大部分情况下不用管的属性就是脚本的计算能力。这个计算能力说的不是计算的速度,而是解决的问题的范围。这个属性就是图灵完备了。通俗地讲,对于任何一个数学问题,如果只要C语言算得出来脚本语言都算得出来的话,那么这门脚本语言就是图灵完备的了。当然,因为C语言也是图灵完备的,而且图灵完备的计算能力在有限线程的计算机中是最高的,因此不存在一个数学问题,某种语言算得出来而C语言算不出来。那么如何判断一门语言是不是图灵完备的呢?
简单的来说,有数组的语言就是图灵完备的,有闭包的语言也是图灵完备的。如果数组也没有,闭包也没有,那么有结构(C语言的struct和Pascal的record)和有指向结构的指针的语言也是图灵完备的。因为闭包的内部结构也是一些保留环境的struct,因此只要能表达递归数据结构的语言都是图灵完备的。
这一篇文章就先将到这里了。下一篇文章将会讲述如何实现最简单的命令型脚本语言,再下一篇文章开始将会有几篇文章讲述如何实现一门有数组和函数的弱类型脚本语言,接着会对这门语言进行扩充。
posted on 2008-07-07 07:45
陈梓瀚(vczh) 阅读(21632)
评论(12) 编辑 收藏 引用 所属分类:
脚本技术