转自:http://blog.csdn.net/fuyangchang/article/details/5637464
wiki地址http://en.wikipedia.org/wiki/Hamming_distance
在信息领域,两个长度相等的字符串的海明距离是在相同位置上不同的字符的个数,也就是将一个字符串替换成另一个字符串需要的替换的次数。
例如:
- "toned" and "roses" is 3.
- 1011101 and 1001001 is 2.
- 2173896 and 2233796 is 3.
对于二进制来说,海明距离的结果相当于 a XOR b 结果中1的个数。
python代码如下
def hamming_distance(s1, s2):
assert len(s1) == len(s2)
return sum(ch1 != ch2 for ch1, ch2 in zip(s1, s2))
print (hamming_distance("gdad","glas"))
结果是2
C语言代码如下
unsigned hamdist(unsigned x, unsigned y)
{
unsigned dist = 0, val = x ^ y;
// Count the number of set bits
while(val)
{
++dist;
val &= val - 1;
}
return dist;
}
int main()
{
unsigned x="abcdcc";
unsigned y="abccdd";
unsigned z=hamdist(x,y);
printf("%d",z);
}
本文转自:http://www.cppblog.com/humanchao/archive/2012/12/26/196680.html
posted @
2013-01-07 16:37 王海光 阅读(677) |
评论 (0) |
编辑 收藏
By unanao
<sunjianjiao@gmail.com>
一、什么是大小端问题
(From《Computer Systems,A Programer's Perspective》)在几乎所有的机器上,多字节对象被存储为连续的字节序列,对象的地址为所使用字节序列中最低字节地址。
小端:某些机器选择在存储器中按照从最低有效字节到最高有效字节的顺序存储对象,这种最低有效字节在最前面的表示方式被称为小端法(little endian) 。这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;
大端:某些机器则按照从最高有效字节到最低有效字节的顺序储存,这种最高有效字节在最前面的方式被称为大端法(big endian) 。这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低,和我们的逻辑方法一致。
举个例子来说名大小端: 比如一个int x, 地址为0x100, 它的值为0x1234567. 则它所占据的0x100, 0x101, 0x102, 0x103地址组织如下图:
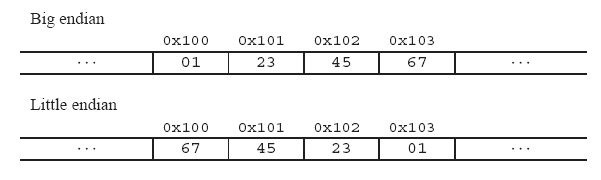
二、为什么会有大小端模式之分呢?
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为 8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于 8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如果将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。例如一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。对于 大端模式,就将0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,刚好相反。我们常用的X86结构是小端模式,而KEIL C51则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
三、如何区分大小端问题:
方法1:
1 #include <stdio.h>
2
3 int main(void)
4 {
5 int i = 1;
6 unsigned char *pointer;
7
8 pointer = (unsigned char *)&i;
9 if(*pointer)
10 {
11 printf("litttle_endian");
12 }
13 else
14 {
15 printf("big endian\n");
16 }
17
18 return 0;
19 }
C中的数据类型都是从内存的低地址向高地址扩展,取址运算"&"都是取低地址。小端方式中(i占至少两个字节的长度)则i所分配的内存最小地址那个字节中就存着1,其他字节是0。大端的话则1在i的最高地址字节处存放,char是一个字节,所以强制将char型量p指向i,则p指向的一定是i的最低地址,那么就可以判断p中的值是不是1来确定是不是小端。
方法2:
1 #include <stdio.h>
2
3 int main(void)
4 {
5 union {
6 short a;
7 char ch;
8 } u;
9 u.a = 1;
10
11 if (u.ch == 1)
12 {
13 printf("Littel endian\n");
14 }
15 else
16 {
17 printf("Big endian\n");
18 }
19 }
利用联合体的特点,数据成员共享内存空间,union中元素的起始地址都是相同的——位于联合的开始。 用char来截取感兴趣的字节。
四、需要考虑大小端(字节顺序)的情况
1、所写的程序需要向不同的硬件平台迁移,说不定哪一个平台是大端还是小端,为了保证可移植性,一定提前考虑好。
2. 在不同类型的机器之间通过网络传送二进制数据时。 一个常见的问题是当小端法机器产生的数据被发送到大端法机器或者反之时,接受程序会发现,字(word)里的字节(byte)成了反序的。为了避免这类问 题,网络应用程序的代码编写必须遵守已建立的关于字节顺序的规则,以确保发送方机器将它的内部表示转换成网络标准,而接受方机器则将网络标准转换为它的内部标准。
3. 当阅读表示整数的字节序列时。这通常发生在检查机器级程序时,e.g.:反汇编得到的一条指令:
80483bd: 01 05 64 94 04 08 add %eax, 0x8049464
3. 当编写强转的类型系统的程序时。如写入的数据为u32型,但是读取的时候却是char型的。如:0x1234, 大端读取为12时,小端独到的是34。
六、提高程序的可移植性
使用宏编译
#ifdef LITTLE_ENDIAN
//小端的代码
#else
//大端的代码
#endif
七、大、小端之间的转换
1、小端转换为大端
1 #include <stdio.h>
2
3 void show_byte(char *addr, int len)
4 {
5 int i;
6
7 for (i = 0; i < len; i++)
8 {
9 printf("%.2x \t", addr[i]);
10 }
11 printf("\n");
12 }
13
14 int endian_convert(int t)
15 {
16 int result;
17 int i;
18
19 result = 0;
20 for (i = 0; i < sizeof(t); i++)
21 {
22 result <<= 8;
23 result |= (t & 0xFF);
24 t >>= 8;
25 }
26
27 return result;
28 }
29
30 int main(void)
31 {
32 int i;
33 int ret;
34
35 i = 0x1234567;
36
37 show_byte((char *)&i, sizeof(int));
38 ret = endian_convert(i);
39 show_byte((char *)&ret, sizeof(int));
40
41 return 0;
42 }
本文转自:http://www.cppblog.com/humanchao/archive/2012/12/26/196684.html
posted @
2013-01-07 16:33 王海光 阅读(842) |
评论 (0) |
编辑 收藏题目描述:
一个循环有序数组(如:3,4,5,6,7,8,9,0,1,2),不知道其最小值的位置,要查找任一数值的位置。要求算法时间复杂度为log2(n)。
问题分析:
我们可以把循环有序数组分为左右两部分(以mid = (low+high)/ 2为界),由循环有序数组的特点知,左右两部分必有一部分是有序的,我们可以找出有序的这部分,然后看所查找元素是否在有序部分,若在,则直接对有序部分二分查找,若不在,对无序部分递归调用查找函数。
代码如下:
#include <iostream>
using namespace std;
int binarySearch(int a[],int low,int high,int value) //二分查找
{
if(low>high)
return -1;
int mid=(low+high)/2;
if(value==a[mid])
return mid;
else if(value>a[mid])
return binarySearch(a,mid+1,high,value);
else
return binarySearch(a,low,mid-1,value);
}
int Search(int a[],int low,int high,int value) //循环有序查找函数
{
int mid=(low+high)/2;
if(a[mid]>a[low]) //左有序
{
if(a[low]<=value && value<=a[mid] ) //说明value在左边,直接二分查找
{
return binarySearch(a,low,mid,value);
}
else //value在右边
{
return Search(a,mid+1,high,value);
}
}
else //右有序
{
if(a[mid]<=value && value<=a[high])
{
return binarySearch(a,mid,high,value);
}
else
{
return Search(a,low,mid-1,value);
}
}
}
int main()
{
int a[]={3,4,5,6,7,8,9,0,1,2};
cout<<Search(a,0,9,0)<<endl;
return 0;
}
本文转自:http://www.cppblog.com/humanchao/archive/2012/12/26/196686.html
posted @
2013-01-07 16:31 王海光 阅读(501) |
评论 (0) |
编辑 收藏
本文转自:http://www.cppblog.com/humanchao/archive/2012/12/26/196690.html
posted @
2013-01-07 16:29 王海光 阅读(1809) |
评论 (0) |
编辑 收藏C++
1、《高性能 Windows Socket 服务端与客户端组件(源代码及测试用例下载)》
《基于 IOCP 的通用异步 Windows Socket TCP 高性能服务端组件的设计与实现》
《通用异步 Windows Socket TCP 客户端组件的设计与实现》
摘要:编写 Windows Socket TCP 客户端其实并不困难,Windows 提供了6种 I/O 通信模型供大家选择。但本座看过很多客户端程序都把 Socket 通信和业务逻辑混在一起,剪不断理还乱。每个程序都 Copy / Parse 类似的代码再进行修改,实在有点情何以堪。因此本座利用一些闲暇时光写了一个基于 IOCP 的通用异步 Windows Socket TCP 高性能服务端组件和一个通用异步 Windows Socket TCP 客户端组件供各位看官参详参详,希望能激发下大家的灵感。
资源下载地址:http://ldcsaa.googlecode.com/files/socket_server_and_client.zip
2、《Windows C++ 应用程序通用日志组件(组件及测试程序下载)》
摘要:编写一个通用的日志组件应该着重考虑三个方面:功能、可用性和性能。下面,本座详细说明在设计日志组件时对这些方面问题的考虑:
- 功能:本日志组件的目的是满足大多数应用程序记录日志的需求 —— 把日志输出到文件或发送到应用程序中,并不提供一些复杂但不常用的功能
- 可用性:本日志组件着重考虑了可用性,尽量让使用者用起来觉得简便、舒心
- 性能:性能是组件是否值得使用的硬指标,本组件从设计到编码的过程都尽量考虑到性能优化
资源下载地址:http://ldcsaa.googlecode.com/files/VC_Logger.zip
3、《如何养成良好的 C++ 编程习惯(一)—— 内存管理》
摘要:说起 C/C++ 的内存管理似乎令人望而生畏,满屏的 new / delete / malloc / free,OutPut 窗口无尽的 Memory Leak 警告,程序诡异的 0X00000004 指针异常,仿佛回到那一年我们一起哭过的日子,你 Hold 得住吗?其实,现实并没有你想的那么糟糕。只要你付出一点点,花一点点心思,没错!就一点点而已 —— 用 C++ 类封装内存访问,就会解决你大部分的烦恼,让你受益终身。以 Windows 程序为例,主要有以下几种内存管理方式:
- 虚拟内存(Virtual Memory)
- 默认堆和私有堆(Process Heap & Private Heap)
- 内存映射文件(File Mapping)
- 进程堆栈(Heap,其实就是用 malloc() 或 默认的 new 操作符在 Process Heap 里一小块一小块地割肉 ^_^)
- 栈(Stack,内存由调用者或被调用者自动管理)
资源下载地址:http://ldcsaa.googlecode.com/files/socket_server_and_client.zip (源代码在 Common/Src 目录中)
4、《实现 Win32 程序的消息映射宏(类似 MFC )》
摘要:对于消息映射宏,不用多说了,用过 MFC 的人都很清楚。但目前有不少程序由于各种原因并没有使用 MFC,所以本帖讨论一下如何在 Win32 程序中实现类似MFC的消息映射宏。其实 Windows 的头文件 “WindowsX.h”(注意:不是“Windows.h”) 中提供了一些有用的宏来帮助我们实现消息映射。本座是也基于这个头文件实现消息映射。
资源下载地址:http://ldcsaa.googlecode.com/files/socket_server_and_client.zip (源代码在 Common/Src/Win32Helper.h 文件中)
5、《用宏实现 C++ Singleton 模式》
摘要:Singleton 设计模式应用非常广泛,实现起来也很简单,无非是私有化若干个构造函数,“operator =” 操作符,以及提供一个静态的创建和销毁方法。但是对每个类都写这些雷同的代码是本座不能容忍的,因此,本座使用宏把整个 Singleton 模式封装起来,无论是类的定义还是类的使用的极其简单。
资源下载地址:http://ldcsaa.googlecode.com/files/socket_server_and_client.zip (源代码在 Common/Src/Singleton.h 文件中)
6、《C++ 封装私有堆(Private Heap)》
摘要:Private Heap 是 Windows 提供的一种内存内存机制,对于那些需要频繁分配和释放动态内存的应用程序来说,Private Heap 是提高应用程序性能的一大法宝,使用它能降低 new / malloc 的调用排队竞争以及内存空洞。
资源下载地址:http://ldcsaa.googlecode.com/files/socket_server_and_client.zip (源代码在 Common/Src/PrivateHeap.h 文件中)
7、《基于 crt debug 实现的 Windows 程序内存泄漏检测工具》
摘要:Windows 程序内存泄漏检测是一项十分重要的工作,基于 GUI 的应用程序通常在调试结束时也有内存泄漏报告,但这个报告的信息不全面,不能定位到产生泄漏的具体行号。其实自己实现一个内存泄漏检测工具是一件非常简单的事情,但看过网上写的很多例子,普遍存在两种问题:
- 要么考虑不周全,一种环境下能用,而在另外一种环境下却不能很好工作,或者漏洞报告的输出方式不合理。
- 要么过于保守,例如:完全没有必要在 _malloc_dbg() 和 _free_dbg() 的调用前后用 CriticalSection 进行保护(跟踪一下多线程环境下 new 和 malloc 的代码就会明白)。
资源下载地址:http://ldcsaa.googlecode.com/files/socket_server_and_client.zip (源代码在 Common/Src/debug/win32_crtdbg.h 文件中)
Java
1、《Portal-Basic Java Web 应用开发框架 v3.0.1 正式发布(源码、示例及文档)》
摘要:Portal-Basic Java Web应用开发框架(简称 Portal-Basic)是一套功能完备的高性能Full-Stack Web应用开发框架,内置稳定高效的MVC基础架构和DAO框架(已内置Hibernate、MyBatis和JDBC支持),集成 Action拦截、Form Bean / Dao Bean / Spring Bean装配、国际化、文件上传下载和缓存等基础Web应用组件,提供高度灵活的纯 Jsp/Servlet API 编程模型,完美整合 Spring,支持Action Convention“零配置”,能快速开发传统风格和RESTful风格的Web应用程序,文档和代码清晰完善,非常容易学习。
资源下载地址:http://code.google.com/p/portal-basic/downloads/list
2、《用 Java 实现的日志切割清理工具(源代码下载)》
摘要:对于服务器的日常维护来说,日志清理是非常重要的事情,如果残留日志过多则严重浪费磁盘空间同时影响服务的性能。如果用手工方式进行清理,会花费太多时间,并且很多时候难以满足实际要求。例如:如何在每个星期六凌晨3点把超过2G大的日志文件进行切割,保留最新的100M日志记录?网上没有发现能满足本座要求的日志切割工具,因此花了一些闲暇时间自己写了一个。由于要在多个平台上使用,为了方便采用 Java 实现。本工具命名为 LogCutter,主要有以下特点:
- 支持 Linux、Mac 和 Windows 等所有常见操作系统平台
- 支持命令行交互式运行
- 支持后台非交互式运行(Linux/MAC 下使用 daemon 进程实现,Windows 用系统 Service 实现)
- 支持两种日志清理方式(删除日志文件或切割日志文件)
- 支持对 GB18030、UTF-8、UTF-16LE、UTF-16BE 等常用日志文件类型进行切割(不会发生切掉半个字符的情况)
- 高度可配置(程序执行周期、要删除的日志文件过期时间、要切割的日志文件阀值和保留大小等均可配置
资源下载地址:http://ldcsaa.googlecode.com/files/LogCutter.zip
3、《通用 Java 文件上传和下载组件的设计与实现》
摘要:文件上传和下载是 Web 应用中的一个常见功能,相信各位或多或少都曾写过这方面相关的代码。但本座看过不少人在实现上传或下载功能时总是不知不觉间与程序的业务逻辑纠缠在一起,因此,当其他地方要用到这些功能时则无可避免地 Copy / Pase,然后再进行修改。这样丑陋不堪的做法导致非常容易出错不说,更大的问题是严重浪费时间不断做重复类似的工作,这是本座绝不能容忍的。哎,人生苦短啊,浪费时间在这些重复工作身上实在是不值得,何不把这些时间省出来打几盘罗马或者踢一场球?为此,本座利用一些闲暇之时光编写了一个通用的文件上传和文件下载组件,实现方法纯粹是基于 JSP,没有太高的技术难度,总之老少咸宜 ^_^。现把设计的思路和实现的方法向各位娓娓道来,希望能起到抛砖引玉的效果,激发大家的创造性思维。
资源下载地址:http://code.google.com/p/portal-basic/downloads/list (作为 Portal-Basic 第一部分,代码在 com.bruce.util.http 包中)
4、《深度剖析:Java POJO Bean 对象与 Web Form 表单的自动装配》
摘要:时下很多 Web 框架 都实现了 Form 表单域与 Java 对象属性的自动装配功能,该功能确实非常有用,试想如果没这功能则势必到处冲积着 request.getParameter() 系列方法与类型转换方法的调用。重复代码量大,容易出错,同时又不美观,影响市容。现在的问题是,这些框架通过什么方法实现自动装配的?如果不用这些框架我们自己如何去实现呢?尤其对于那些纯 JSP/Servlet 应用,要是拥有自动装配功能该多好啊!本座深知各位之期盼,决定把自动装配的原理和实现方法娓娓道来。
资源下载地址:http://code.google.com/p/portal-basic/downloads/list (作为 Portal-Basic 第一部分,代码在 com.bruce.util 包中)
5、《Linux 安装 MySQL / MySQL 主从备份》
资源下载地址:http://ldcsaa.googlecode.com/files/services.zip
本文转自:http://www.cppblog.com/ldcsaa/archive/2013/01/07/197048.html
posted @
2013-01-07 10:39 王海光 阅读(405) |
评论 (0) |
编辑 收藏
NSIS插件下载
posted @
2013-01-06 14:33 王海光 阅读(733) |
评论 (0) |
编辑 收藏淘宝地址:http://item.taobao.com/item.htm?id=15567575512
posted @
2013-01-06 10:22 王海光 阅读(391) |
评论 (0) |
编辑 收藏posted @
2013-01-05 15:06 王海光 阅读(371) |
评论 (0) |
编辑 收藏posted @
2012-12-27 15:23 王海光 阅读(3294) |
评论 (1) |
编辑 收藏
编译步骤如下:
打开终端,输入以下命令进行预处理。 qmake -project qmake TestGUI.pro make 然后终端会跳出一大串信息,编译成功 接着运行./TestGUI
posted @
2012-12-05 17:26 王海光 阅读(633) |
评论 (0) |
编辑 收藏