查看运行时数据
———————
在你调试程序时,当程序被停住时,你可以使用print命令(简写命令为p),或是同义命令inspect来查看当前程序的运行数据。print命令的格式是:
print <expr>
print /<f> <expr>
<expr>是表达式,是你所调试的程序的语言的表达式(GDB可以调试多种编程语言),<f>是输出的格式,比如,如果要把表达式按16进制的格式输出,那么就是/x。
一、表达式
print和许多GDB的命令一样,可以接受一个表达式,GDB会根据当前的程序运行的数据来计算这个表达式,既然是表达式,那么就可以是当前程序运行中的const常量、变量、函数等内容。可惜的是GDB不能使用你在程序中所定义的宏。
表达式的语法应该是当前所调试的语言的语法,由于C/C++是一种大众型的语言,所以,本文中的例子都是关于C/C++的。(而关于用GDB调试其它语言的章节,我将在后面介绍)
在表达式中,有几种GDB所支持的操作符,它们可以用在任何一种语言中。
@
是一个和数组有关的操作符,在后面会有更详细的说明。
::
指定一个在文件或是一个函数中的变量。
{<type>} <addr>
表示一个指向内存地址<addr>的类型为type的一个对象。
二、程序变量
在GDB中,你可以随时查看以下三种变量的值:
1、全局变量(所有文件可见的)
2、静态全局变量(当前文件可见的)
3、局部变量(当前Scope可见的)
如果你的局部变量和全局变量发生冲突(也就是重名),一般情况下是局部变量会隐藏全局变量,也就是说,如果一个全局变量和一个函数中的局部变量同名时,如果当前停止点在函数中,用print显示出的变量的值会是函数中的局部变量的值。如果此时你想查看全局变量的值时,你可以使用“::”操作符:
file::variable
function::variable
可以通过这种形式指定你所想查看的变量,是哪个文件中的或是哪个函数中的。例如,查看文件f2.c中的全局变量x的值:
gdb) p 'f2.c'::x
当然,“::”操作符会和C++中的发生冲突,GDB能自动识别“::” 是否C++的操作符,所以你不必担心在调试C++程序时会出现异常。
另外,需要注意的是,如果你的程序编译时开启了优化选项,那么在用GDB调试被优化过的程序时,可能会发生某些变量不能访问,或是取值错误码的情况。这个是很正常的,因为优化程序会删改你的程序,整理你程序的语句顺序,剔除一些无意义的变量等,所以在GDB调试这种程序时,运行时的指令和你所编写指令就有不一样,也就会出现你所想象不到的结果。对付这种情况时,需要在编译程序时关闭编译优化。一般来说,几乎所有的编译器都支持编译优化的开关,例如,GNU的C/C++编译器GCC,你可以使用“-gstabs”选项来解决这个问题。关于编译器的参数,还请查看编译器的使用说明文档。
三、数组
有时候,你需要查看一段连续的内存空间的值。比如数组的一段,或是动态分配的数据的大小。你可以使用GDB的“@”操作符,“@”的左边是第一个内存的地址的值,“@”的右边则你你想查看内存的长度。例如,你的程序中有这样的语句:
int *array = (int *) malloc (len * sizeof (int));
于是,在GDB调试过程中,你可以以如下命令显示出这个动态数组的取值:
p *array@len
@的左边是数组的首地址的值,也就是变量array所指向的内容,右边则是数据的长度,其保存在变量len中,其输出结果,大约是下面这个样子的:
(gdb) p *array@len
$1 = {2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40}
如果是静态数组的话,可以直接用print数组名,就可以显示数组中所有数据的内容了。
四、输出格式
一般来说,GDB会根据变量的类型输出变量的值。但你也可以自定义GDB的输出的格式。例如,你想输出一个整数的十六进制,或是二进制来查看这个整型变量的中的位的情况。要做到这样,你可以使用GDB的数据显示格式:
x 按十六进制格式显示变量。
d 按十进制格式显示变量。
u 按十六进制格式显示无符号整型。
o 按八进制格式显示变量。
t 按二进制格式显示变量。
a 按十六进制格式显示变量。
c 按字符格式显示变量。
f 按浮点数格式显示变量。
(gdb) p i
$21 = 101
(gdb) p/a i
$22 = 0x65
(gdb) p/c i
$23 = 101 'e'
(gdb) p/f i
$24 = 1.41531145e-43
(gdb) p/x i
$25 = 0x65
(gdb) p/t i
$26 = 1100101
五、查看内存
你可以使用examine命令(简写是x)来查看内存地址中的值。x命令的语法如下所示:
x/<n/f/u> <addr>
n、f、u是可选的参数。
n 是一个正整数,表示显示内存的长度,也就是说从当前地址向后显示几个地址的内容。
f 表示显示的格式,参见上面。如果地址所指的是字符串,那么格式可以是s,如果地十是指令地址,那么格式可以是i。
u 表示从当前地址往后请求的字节数,如果不指定的话,GDB默认是4个bytes。u参数可以用下面的字符来代替,b表示单字节,h表示双字节,w表示四字节,g表示八字节。当我们指定了字节长度后,GDB会从指内存定的内存地址开始,读写指定字节,并把其当作一个值取出来。
<addr>表示一个内存地址。
n/f/u三个参数可以一起使用。例如:
命令:x/3uh 0x54320 表示,从内存地址0x54320读取内容,h表示以双字节为一个单位,3表示三个单位,u表示按十六进制显示。
六、自动显示
你可以设置一些自动显示的变量,当程序停住时,或是在你单步跟踪时,这些变量会自动显示。相关的GDB命令是display。
display <expr>
display/<fmt> <expr>
display/<fmt> <addr>
expr是一个表达式,fmt表示显示的格式,addr表示内存地址,当你用display设定好了一个或多个表达式后,只要你的程序被停下来,GDB会自动显示你所设置的这些表达式的值。
格式i和s同样被display支持,一个非常有用的命令是:
display/i $pc
$pc是GDB的环境变量,表示着指令的地址,/i则表示输出格式为机器指令码,也就是汇编。于是当程序停下后,就会出现源代码和机器指令码相对应的情形,这是一个很有意思的功能。
下面是一些和display相关的GDB命令:
undisplay <dnums...>
delete display <dnums...>
删除自动显示,dnums意为所设置好了的自动显式的编号。如果要同时删除几个,编号可以用空格分隔,如果要删除一个范围内的编号,可以用减号表示(如:2-5)
disable display <dnums...>
enable display <dnums...>
disable和enalbe不删除自动显示的设置,而只是让其失效和恢复。
info display
查看display设置的自动显示的信息。GDB会打出一张表格,向你报告当然调试中设置了多少个自动显示设置,其中包括,设置的编号,表达式,是否enable。
本文转自:http://blog.csdn.net/haoel/article/details/2883
posted @
2013-11-28 12:14 王海光 阅读(485) |
评论 (0) |
编辑 收藏查看栈信息
—————
当程序被停住了,你需要做的第一件事就是查看程序是在哪里停住的。当你的程序调用了一个函数,函数的地址,函数参数,函数内的局部变量都会被压入“栈”(Stack)中。你可以用GDB命令来查看当前的栈中的信息。
下面是一些查看函数调用栈信息的GDB命令:
backtrace
bt
打印当前的函数调用栈的所有信息。如:
(gdb) bt
#0 func (n=250) at tst.c:6
#1 0x08048524 in main (argc=1, argv=0xbffff674) at tst.c:30
#2 0x400409ed in __libc_start_main () from /lib/libc.so.6
从上可以看出函数的调用栈信息:__libc_start_main --> main() --> func()
backtrace <n>
bt <n>
n是一个正整数,表示只打印栈顶上n层的栈信息。
backtrace <-n>
bt <-n>
-n表一个负整数,表示只打印栈底下n层的栈信息。
如果你要查看某一层的信息,你需要在切换当前的栈,一般来说,程序停止时,最顶层的栈就是当前栈,如果你要查看栈下面层的详细信息,首先要做的是切换当前栈。
frame <n>
f <n>
n是一个从0开始的整数,是栈中的层编号。比如:frame 0,表示栈顶,frame 1,表示栈的第二层。
up <n>
表示向栈的上面移动n层,可以不打n,表示向上移动一层。
down <n>
表示向栈的下面移动n层,可以不打n,表示向下移动一层。
上面的命令,都会打印出移动到的栈层的信息。如果你不想让其打出信息。你可以使用这三个命令:
select-frame <n> 对应于 frame 命令。
up-silently <n> 对应于 up 命令。
down-silently <n> 对应于 down 命令。
查看当前栈层的信息,你可以用以下GDB命令:
frame 或 f
会打印出这些信息:栈的层编号,当前的函数名,函数参数值,函数所在文件及行号,函数执行到的语句。
info frame
info f
这个命令会打印出更为详细的当前栈层的信息,只不过,大多数都是运行时的内内地址。比如:函数地址,调用函数的地址,被调用函数的地址,目前的函数是由什么样的程序语言写成的、函数参数地址及值、局部变量的地址等等。如:
(gdb) info f
Stack level 0, frame at 0xbffff5d4:
eip = 0x804845d in func (tst.c:6); saved eip 0x8048524
called by frame at 0xbffff60c
source language c.
Arglist at 0xbffff5d4, args: n=250
Locals at 0xbffff5d4, Previous frame's sp is 0x0
Saved registers:
ebp at 0xbffff5d4, eip at 0xbffff5d8
info args
打印出当前函数的参数名及其值。
info locals
打印出当前函数中所有局部变量及其值。
info catch
打印出当前的函数中的异常处理信息。
查看源程序
—————
一、显示源代码
GDB 可以打印出所调试程序的源代码,当然,在程序编译时一定要加上-g的参数,把源程序信息编译到执行文件中。不然就看不到源程序了。当程序停下来以后,GDB会报告程序停在了那个文件的第几行上。你可以用list命令来打印程序的源代码。还是来看一看查看源代码的GDB命令吧。
list <linenum>
显示程序第linenum行的周围的源程序。
list <function>
显示函数名为function的函数的源程序。
list
显示当前行后面的源程序。
list -
显示当前行前面的源程序。
一般是打印当前行的上5行和下5行,如果显示函数是是上2行下8行,默认是10行,当然,你也可以定制显示的范围,使用下面命令可以设置一次显示源程序的行数。
set listsize <count>
设置一次显示源代码的行数。
show listsize
查看当前listsize的设置。
list命令还有下面的用法:
list <first>, <last>
显示从first行到last行之间的源代码。
list , <last>
显示从当前行到last行之间的源代码。
list +
往后显示源代码。
一般来说在list后面可以跟以下这们的参数:
<linenum> 行号。
<+offset> 当前行号的正偏移量。
<-offset> 当前行号的负偏移量。
<filename:linenum> 哪个文件的哪一行。
<function> 函数名。
<filename:function> 哪个文件中的哪个函数。
<*address> 程序运行时的语句在内存中的地址。
二、搜索源代码
不仅如此,GDB还提供了源代码搜索的命令:
forward-search <regexp>
search <regexp>
向前面搜索。
reverse-search <regexp>
全部搜索。
其中,<regexp>就是正则表达式,也主一个字符串的匹配模式,关于正则表达式,我就不在这里讲了,还请各位查看相关资料。
三、指定源文件的路径
某些时候,用-g编译过后的执行程序中只是包括了源文件的名字,没有路径名。GDB提供了可以让你指定源文件的路径的命令,以便GDB进行搜索。
directory <dirname ... >
dir <dirname ... >
加一个源文件路径到当前路径的前面。如果你要指定多个路径,UNIX下你可以使用“:”,Windows下你可以使用“;”。
directory
清除所有的自定义的源文件搜索路径信息。
show directories
显示定义了的源文件搜索路径。
四、源代码的内存
你可以使用info line命令来查看源代码在内存中的地址。info line后面可以跟“行号”,“函数名”,“文件名:行号”,“文件名:函数名”,这个命令会打印出所指定的源码在运行时的内存地址,如:
(gdb) info line tst.c:func
Line 5 of "tst.c" starts at address 0x8048456 <func+6> and ends at 0x804845d <func+13>.
还有一个命令(disassemble)你可以查看源程序的当前执行时的机器码,这个命令会把目前内存中的指令dump出来。如下面的示例表示查看函数func的汇编代码。
(gdb) disassemble func
Dump of assembler code for function func:
0x8048450 <func>: push %ebp
0x8048451 <func+1>: mov %esp,%ebp
0x8048453 <func+3>: sub $0x18,%esp
0x8048456 <func+6>: movl $0x0,0xfffffffc(%ebp)
0x804845d <func+13>: movl $0x1,0xfffffff8(%ebp)
0x8048464 <func+20>: mov 0xfffffff8(%ebp),%eax
0x8048467 <func+23>: cmp 0x8(%ebp),%eax
0x804846a <func+26>: jle 0x8048470 <func+32>
0x804846c <func+28>: jmp 0x8048480 <func+48>
0x804846e <func+30>: mov %esi,%esi
0x8048470 <func+32>: mov 0xfffffff8(%ebp),%eax
0x8048473 <func+35>: add %eax,0xfffffffc(%ebp)
0x8048476 <func+38>: incl 0xfffffff8(%ebp)
0x8048479 <func+41>: jmp 0x8048464 <func+20>
0x804847b <func+43>: nop
0x804847c <func+44>: lea 0x0(%esi,1),%esi
0x8048480 <func+48>: mov 0xfffffffc(%ebp),%edx
0x8048483 <func+51>: mov %edx,%eax
0x8048485 <func+53>: jmp 0x8048487 <func+55>
0x8048487 <func+55>: mov %ebp,%esp
0x8048489 <func+57>: pop %ebp
0x804848a <func+58>: ret
End of assembler dump.
本文转自:http://blog.csdn.net/haoel/article/details/2882
posted @
2013-11-28 12:12 王海光 阅读(414) |
评论 (0) |
编辑 收藏四、维护停止点
上面说了如何设置程序的停止点,GDB中的停止点也就是上述的三类。在GDB中,如果你觉得已定义好的停止点没有用了,你可以使用delete、clear、disable、enable这几个命令来进行维护。
clear
清除所有的已定义的停止点。
clear <function>
clear <filename:function>
清除所有设置在函数上的停止点。
clear <linenum>
clear <filename:linenum>
清除所有设置在指定行上的停止点。
delete [breakpoints] [range...]
删除指定的断点,breakpoints为断点号。如果不指定断点号,则表示删除所有的断点。range 表示断点号的范围(如:3-7)。其简写命令为d。
比删除更好的一种方法是disable停止点,disable了的停止点,GDB不会删除,当你还需要时,enable即可,就好像回收站一样。
disable [breakpoints] [range...]
disable所指定的停止点,breakpoints为停止点号。如果什么都不指定,表示disable所有的停止点。简写命令是dis.
enable [breakpoints] [range...]
enable所指定的停止点,breakpoints为停止点号。
enable [breakpoints] once range...
enable所指定的停止点一次,当程序停止后,该停止点马上被GDB自动disable。
enable [breakpoints] delete range...
enable所指定的停止点一次,当程序停止后,该停止点马上被GDB自动删除。
五、停止条件维护
前面在说到设置断点时,我们提到过可以设置一个条件,当条件成立时,程序自动停止,这是一个非常强大的功能,这里,我想专门说说这个条件的相关维护命令。一般来说,为断点设置一个条件,我们使用if关键词,后面跟其断点条件。并且,条件设置好后,我们可以用condition命令来修改断点的条件。(只有break和watch命令支持if,catch目前暂不支持if)
condition <bnum> <expression>
修改断点号为bnum的停止条件为expression。
condition <bnum>
清除断点号为bnum的停止条件。
还有一个比较特殊的维护命令ignore,你可以指定程序运行时,忽略停止条件几次。
ignore <bnum> <count>
表示忽略断点号为bnum的停止条件count次。
六、为停止点设定运行命令
我们可以使用GDB提供的command命令来设置停止点的运行命令。也就是说,当运行的程序在被停止住时,我们可以让其自动运行一些别的命令,这很有利行自动化调试。对基于GDB的自动化调试是一个强大的支持。
commands [bnum]
... command-list ...
end
为断点号bnum指写一个命令列表。当程序被该断点停住时,gdb会依次运行命令列表中的命令。
例如:
break foo if x>0
commands
printf "x is %d/n",x
continue
end
断点设置在函数foo中,断点条件是x>0,如果程序被断住后,也就是,一旦x的值在foo函数中大于0,GDB会自动打印出x的值,并继续运行程序。
如果你要清除断点上的命令序列,那么只要简单的执行一下commands命令,并直接在打个end就行了。
七、断点菜单
在C++中,可能会重复出现同一个名字的函数若干次(函数重载),在这种情况下,break <function>不能告诉GDB要停在哪个函数的入口。当然,你可以使用break <function(type)>也就是把函数的参数类型告诉GDB,以指定一个函数。否则的话,GDB会给你列出一个断点菜单供你选择你所需要的断点。你只要输入你菜单列表中的编号就可以了。如:
(gdb) b String::after
[0] cancel
[1] all
[2] file:String.cc; line number:867
[3] file:String.cc; line number:860
[4] file:String.cc; line number:875
[5] file:String.cc; line number:853
[6] file:String.cc; line number:846
[7] file:String.cc; line number:735
> 2 4 6
Breakpoint 1 at 0xb26c: file String.cc, line 867.
Breakpoint 2 at 0xb344: file String.cc, line 875.
Breakpoint 3 at 0xafcc: file String.cc, line 846.
Multiple breakpoints were set.
Use the "delete" command to delete unwanted
breakpoints.
(gdb)
可见,GDB列出了所有after的重载函数,你可以选一下列表编号就行了。0表示放弃设置断点,1表示所有函数都设置断点。
八、恢复程序运行和单步调试
当程序被停住了,你可以用continue命令恢复程序的运行直到程序结束,或下一个断点到来。也可以使用step或next命令单步跟踪程序。
continue [ignore-count]
c [ignore-count]
fg [ignore-count]
恢复程序运行,直到程序结束,或是下一个断点到来。ignore-count表示忽略其后的断点次数。continue,c,fg三个命令都是一样的意思。
step <count>
单步跟踪,如果有函数调用,他会进入该函数。进入函数的前提是,此函数被编译有debug信息。很像VC等工具中的step in。后面可以加count也可以不加,不加表示一条条地执行,加表示执行后面的count条指令,然后再停住。
next <count>
同样单步跟踪,如果有函数调用,他不会进入该函数。很像VC等工具中的step over。后面可以加count也可以不加,不加表示一条条地执行,加表示执行后面的count条指令,然后再停住。
set step-mode
set step-mode on
打开step-mode模式,于是,在进行单步跟踪时,程序不会因为没有debug信息而不停住。这个参数有很利于查看机器码。
set step-mod off
关闭step-mode模式。
finish
运行程序,直到当前函数完成返回。并打印函数返回时的堆栈地址和返回值及参数值等信息。
until 或 u
当你厌倦了在一个循环体内单步跟踪时,这个命令可以运行程序直到退出循环体。
stepi 或 si
nexti 或 ni
单步跟踪一条机器指令!一条程序代码有可能由数条机器指令完成,stepi和nexti可以单步执行机器指令。与之一样有相同功能的命令是“display/i $pc” ,当运行完这个命令后,单步跟踪会在打出程序代码的同时打出机器指令(也就是汇编代码)
九、信号(Signals)
信号是一种软中断,是一种处理异步事件的方法。一般来说,操作系统都支持许多信号。尤其是UNIX,比较重要应用程序一般都会处理信号。UNIX定义了许多信号,比如SIGINT表示中断字符信号,也就是Ctrl+C的信号,SIGBUS表示硬件故障的信号;SIGCHLD表示子进程状态改变信号;SIGKILL表示终止程序运行的信号,等等。信号量编程是UNIX下非常重要的一种技术。
GDB有能力在你调试程序的时候处理任何一种信号,你可以告诉GDB需要处理哪一种信号。你可以要求GDB收到你所指定的信号时,马上停住正在运行的程序,以供你进行调试。你可以用GDB的handle命令来完成这一功能。
handle <signal> <keywords...>
在GDB中定义一个信号处理。信号<signal>可以以SIG开头或不以SIG开头,可以用定义一个要处理信号的范围(如:SIGIO-SIGKILL,表示处理从SIGIO信号到SIGKILL的信号,其中包括SIGIO,SIGIOT,SIGKILL三个信号),也可以使用关键字all来标明要处理所有的信号。一旦被调试的程序接收到信号,运行程序马上会被GDB停住,以供调试。其<keywords>可以是以下几种关键字的一个或多个。
nostop
当被调试的程序收到信号时,GDB不会停住程序的运行,但会打出消息告诉你收到这种信号。
stop
当被调试的程序收到信号时,GDB会停住你的程序。
print
当被调试的程序收到信号时,GDB会显示出一条信息。
noprint
当被调试的程序收到信号时,GDB不会告诉你收到信号的信息。
pass
noignore
当被调试的程序收到信号时,GDB不处理信号。这表示,GDB会把这个信号交给被调试程序会处理。
nopass
ignore
当被调试的程序收到信号时,GDB不会让被调试程序来处理这个信号。
info signals
info handle
查看有哪些信号在被GDB检测中。
十、线程(Thread Stops)
如果你程序是多线程的话,你可以定义你的断点是否在所有的线程上,或是在某个特定的线程。GDB很容易帮你完成这一工作。
break <linespec> thread <threadno>
break <linespec> thread <threadno> if ...
linespec指定了断点设置在的源程序的行号。threadno指定了线程的ID,注意,这个ID是GDB分配的,你可以通过“info threads”命令来查看正在运行程序中的线程信息。如果你不指定thread <threadno>则表示你的断点设在所有线程上面。你还可以为某线程指定断点条件。如:
(gdb) break frik.c:13 thread 28 if bartab > lim
当你的程序被GDB停住时,所有的运行线程都会被停住。这方便你你查看运行程序的总体情况。而在你恢复程序运行时,所有的线程也会被恢复运行。那怕是主进程在被单步调试时。
本文转自:http://blog.csdn.net/haoel/article/details/2881
posted @
2013-11-28 12:08 王海光 阅读(509) |
评论 (0) |
编辑 收藏GDB的命令概貌
———————
启动gdb后,就你被带入gdb的调试环境中,就可以使用gdb的命令开始调试程序了,gdb的命令可以使用help命令来查看,如下所示:
/home/hchen> gdb
GNU gdb 5.1.1
Copyright 2002 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and you are
welcome to change it and/or distribute copies of it under certain conditions.
Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type "show warranty" for details.
This GDB was configured as "i386-suse-linux".
(gdb) help
List of classes of commands:
aliases -- Aliases of other commands
breakpoints -- Making program stop at certain points
data -- Examining data
files -- Specifying and examining files
internals -- Maintenance commands
obscure -- Obscure features
running -- Running the program
stack -- Examining the stack
status -- Status inquiries
support -- Support facilities
tracepoints -- Tracing of program execution without stopping the program
user-defined -- User-defined commands
Type "help" followed by a class name for a list of commands in that class.
Type "help" followed by command name for full documentation.
Command name abbreviations are allowed if unambiguous.
(gdb)
gdb的命令很多,gdb把之分成许多个种类。help命令只是例出gdb的命令种类,如果要看种类中的命令,可以使用help <class> 命令,如:help breakpoints,查看设置断点的所有命令。也可以直接help <command>来查看命令的帮助。
gdb中,输入命令时,可以不用打全命令,只用打命令的前几个字符就可以了,当然,命令的前几个字符应该要标志着一个唯一的命令,在Linux下,你可以敲击两次TAB键来补齐命令的全称,如果有重复的,那么gdb会把其例出来。
示例一:在进入函数func时,设置一个断点。可以敲入break func,或是直接就是b func
(gdb) b func
Breakpoint 1 at 0x8048458: file hello.c, line 10.
示例二:敲入b按两次TAB键,你会看到所有b打头的命令:
(gdb) b
backtrace break bt
(gdb)
示例三:只记得函数的前缀,可以这样:
(gdb) b make_ <按TAB键>
(再按下一次TAB键,你会看到:)
make_a_section_from_file make_environ
make_abs_section make_function_type
make_blockvector make_pointer_type
make_cleanup make_reference_type
make_command make_symbol_completion_list
(gdb) b make_
GDB把所有make开头的函数全部例出来给你查看。
示例四:调试C++的程序时,有可以函数名一样。如:
(gdb) b 'bubble( M-?
bubble(double,double) bubble(int,int)
(gdb) b 'bubble(
你可以查看到C++中的所有的重载函数及参数。(注:M-?和“按两次TAB键”是一个意思)
要退出gdb时,只用发quit或命令简称q就行了。
GDB中运行UNIX的shell程序
————————————
在gdb环境中,你可以执行UNIX的shell的命令,使用gdb的shell命令来完成:
shell <command string>
调用UNIX的shell来执行<command string>,环境变量SHELL中定义的UNIX的shell将会被用来执行<command string>,如果SHELL没有定义,那就使用UNIX的标准shell:/bin/sh。(在Windows中使用Command.com或cmd.exe)
还有一个gdb命令是make:
make <make-args>
可以在gdb中执行make命令来重新build自己的程序。这个命令等价于“shell make <make-args>”。
在GDB中运行程序
————————
当以gdb <program>方式启动gdb后,gdb会在PATH路径和当前目录中搜索<program>的源文件。如要确认gdb是否读到源文件,可使用l或list命令,看看gdb是否能列出源代码。
在gdb中,运行程序使用r或是run命令。程序的运行,你有可能需要设置下面四方面的事。
1、程序运行参数。
set args 可指定运行时参数。(如:set args 10 20 30 40 50)
show args 命令可以查看设置好的运行参数。
2、运行环境。
path <dir> 可设定程序的运行路径。
show paths 查看程序的运行路径。
set environment varname [=value] 设置环境变量。如:set env USER=hchen
show environment [varname] 查看环境变量。
3、工作目录。
cd <dir> 相当于shell的cd命令。
pwd 显示当前的所在目录。
4、程序的输入输出。
info terminal 显示你程序用到的终端的模式。
使用重定向控制程序输出。如:run > outfile
tty命令可以指写输入输出的终端设备。如:tty /dev/ttyb
调试已运行的程序
————————
两种方法:
1、在UNIX下用ps查看正在运行的程序的PID(进程ID),然后用gdb <program> PID格式挂接正在运行的程序。
2、先用gdb <program>关联上源代码,并进行gdb,在gdb中用attach命令来挂接进程的PID。并用detach来取消挂接的进程。
暂停 / 恢复程序运行
—————————
调试程序中,暂停程序运行是必须的,GDB可以方便地暂停程序的运行。你可以设置程序的在哪行停住,在什么条件下停住,在收到什么信号时停往等等。以便于你查看运行时的变量,以及运行时的流程。
当进程被gdb停住时,你可以使用info program 来查看程序的是否在运行,进程号,被暂停的原因。
在gdb中,我们可以有以下几种暂停方式:断点(BreakPoint)、观察点(WatchPoint)、捕捉点(CatchPoint)、信号(Signals)、线程停止(Thread Stops)。如果要恢复程序运行,可以使用c或是continue命令。
一、设置断点(BreakPoint)
我们用break命令来设置断点。正面有几点设置断点的方法:
break <function>
在进入指定函数时停住。C++中可以使用class::function或function(type,type)格式来指定函数名。
break <linenum>
在指定行号停住。
break +offset
break -offset
在当前行号的前面或后面的offset行停住。offiset为自然数。
break filename:linenum
在源文件filename的linenum行处停住。
break filename:function
在源文件filename的function函数的入口处停住。
break *address
在程序运行的内存地址处停住。
break
break命令没有参数时,表示在下一条指令处停住。
break ... if <condition>
...可以是上述的参数,condition表示条件,在条件成立时停住。比如在循环境体中,可以设置break if i=100,表示当i为100时停住程序。
查看断点时,可使用info命令,如下所示:(注:n表示断点号)
info breakpoints [n]
info break [n]
二、设置观察点(WatchPoint)
观察点一般来观察某个表达式(变量也是一种表达式)的值是否有变化了,如果有变化,马上停住程序。我们有下面的几种方法来设置观察点:
watch <expr>
为表达式(变量)expr设置一个观察点。一量表达式值有变化时,马上停住程序。
rwatch <expr>
当表达式(变量)expr被读时,停住程序。
awatch <expr>
当表达式(变量)的值被读或被写时,停住程序。
info watchpoints
列出当前所设置了的所有观察点。
三、设置捕捉点(CatchPoint)
你可设置捕捉点来补捉程序运行时的一些事件。如:载入共享库(动态链接库)或是C++的异常。设置捕捉点的格式为:
catch <event>
当event发生时,停住程序。event可以是下面的内容:
1、throw 一个C++抛出的异常。(throw为关键字)
2、catch 一个C++捕捉到的异常。(catch为关键字)
3、exec 调用系统调用exec时。(exec为关键字,目前此功能只在HP-UX下有用)
4、fork 调用系统调用fork时。(fork为关键字,目前此功能只在HP-UX下有用)
5、vfork 调用系统调用vfork时。(vfork为关键字,目前此功能只在HP-UX下有用)
6、load 或 load <libname> 载入共享库(动态链接库)时。(load为关键字,目前此功能只在HP-UX下有用)
7、unload 或 unload <libname> 卸载共享库(动态链接库)时。(unload为关键字,目前此功能只在HP-UX下有用)
tcatch <event>
只设置一次捕捉点,当程序停住以后,应点被自动删除。
本文转自:http://blog.csdn.net/haoel/article/details/2880
posted @
2013-11-28 12:07 王海光 阅读(507) |
评论 (0) |
编辑 收藏用GDB调试程序
GDB概述
————
GDB是GNU开源组织发布的一个强大的UNIX下的程序调试工具。或许,各位比较喜欢那种图形界面方式的,像VC、BCB等IDE的调试,但如果你是在UNIX平台下做软件,你会发现GDB这个调试工具有比VC、BCB的图形化调试器更强大的功能。所谓“寸有所长,尺有所短”就是这个道理。
一般来说,GDB主要帮忙你完成下面四个方面的功能:
1、启动你的程序,可以按照你的自定义的要求随心所欲的运行程序。
2、可让被调试的程序在你所指定的调置的断点处停住。(断点可以是条件表达式)
3、当程序被停住时,可以检查此时你的程序中所发生的事。
4、动态的改变你程序的执行环境。
从上面看来,GDB和一般的调试工具没有什么两样,基本上也是完成这些功能,不过在细节上,你会发现GDB这个调试工具的强大,大家可能比较习惯了图形化的调试工具,但有时候,命令行的调试工具却有着图形化工具所不能完成的功能。让我们一一看来。
一个调试示例
——————
源程序:tst.c
#include <stdio.h>
int func(int n)
{
int sum=0,i;
for(i=0; i<n; i++)
{
sum+=i;
}
return sum;
}
main()
{
int i;
long result = 0;
for(i=1; i<=100; i++)
{
result += i;
}
printf("result[1-100] = %d /n", result );
printf("result[1-250] = %d /n", func(250) );
}
编译生成执行文件:(Linux下)
hchen/test> cc -g tst.c -o tst
使用GDB调试:
hchen/test> gdb tst <---------- 启动GDB
GNU gdb 5.1.1
Copyright 2002 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and you are
welcome to change it and/or distribute copies of it under certain conditions.
Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type "show warranty" for details.
This GDB was configured as "i386-suse-linux"
(gdb) l <-------------------- l命令相当于list,从第一行开始例出原码。
1 #include <stdio.h>
2
3 int func(int n)
4 {
5 int sum=0,i;
6 for(i=0; i<n; i++)
7 {
8 sum+=i;
9 }
10 return sum;
(gdb) <-------------------- 直接回车表示,重复上一次命令
11 }
12
13
14 main()
15 {
16 int i;
17 long result = 0;
18 for(i=1; i<=100; i++)
19 {
20 result += i;
(gdb) break 16 <-------------------- 设置断点,在源程序第16行处。
Breakpoint 1 at 0x8048496: file tst.c, line 16.
(gdb) break func <-------------------- 设置断点,在函数func()入口处。
Breakpoint 2 at 0x8048456: file tst.c, line 5.
(gdb) info break <-------------------- 查看断点信息。
Num Type Disp Enb Address What
1 breakpoint keep y 0x08048496 in main at tst.c:16
2 breakpoint keep y 0x08048456 in func at tst.c:5
(gdb) r <--------------------- 运行程序,run命令简写
Starting program: /home/hchen/test/tst
Breakpoint 1, main () at tst.c:17 <---------- 在断点处停住。
17 long result = 0;
(gdb) n <--------------------- 单条语句执行,next命令简写。
18 for(i=1; i<=100; i++)
(gdb) n
20 result += i;
(gdb) n
18 for(i=1; i<=100; i++)
(gdb) n
20 result += i;
(gdb) c <--------------------- 继续运行程序,continue命令简写。
Continuing.
result[1-100] = 5050 <----------程序输出。
Breakpoint 2, func (n=250) at tst.c:5
5 int sum=0,i;
(gdb) n
6 for(i=1; i<=n; i++)
(gdb) p i <--------------------- 打印变量i的值,print命令简写。
$1 = 134513808
(gdb) n
8 sum+=i;
(gdb) n
6 for(i=1; i<=n; i++)
(gdb) p sum
$2 = 1
(gdb) n
8 sum+=i;
(gdb) p i
$3 = 2
(gdb) n
6 for(i=1; i<=n; i++)
(gdb) p sum
$4 = 3
(gdb) bt <--------------------- 查看函数堆栈。
#0 func (n=250) at tst.c:5
#1 0x080484e4 in main () at tst.c:24
#2 0x400409ed in __libc_start_main () from /lib/libc.so.6
(gdb) finish <--------------------- 退出函数。
Run till exit from #0 func (n=250) at tst.c:5
0x080484e4 in main () at tst.c:24
24 printf("result[1-250] = %d /n", func(250) );
Value returned is $6 = 31375
(gdb) c <--------------------- 继续运行。
Continuing.
result[1-250] = 31375 <----------程序输出。
Program exited with code 027. <--------程序退出,调试结束。
(gdb) q <--------------------- 退出gdb。
hchen/test> 好了,有了以上的感性认识,还是让我们来系统地认识一下gdb吧。
使用GDB
————
一般来说GDB主要调试的是C/C++的程序。要调试C/C++的程序,首先在编译时,我们必须要把调试信息加到可执行文件中。使用编译器(cc/gcc/g++)的 -g 参数可以做到这一点。如:
> cc -g hello.c -o hello
> g++ -g hello.cpp -o hello
如果没有-g,你将看不见程序的函数名、变量名,所代替的全是运行时的内存地址。当你用-g把调试信息加入之后,并成功编译目标代码以后,让我们来看看如何用gdb来调试他。
启动GDB的方法有以下几种:
1、gdb <program>
program也就是你的执行文件,一般在当然目录下。
2、gdb <program> core
用gdb同时调试一个运行程序和core文件,core是程序非法执行后core dump后产生的文件。
3、gdb <program> <PID>
如果你的程序是一个服务程序,那么你可以指定这个服务程序运行时的进程ID。gdb会自动attach上去,并调试他。program应该在PATH环境变量中搜索得到。
GDB启动时,可以加上一些GDB的启动开关,详细的开关可以用gdb -help查看。我在下面只例举一些比较常用的参数:
-symbols <file>
-s <file>
从指定文件中读取符号表。
-se file
从指定文件中读取符号表信息,并把他用在可执行文件中。
-core <file>
-c <file>
调试时core dump的core文件。
-directory <directory>
-d <directory>
加入一个源文件的搜索路径。默认搜索路径是环境变量中PATH所定义的路径。
本文转自:http://blog.csdn.net/haoel/article/details/2879
posted @
2013-11-28 12:03 王海光 阅读(590) |
评论 (0) |
编辑 收藏软件开发是一个跨度很大的技术工作,在语言方面,有C,C++,Java,Ruby等等等等,在环境方面,又分嵌入式,桌面系统,企业级,WEB,基础系统,或是科学研究。但是,不管是什么的情况,总是有一些通用的基本职业技能。
这些最基本的职业技能通常决定了一个程序员的级别,能否用好这些技能,直接关系到了程序员的职业生涯。很多程序新手也是因为缺少、达不到或是不熟悉在这些基本技能,所以,他们需要有老手带,需要努力补齐这些技能。而高级程序员应该非常熟悉这些基本技能,而且有能力胜任并带领其他经验不足的程序员。
下面这些基本职业技术可以用来做为对一个程序员的评估,很明显,下面的这些技能都可以用来做面试。虽然,还有很多非技术的因素,但对于评估一个程序员的技术能力来说,其应该是足够的了。
下面是程序员所应该具备的基本职业技能:
| 基本技能 | 技能描述 |
|---|
| 阅读代码 | 这个技能需要程序员能够具备读懂已经存在的代码的能力,这样的能力可以让程序员分析程序的行为,了解程序,这样才能和开发团队一起工作,继承维护或是改进现有的程序。 |
| 编写程序 | 编写程序并不包括程序设计。不要以为编程是一件很简单的事情,很多程序员都认为编程只需要懂得程序语言的语法,并把设计实现就可以了。但是这离编写程序还远远不够,使用什么样的编码风格成为编写程序员最需要具备的基本技能。能否使用非常良好的编程风格直接决写了程序员的级别。 |
| 软件设计 | 这一能力直接决定了需要吏用什么样的代码技术达到怎么样的功能,而系统架构设计直接决定了软件的质量、性能和可维护性。并不是所有的程序在这一方面都非常优秀,但每个程序员都需要或多或少的明白和掌握这一基本技能。 |
| 熟悉软件工程 | 每个程序员都应该明白软件工程是什么东西,都应该知道,需求分析,设计,编码,测试,Release和维护这几个阶段。当然,几乎所有的人都知道这些东西,但并不是每个人都很清楚这些东西。现在很多高级程序员都会混淆“需求规格说明书FS”和“概要设计HLD”。另外,程序员还需要知道一些软件开发的方法论,比如:敏捷开发或瀑布模型。 |
| 使用程序库或框架 | 一个程序员需要学会使用已有的代码,无论是标论的程序库,或是第三方的,还是自己公司内部的,都需要学会做。比如:C++中,需要学会使用STL,MFC,ATL,BOOST,ACE,CPPUNIT等等。使用这些东西,可以让你的工作事半功倍。 |
| 程序调试 | 程序调试是分析BUG和解决问题最直接的能力。没有人能够保证程序写出来不用调试就可以运行正常,也没有人可以保证程序永远不会出BUG。所以,熟练使用调试器是一个程序员需要具备的基本技能。 |
| 使用IDE | 学会使用IDE工具也会让你的工作事半功倍。比如,VC++,Emacs,Eclipse等等,并要知道这些IDE的长处和短处。 |
| 使用版本控制 | 一定要学会使用版本控制工具,什么叫mainline/trunk,什么叫tag,什么叫branch,怎么做patch,怎么merge代码,怎么reverse,怎么利用版本控制工具维护不同版本的软件。这是程序员需要明的的软件配置管理中最重要的一块。 |
| 单元测试 | 单元测试是每个程序都需要做的。很多单元测试也是需要编码的。一定要学会在xUnit框架下进行单元测试。比如JUnit, NUnit, CppUnit等等。 |
| 重构代码 | 每个程序员都需要有最基本的能力去重构目前已有的代码,使代码达到最优但却不能影响任何的已有的功能。有一本书叫《软件的重构》,每个程序员都应该读一下。 |
| 自动化编译 | 程序员需要使用一个脚本,其能自动化编程所有的工程和代码,这样,整个开发团队可以不停地集成代码,自动化测试,自动化部署,以及使用一些工具进行静态代码分析或是自动化测试。 |
当然,还有很多的基本技术也是非常重要的,比如,与人的沟通能力,语言的表达能力,写作能力,团队协作能力,适应变化的能力,时间管理能力,多任务处理能力,自我学习能力,故障处理能力,等等,等等,这里只是列举了和技术相关的能力,这些是程序最最最基本的能力,只要是程序员就必需要有的能力。
本文转自:http://coolshell.cn/articles/428.html
posted @
2013-11-28 11:55 王海光 阅读(368) |
评论 (0) |
编辑 收藏今天,数据库的操作越来越成为整个应用的性能瓶颈了,这点对于Web应用尤其明显。关于数据库的性能,这并不只是DBA才需要担心的事,而这更是我们程序员需要去关注的事情。当我们去设计数据库表结构,对操作数据库时(尤其是查表时的SQL语句),我们都需要注意数据操作的性能。这里,我们不会讲过多的SQL语句的优化,而只是针对MySQL这一Web应用最多的数据库。希望下面的这些优化技巧对你有用。
1. 为查询缓存优化你的查询
大多数的MySQL服务器都开启了查询缓存。这是提高性最有效的方法之一,而且这是被MySQL的数据库引擎处理的。当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一个缓存中,这样,后续的相同的查询就不用操作表而直接访问缓存结果了。
这里最主要的问题是,对于程序员来说,这个事情是很容易被忽略的。因为,我们某些查询语句会让MySQL不使用缓存。请看下面的示例:
// 查询缓存不开启
$r = mysql_query("SELECT username FROM user WHERE signup_date >= CURDATE()");
// 开启查询缓存
$today = date("Y-m-d");
$r = mysql_query("SELECT username FROM user WHERE signup_date >= '$today'");
上面两条SQL语句的差别就是 CURDATE() ,MySQL的查询缓存对这个函数不起作用。所以,像 NOW() 和 RAND() 或是其它的诸如此类的SQL函数都不会开启查询缓存,因为这些函数的返回是会不定的易变的。所以,你所需要的就是用一个变量来代替MySQL的函数,从而开启缓存。
2. EXPLAIN 你的 SELECT 查询
使用 EXPLAIN 关键字可以让你知道MySQL是如何处理你的SQL语句的。这可以帮你分析你的查询语句或是表结构的性能瓶颈。
EXPLAIN 的查询结果还会告诉你你的索引主键被如何利用的,你的数据表是如何被搜索和排序的……等等,等等。
挑一个你的SELECT语句(推荐挑选那个最复杂的,有多表联接的),把关键字EXPLAIN加到前面。你可以使用phpmyadmin来做这个事。然后,你会看到一张表格。下面的这个示例中,我们忘记加上了group_id索引,并且有表联接:
当我们为 group_id 字段加上索引后:
我们可以看到,前一个结果显示搜索了 7883 行,而后一个只是搜索了两个表的 9 和 16 行。查看rows列可以让我们找到潜在的性能问题。
3. 当只要一行数据时使用 LIMIT 1
当你查询表的有些时候,你已经知道结果只会有一条结果,但因为你可能需要去fetch游标,或是你也许会去检查返回的记录数。
在这种情况下,加上 LIMIT 1 可以增加性能。这样一样,MySQL数据库引擎会在找到一条数据后停止搜索,而不是继续往后查少下一条符合记录的数据。
下面的示例,只是为了找一下是否有“中国”的用户,很明显,后面的会比前面的更有效率。(请注意,第一条中是Select *,第二条是Select 1)
// 没有效率的:
$r = mysql_query("SELECT * FROM user WHERE country = 'China'");
if (mysql_num_rows($r) > 0) {
//
}
// 有效率的:
$r = mysql_query("SELECT 1 FROM user WHERE country = 'China' LIMIT 1");
if (mysql_num_rows($r) > 0) {
//
} 4. 为搜索字段建索引
索引并不一定就是给主键或是唯一的字段。如果在你的表中,有某个字段你总要会经常用来做搜索,那么,请为其建立索引吧。
从上图你可以看到那个搜索字串 “last_name LIKE ‘a%’”,一个是建了索引,一个是没有索引,性能差了4倍左右。
另外,你应该也需要知道什么样的搜索是不能使用正常的索引的。例如,当你需要在一篇大的文章中搜索一个词时,如: “WHERE post_content LIKE ‘%apple%’”,索引可能是没有意义的。你可能需要使用MySQL全文索引 或是自己做一个索引(比如说:搜索关键词或是Tag什么的)
5. 在Join表的时候使用相当类型的例,并将其索引
如果你的应用程序有很多 JOIN 查询,你应该确认两个表中Join的字段是被建过索引的。这样,MySQL内部会启动为你优化Join的SQL语句的机制。
而且,这些被用来Join的字段,应该是相同的类型的。例如:如果你要把 DECIMAL 字段和一个 INT 字段Join在一起,MySQL就无法使用它们的索引。对于那些STRING类型,还需要有相同的字符集才行。(两个表的字符集有可能不一样)
// 在state中查找company
$r = mysql_query("SELECT company_name FROM users
LEFT JOIN companies ON (users.state = companies.state)
WHERE users.id = $user_id");
// 两个 state 字段应该是被建过索引的,而且应该是相当的类型,相同的字符集。
6. 千万不要 ORDER BY RAND()
想打乱返回的数据行?随机挑一个数据?真不知道谁发明了这种用法,但很多新手很喜欢这样用。但你确不了解这样做有多么可怕的性能问题。
如果你真的想把返回的数据行打乱了,你有N种方法可以达到这个目的。这样使用只让你的数据库的性能呈指数级的下降。这里的问题是:MySQL会不得不去执行RAND()函数(很耗CPU时间),而且这是为了每一行记录去记行,然后再对其排序。就算是你用了Limit 1也无济于事(因为要排序)
下面的示例是随机挑一条记录
// 千万不要这样做:
$r = mysql_query("SELECT username FROM user ORDER BY RAND() LIMIT 1");
// 这要会更好:
$r = mysql_query("SELECT count(*) FROM user");
$d = mysql_fetch_row($r);
$rand = mt_rand(0,$d[0] - 1);
$r = mysql_query("SELECT username FROM user LIMIT $rand, 1");
7. 避免 SELECT *
从数据库里读出越多的数据,那么查询就会变得越慢。并且,如果你的数据库服务器和WEB服务器是两台独立的服务器的话,这还会增加网络传输的负载。
所以,你应该养成一个需要什么就取什么的好的习惯。
// 不推荐
$r = mysql_query("SELECT * FROM user WHERE user_id = 1");
$d = mysql_fetch_assoc($r);
echo "Welcome {$d['username']}";
// 推荐
$r = mysql_query("SELECT username FROM user WHERE user_id = 1");
$d = mysql_fetch_assoc($r);
echo "Welcome {$d['username']}";
8. 永远为每张表设置一个ID
我们应该为数据库里的每张表都设置一个ID做为其主键,而且最好的是一个INT型的(推荐使用UNSIGNED),并设置上自动增加的AUTO_INCREMENT标志。
就算是你 users 表有一个主键叫 “email”的字段,你也别让它成为主键。使用 VARCHAR 类型来当主键会使用得性能下降。另外,在你的程序中,你应该使用表的ID来构造你的数据结构。
而且,在MySQL数据引擎下,还有一些操作需要使用主键,在这些情况下,主键的性能和设置变得非常重要,比如,集群,分区……
在这里,只有一个情况是例外,那就是“关联表”的“外键”,也就是说,这个表的主键,通过若干个别的表的主键构成。我们把这个情况叫做“外键”。比如:有一个“学生表”有学生的ID,有一个“课程表”有课程ID,那么,“成绩表”就是“关联表”了,其关联了学生表和课程表,在成绩表中,学生ID和课程ID叫“外键”其共同组成主键。
9. 使用 ENUM 而不是 VARCHAR
ENUM 类型是非常快和紧凑的。在实际上,其保存的是 TINYINT,但其外表上显示为字符串。这样一来,用这个字段来做一些选项列表变得相当的完美。
如果你有一个字段,比如“性别”,“国家”,“民族”,“状态”或“部门”,你知道这些字段的取值是有限而且固定的,那么,你应该使用 ENUM 而不是 VARCHAR。
MySQL也有一个“建议”(见第十条)告诉你怎么去重新组织你的表结构。当你有一个 VARCHAR 字段时,这个建议会告诉你把其改成 ENUM 类型。使用 PROCEDURE ANALYSE() 你可以得到相关的建议。
10. 从 PROCEDURE ANALYSE() 取得建议
PROCEDURE ANALYSE() 会让 MySQL 帮你去分析你的字段和其实际的数据,并会给你一些有用的建议。只有表中有实际的数据,这些建议才会变得有用,因为要做一些大的决定是需要有数据作为基础的。
例如,如果你创建了一个 INT 字段作为你的主键,然而并没有太多的数据,那么,PROCEDURE ANALYSE()会建议你把这个字段的类型改成 MEDIUMINT 。或是你使用了一个 VARCHAR 字段,因为数据不多,你可能会得到一个让你把它改成 ENUM 的建议。这些建议,都是可能因为数据不够多,所以决策做得就不够准。
在phpmyadmin里,你可以在查看表时,点击 “Propose table structure” 来查看这些建议
一定要注意,这些只是建议,只有当你的表里的数据越来越多时,这些建议才会变得准确。一定要记住,你才是最终做决定的人。
11. 尽可能的使用 NOT NULL
除非你有一个很特别的原因去使用 NULL 值,你应该总是让你的字段保持 NOT NULL。这看起来好像有点争议,请往下看。
首先,问问你自己“Empty”和“NULL”有多大的区别(如果是INT,那就是0和NULL)?如果你觉得它们之间没有什么区别,那么你就不要使用NULL。(你知道吗?在 Oracle 里,NULL 和 Empty 的字符串是一样的!)
不要以为 NULL 不需要空间,其需要额外的空间,并且,在你进行比较的时候,你的程序会更复杂。 当然,这里并不是说你就不能使用NULL了,现实情况是很复杂的,依然会有些情况下,你需要使用NULL值。
下面摘自MySQL自己的文档:
“NULL columns require additional space in the row to record whether their values are NULL. For MyISAM tables, each NULL column takes one bit extra, rounded up to the nearest byte.”
12. Prepared Statements
Prepared Statements很像存储过程,是一种运行在后台的SQL语句集合,我们可以从使用 prepared statements 获得很多好处,无论是性能问题还是安全问题。
Prepared Statements 可以检查一些你绑定好的变量,这样可以保护你的程序不会受到“SQL注入式”攻击。当然,你也可以手动地检查你的这些变量,然而,手动的检查容易出问题,而且很经常会被程序员忘了。当我们使用一些framework或是ORM的时候,这样的问题会好一些。
在性能方面,当一个相同的查询被使用多次的时候,这会为你带来可观的性能优势。你可以给这些Prepared Statements定义一些参数,而MySQL只会解析一次。
虽然最新版本的MySQL在传输Prepared Statements是使用二进制形势,所以这会使得网络传输非常有效率。
当然,也有一些情况下,我们需要避免使用Prepared Statements,因为其不支持查询缓存。但据说版本5.1后支持了。
在PHP中要使用prepared statements,你可以查看其使用手册:mysqli 扩展 或是使用数据库抽象层,如: PDO.
// 创建 prepared statement
if ($stmt = $mysqli->prepare("SELECT username FROM user WHERE state=?")) {
// 绑定参数
$stmt->bind_param("s", $state);
// 执行
$stmt->execute();
// 绑定结果
$stmt->bind_result($username);
// 移动游标
$stmt->fetch();
printf("%s is from %s\n", $username, $state);
$stmt->close();
}
13. 无缓冲的查询
正常的情况下,当你在当你在你的脚本中执行一个SQL语句的时候,你的程序会停在那里直到没这个SQL语句返回,然后你的程序再往下继续执行。你可以使用无缓冲查询来改变这个行为。
关于这个事情,在PHP的文档中有一个非常不错的说明: mysql_unbuffered_query() 函数:
“mysql_unbuffered_query() sends the SQL query query to MySQL without automatically fetching and buffering the result rows as mysql_query() does. This saves a considerable amount of memory with SQL queries that produce large result sets, and you can start working on the result set immediately after the first row has been retrieved as you don’t have to wait until the complete SQL query has been performed.”
上面那句话翻译过来是说,mysql_unbuffered_query() 发送一个SQL语句到MySQL而并不像mysql_query()一样去自动fethch和缓存结果。这会相当节约很多可观的内存,尤其是那些会产生大量结果的查询语句,并且,你不需要等到所有的结果都返回,只需要第一行数据返回的时候,你就可以开始马上开始工作于查询结果了。
然而,这会有一些限制。因为你要么把所有行都读走,或是你要在进行下一次的查询前调用mysql_free_result() 清除结果。而且, mysql_num_rows() 或 mysql_data_seek() 将无法使用。所以,是否使用无缓冲的查询你需要仔细考虑。
14. 把IP地址存成 UNSIGNED INT
很多程序员都会创建一个 VARCHAR(15) 字段来存放字符串形式的IP而不是整形的IP。如果你用整形来存放,只需要4个字节,并且你可以有定长的字段。而且,这会为你带来查询上的优势,尤其是当你需要使用这样的WHERE条件:IP between ip1 and ip2。
我们必需要使用UNSIGNED INT,因为 IP地址会使用整个32位的无符号整形。
而你的查询,你可以使用 INET_ATON() 来把一个字符串IP转成一个整形,并使用 INET_NTOA() 把一个整形转成一个字符串IP。在PHP中,也有这样的函数 ip2long() 和 long2ip()。
$r = "UPDATE users SET ip = INET_ATON('{$_SERVER['REMOTE_ADDR']}') WHERE user_id = $user_id";
15. 固定长度的表会更快
如果表中的所有字段都是“固定长度”的,整个表会被认为是 “static” 或 “fixed-length”。 例如,表中没有如下类型的字段: VARCHAR,TEXT,BLOB。只要你包括了其中一个这些字段,那么这个表就不是“固定长度静态表”了,这样,MySQL 引擎会用另一种方法来处理。
固定长度的表会提高性能,因为MySQL搜寻得会更快一些,因为这些固定的长度是很容易计算下一个数据的偏移量的,所以读取的自然也会很快。而如果字段不是定长的,那么,每一次要找下一条的话,需要程序找到主键。
并且,固定长度的表也更容易被缓存和重建。不过,唯一的副作用是,固定长度的字段会浪费一些空间,因为定长的字段无论你用不用,他都是要分配那么多的空间。
使用“垂直分割”技术(见下一条),你可以分割你的表成为两个一个是定长的,一个则是不定长的。
16. 垂直分割
“垂直分割”是一种把数据库中的表按列变成几张表的方法,这样可以降低表的复杂度和字段的数目,从而达到优化的目的。(以前,在银行做过项目,见过一张表有100多个字段,很恐怖)
示例一:在Users表中有一个字段是家庭地址,这个字段是可选字段,相比起,而且你在数据库操作的时候除了个人信息外,你并不需要经常读取或是改写这个字段。那么,为什么不把他放到另外一张表中呢? 这样会让你的表有更好的性能,大家想想是不是,大量的时候,我对于用户表来说,只有用户ID,用户名,口令,用户角色等会被经常使用。小一点的表总是会有好的性能。
示例二: 你有一个叫 “last_login” 的字段,它会在每次用户登录时被更新。但是,每次更新时会导致该表的查询缓存被清空。所以,你可以把这个字段放到另一个表中,这样就不会影响你对用户ID,用户名,用户角色的不停地读取了,因为查询缓存会帮你增加很多性能。
另外,你需要注意的是,这些被分出去的字段所形成的表,你不会经常性地去Join他们,不然的话,这样的性能会比不分割时还要差,而且,会是极数级的下降。
17. 拆分大的 DELETE 或 INSERT 语句
如果你需要在一个在线的网站上去执行一个大的 DELETE 或 INSERT 查询,你需要非常小心,要避免你的操作让你的整个网站停止相应。因为这两个操作是会锁表的,表一锁住了,别的操作都进不来了。
Apache 会有很多的子进程或线程。所以,其工作起来相当有效率,而我们的服务器也不希望有太多的子进程,线程和数据库链接,这是极大的占服务器资源的事情,尤其是内存。
如果你把你的表锁上一段时间,比如30秒钟,那么对于一个有很高访问量的站点来说,这30秒所积累的访问进程/线程,数据库链接,打开的文件数,可能不仅仅会让你泊WEB服务Crash,还可能会让你的整台服务器马上掛了。
所以,如果你有一个大的处理,你定你一定把其拆分,使用 LIMIT 条件是一个好的方法。下面是一个示例:
while (1) {
//每次只做1000条
mysql_query("DELETE FROM logs WHERE log_date <= '2009-11-01' LIMIT 1000");
if (mysql_affected_rows() == 0) {
// 没得可删了,退出!
break;
}
// 每次都要休息一会儿
usleep(50000);
}
18. 越小的列会越快
对于大多数的数据库引擎来说,硬盘操作可能是最重大的瓶颈。所以,把你的数据变得紧凑会对这种情况非常有帮助,因为这减少了对硬盘的访问。
参看 MySQL 的文档 Storage Requirements 查看所有的数据类型。
如果一个表只会有几列罢了(比如说字典表,配置表),那么,我们就没有理由使用 INT 来做主键,使用 MEDIUMINT, SMALLINT 或是更小的 TINYINT 会更经济一些。如果你不需要记录时间,使用 DATE 要比 DATETIME 好得多。
当然,你也需要留够足够的扩展空间,不然,你日后来干这个事,你会死的很难看,参看Slashdot的例子(2009年11月06日),一个简单的ALTER TABLE语句花了3个多小时,因为里面有一千六百万条数据。
19. 选择正确的存储引擎
在 MySQL 中有两个存储引擎 MyISAM 和 InnoDB,每个引擎都有利有弊。酷壳以前文章《MySQL: InnoDB 还是 MyISAM?》讨论和这个事情。
MyISAM 适合于一些需要大量查询的应用,但其对于有大量写操作并不是很好。甚至你只是需要update一个字段,整个表都会被锁起来,而别的进程,就算是读进程都无法操作直到读操作完成。另外,MyISAM 对于 SELECT COUNT(*) 这类的计算是超快无比的。
InnoDB 的趋势会是一个非常复杂的存储引擎,对于一些小的应用,它会比 MyISAM 还慢。他是它支持“行锁” ,于是在写操作比较多的时候,会更优秀。并且,他还支持更多的高级应用,比如:事务。
下面是MySQL的手册
20. 使用一个对象关系映射器(Object Relational Mapper)
使用 ORM (Object Relational Mapper),你能够获得可靠的性能增涨。一个ORM可以做的所有事情,也能被手动的编写出来。但是,这需要一个高级专家。
ORM 的最重要的是“Lazy Loading”,也就是说,只有在需要的去取值的时候才会去真正的去做。但你也需要小心这种机制的副作用,因为这很有可能会因为要去创建很多很多小的查询反而会降低性能。
ORM 还可以把你的SQL语句打包成一个事务,这会比单独执行他们快得多得多。
目前,个人最喜欢的PHP的ORM是:Doctrine。
21. 小心“永久链接”
“永久链接”的目的是用来减少重新创建MySQL链接的次数。当一个链接被创建了,它会永远处在连接的状态,就算是数据库操作已经结束了。而且,自从我们的Apache开始重用它的子进程后——也就是说,下一次的HTTP请求会重用Apache的子进程,并重用相同的 MySQL 链接。
在理论上来说,这听起来非常的不错。但是从个人经验(也是大多数人的)上来说,这个功能制造出来的麻烦事更多。因为,你只有有限的链接数,内存问题,文件句柄数,等等。
而且,Apache 运行在极端并行的环境中,会创建很多很多的了进程。这就是为什么这种“永久链接”的机制工作地不好的原因。在你决定要使用“永久链接”之前,你需要好好地考虑一下你的整个系统的架构。
文章:来源
(全文完)
本文转自:http://coolshell.cn/articles/1846.html
posted @
2013-11-28 11:40 王海光 阅读(593) |
评论 (0) |
编辑 收藏一、多线程调试
多线程调试可能是问得最多的。其实,重要就是下面几个命令:
- info thread 查看当前进程的线程。
- thread <ID> 切换调试的线程为指定ID的线程。
- break file.c:100 thread all 在file.c文件第100行处为所有经过这里的线程设置断点。
- set scheduler-locking off|on|step,这个是问得最多的。在使用step或者continue命令调试当前被调试线程的时候,其他线程也是同时执行的,怎么只让被调试程序执行呢?通过这个命令就可以实现这个需求。
- off 不锁定任何线程,也就是所有线程都执行,这是默认值。
- on 只有当前被调试程序会执行。
- step 在单步的时候,除了next过一个函数的情况(熟悉情况的人可能知道,这其实是一个设置断点然后continue的行为)以外,只有当前线程会执行。
二、调试宏
这个问题超多。在GDB下,我们无法print宏定义,因为宏是预编译的。但是我们还是有办法来调试宏,这个需要GCC的配合。
在GCC编译程序的时候,加上-ggdb3参数,这样,你就可以调试宏了。
另外,你可以使用下述的GDB的宏调试命令 来查看相关的宏。
- info macro – 你可以查看这个宏在哪些文件里被引用了,以及宏定义是什么样的。
- macro – 你可以查看宏展开的样子。
三、源文件
这个问题问的也是很多的,太多的朋友都说找不到源文件。在这里我想提醒大家做下面的检查:
- 编译程序员是否加上了-g参数以包含debug信息。
- 路径是否设置正确了。使用GDB的directory命令来设置源文件的目录。
下面给一个调试/bin/ls的示例(ubuntu下)
$ apt-get source coreutils
$ sudo apt-get install coreutils-dbgsym
$ gdb /bin/ls
GNU gdb (GDB) 7.1-ubuntu
(gdb) list main
1192 ls.c: No such file or directory.
in ls.c
(gdb) directory ~/src/coreutils-7.4/src/
Source directories searched: /home/hchen/src/coreutils-7.4:$cdir:$cwd
(gdb) list main
1192 }
1193 }
1194
1195 int
1196 main (int argc, char **argv)
1197 {
1198 int i;
1199 struct pending *thispend;
1200 int n_files;
1201
四、条件断点
条件断点是语法是:break [where] if [condition],这种断点真是非常管用。尤其是在一个循环或递归中,或是要监视某个变量。注意,这个设置是在GDB中的,只不过每经过那个断点时GDB会帮你检查一下条件是否满足。
五、命令行参数
有时候,我们需要调试的程序需要有命令行参数,很多朋友都不知道怎么设置调试的程序的命令行参数。其实,有两种方法:
- gdb命令行的 –args 参数
- gdb环境中 set args命令。
六、gdb的变量
有时候,在调试程序时,我们不单单只是查看运行时的变量,我们还可以直接设置程序中的变量,以模拟一些很难在测试中出现的情况,比较一些出错,或是switch的分支语句。使用set命令可以修改程序中的变量。
另外,你知道gdb中也可以有变量吗?就像shell一样,gdb中的变量以$开头,比如你想打印一个数组中的个个元素,你可以这样:
(gdb) set $i = 0
(gdb) p a[$i++]
#然后就一路回车下去了
当然,这里只是给一个示例,表示程序的变量和gdb的变量是可以交互的。
七、x命令
也许,你很喜欢用p命令。所以,当你不知道变量名的时候,你可能会手足无措,因为p命令总是需要一个变量名的。x命令是用来查看内存的,在gdb中 “help x” 你可以查看其帮助。
- x/x 以十六进制输出
- x/d 以十进制输出
- x/c 以单字符输出
- x/i 反汇编 – 通常,我们会使用
x/10i $ip-20 来查看当前的汇编($ip是指令寄存器) - x/s 以字符串输出
八、command命令
有一些朋友问我如何自动化调试。这里向大家介绍command命令,简单的理解一下,其就是把一组gdb的命令打包,有点像字处理软件的“宏”。下面是一个示例:
(gdb) break func
Breakpoint 1 at 0x3475678: file test.c, line 12.
(gdb) command 1
Type commands for when breakpoint 1 is hit, one per line.
End with a line saying just "end".
>print arg1
>print arg2
>print arg3
>end
(gdb)
当我们的断点到达时,自动执行command中的三个命令,把func的三个参数值打出来。
(全文完)
本文转自:http://coolshell.cn/articles/3643.html
posted @
2013-11-28 11:12 王海光 阅读(469) |
评论 (0) |
编辑 收藏vim的学习曲线相当的大(参看各种文本编辑器的学习曲线),所以,如果你一开始看到的是一大堆VIM的命令分类,你一定会对这个编辑器失去兴趣的。下面的文章翻译自《Learn Vim Progressively》,我觉得这是给新手最好的VIM的升级教程了,没有列举所有的命令,只是列举了那些最有用的命令。非常不错。
——————————正文开始——————————
你想以最快的速度学习人类史上最好的文本编辑器VIM吗?你先得懂得如何在VIM幸存下来,然后一点一点地学习各种戏法。
Vim the Six Billion Dollar editor
Better, Stronger, Faster.
学习 vim 并且其会成为你最后一个使用的文本编辑器。没有比这个更好的文本编辑器了,非常地难学,但是却不可思议地好用。
我建议下面这四个步骤:
- 存活
- 感觉良好
- 觉得更好,更强,更快
- 使用VIM的超能力
当你走完这篇文章,你会成为一个vim的 superstar。
在开始学习以前,我需要给你一些警告:
- 学习vim在开始时是痛苦的。
- 需要时间
- 需要不断地练习,就像你学习一个乐器一样。
- 不要期望你能在3天内把vim练得比别的编辑器更有效率。
- 事实上,你需要2周时间的苦练,而不是3天。
第一级 – 存活
- 安装 vim
- 启动 vim
- 什么也别干!请先阅读
当你安装好一个编辑器后,你一定会想在其中输入点什么东西,然后看看这个编辑器是什么样子。但vim不是这样的,请按照下面的命令操作:
- 启 动Vim后,vim在 Normal 模式下。
- 让我们进入 Insert 模式,请按下键 i 。(陈皓注:你会看到vim左下角有一个–insert–字样,表示,你可以以插入的方式输入了)
- 此时,你可以输入文本了,就像你用“记事本”一样。
- 如果你想返回 Normal 模式,请按
ESC 键。
现在,你知道如何在 Insert 和 Normal 模式下切换了。下面是一些命令,可以让你在 Normal 模式下幸存下来:
i → Insert 模式,按 ESC 回到 Normal 模式.x → 删当前光标所在的一个字符。:wq → 存盘 + 退出 (:w 存盘, :q 退出) (陈皓注::w 后可以跟文件名)dd → 删除当前行,并把删除的行存到剪贴板里p → 粘贴剪贴板
推荐:
hjkl (强例推荐使用其移动光标,但不必需) →你也可以使用光标键 (←↓↑→). 注: j 就像下箭头。:help <command> → 显示相关命令的帮助。你也可以就输入 :help 而不跟命令。(陈皓注:退出帮助需要输入:q)
你能在vim幸存下来只需要上述的那5个命令,你就可以编辑文本了,你一定要把这些命令练成一种下意识的状态。于是你就可以开始进阶到第二级了。
当是,在你进入第二级时,需要再说一下 Normal 模式。在一般的编辑器下,当你需要copy一段文字的时候,你需要使用 Ctrl 键,比如:Ctrl-C。也就是说,Ctrl键就好像功能键一样,当你按下了功能键Ctrl后,C就不在是C了,而且就是一个命令或是一个快键键了,在VIM的Normal模式下,所有的键就是功能键了。这个你需要知道。
标记:
- 下面的文字中,如果是
Ctrl-λ我会写成 <C-λ>. - 以
: 开始的命令你需要输入 <enter>回车,例如 — 如果我写成 :q 也就是说你要输入 :q<enter>.
第二级 – 感觉良好
上面的那些命令只能让你存活下来,现在是时候学习一些更多的命令了,下面是我的建议:(陈皓注:所有的命令都需要在Normal模式下使用,如果你不知道现在在什么样的模式,你就狂按几次ESC键)
- 各种插入模式
a → 在光标后插入o → 在当前行后插入一个新行O → 在当前行前插入一个新行cw → 替换从光标所在位置后到一个单词结尾的字符
- 简单的移动光标
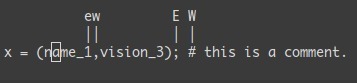
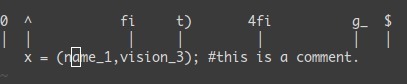
0 → 数字零,到行头^ → 到本行第一个不是blank字符的位置(所谓blank字符就是空格,tab,换行,回车等)$ → 到本行行尾g_ → 到本行最后一个不是blank字符的位置。/pattern → 搜索 pattern 的字符串(陈皓注:如果搜索出多个匹配,可按n键到下一个)
- 拷贝/粘贴 (陈皓注:p/P都可以,p是表示在当前位置之后,P表示在当前位置之前)
- Undo/Redo
- 打开/保存/退出/改变文件(Buffer)
:e <path/to/file> → 打开一个文件:w → 存盘:saveas <path/to/file> → 另存为 <path/to/file>:x, ZZ 或 :wq → 保存并退出 (:x 表示仅在需要时保存,ZZ不需要输入冒号并回车):q! → 退出不保存 :qa! 强行退出所有的正在编辑的文件,就算别的文件有更改。:bn 和 :bp → 你可以同时打开很多文件,使用这两个命令来切换下一个或上一个文件。(陈皓注:我喜欢使用:n到下一个文件)
花点时间熟悉一下上面的命令,一旦你掌握他们了,你就几乎可以干其它编辑器都能干的事了。但是到现在为止,你还是觉得使用vim还是有点笨拙,不过没关系,你可以进阶到第三级了。
第三级 – 更好,更强,更快
先恭喜你!你干的很不错。我们可以开始一些更为有趣的事了。在第三级,我们只谈那些和vi可以兼容的命令。
更好
下面,让我们看一下vim是怎么重复自己的:
. → (小数点) 可以重复上一次的命令- N<command> → 重复某个命令N次
下面是一个示例,找开一个文件你可以试试下面的命令:
2dd → 删除2行3p → 粘贴文本3次100idesu [ESC] → 会写下 “desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu desu “. → 重复上一个命令—— 100 “desu “.3. → 重复 3 次 “desu” (注意:不是 300,你看,VIM多聪明啊).
更强
你要让你的光标移动更有效率,你一定要了解下面的这些命令,千万别跳过。
- N
G → 到第 N 行 (陈皓注:注意命令中的G是大写的,另我一般使用 : N 到第N行,如 :137 到第137行) gg → 到第一行。(陈皓注:相当于1G,或 :1)G → 到最后一行。- 按单词移动:
w → 到下一个单词的开头。e → 到下一个单词的结尾。
> 如果你认为单词是由默认方式,那么就用小写的e和w。默认上来说,一个单词由字母,数字和下划线组成(陈皓注:程序变量)
> 如果你认为单词是由blank字符分隔符,那么你需要使用大写的E和W。(陈皓注:程序语句)
下面,让我来说说最强的光标移动:
% : 匹配括号移动,包括 (, {, [. (陈皓注:你需要把光标先移到括号上)* 和 #: 匹配光标当前所在的单词,移动光标到下一个(或上一个)匹配单词(*是下一个,#是上一个)
相信我,上面这三个命令对程序员来说是相当强大的。
更快
你一定要记住光标的移动,因为很多命令都可以和这些移动光标的命令连动。很多命令都可以如下来干:
<start position><command><end position>
例如 0y$ 命令意味着:
0 → 先到行头y → 从这里开始拷贝$ → 拷贝到本行最后一个字符
你可可以输入 ye,从当前位置拷贝到本单词的最后一个字符。
你也可以输入 y2/foo 来拷贝2个 “foo” 之间的字符串。
还有很多时间并不一定你就一定要按y才会拷贝,下面的命令也会被拷贝:
d (删除 )v (可视化的选择)gU (变大写)gu (变小写)- 等等
(陈皓注:可视化选择是一个很有意思的命令,你可以先按v,然后移动光标,你就会看到文本被选择,然后,你可能d,也可y,也可以变大写等)
第四级 – Vim 超能力
你只需要掌握前面的命令,你就可以很舒服的使用VIM了。但是,现在,我们向你介绍的是VIM杀手级的功能。下面这些功能是我只用vim的原因。
在当前行上移动光标: 0 ^ $ f F t T , ;
0 → 到行头^ → 到本行的第一个非blank字符$ → 到行尾g_ → 到本行最后一个不是blank字符的位置。fa → 到下一个为a的字符处,你也可以fs到下一个为s的字符。t, → 到逗号前的第一个字符。逗号可以变成其它字符。3fa → 在当前行查找第三个出现的a。F 和 T → 和 f 和 t 一样,只不过是相反方向。
还有一个很有用的命令是 dt" → 删除所有的内容,直到遇到双引号—— "。
区域选择 <action>a<object> 或 <action>i<object>
在visual 模式下,这些命令很强大,其命令格式为
<action>a<object> 和 <action>i<object>
- action可以是任何的命令,如
d (删除), y (拷贝), v (可以视模式选择)。 - object 可能是:
w 一个单词, W 一个以空格为分隔的单词, s 一个句字, p 一个段落。也可以是一个特别的字符:"、 '、 )、 }、 ]。
假设你有一个字符串 (map (+) ("foo")).而光标键在第一个 o 的位置。
vi" → 会选择 foo.va" → 会选择 "foo".vi) → 会选择 "foo".va) → 会选择("foo").v2i) → 会选择 map (+) ("foo")v2a) → 会选择 (map (+) ("foo"))

块操作: <C-v>
块操作,典型的操作: 0 <C-v> <C-d> I-- [ESC]
^ → 到行头<C-v> → 开始块操作<C-d> → 向下移动 (你也可以使用hjkl来移动光标,或是使用%,或是别的)I-- [ESC] → I是插入,插入“--”,按ESC键来为每一行生效。
在Windows下的vim,你需要使用 <C-q> 而不是 <C-v> ,<C-v> 是拷贝剪贴板。
自动提示: <C-n> 和 <C-p>
在 Insert 模式下,你可以输入一个词的开头,然后按 <C-p>或是<C-n>,自动补齐功能就出现了……
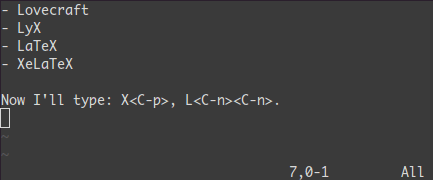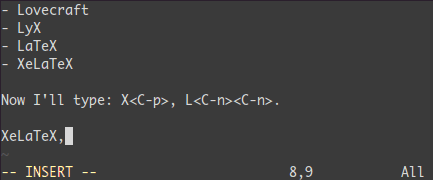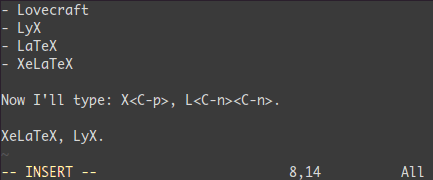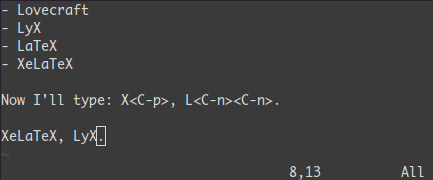
宏录制: qa 操作序列 q, @a, @@
qa 把你的操作记录在寄存器 a。- 于是
@a 会replay被录制的宏。 @@ 是一个快捷键用来replay最新录制的宏。
示例
在一个只有一行且这一行只有“1”的文本中,键入如下命令:
qaYp<C-a>q→qa 开始录制Yp 复制行.<C-a> 增加1.q 停止录制.
@a → 在1下面写下 2@@ → 在2 正面写下3- 现在做
100@@ 会创建新的100行,并把数据增加到 103.

可视化选择: v,V,<C-v>
前面,我们看到了 <C-v>的示例 (在Windows下应该是<C-q>),我们可以使用 v 和 V。一但被选好了,你可以做下面的事:
J → 把所有的行连接起来(变成一行)< 或 > → 左右缩进= → 自动给缩进 (陈皓注:这个功能相当强大,我太喜欢了)
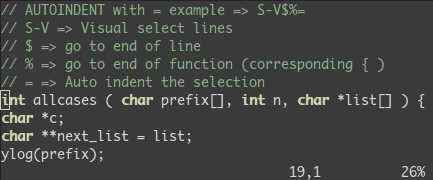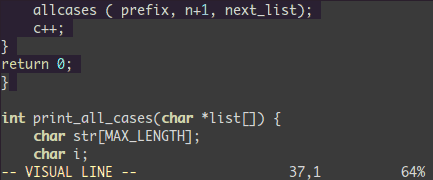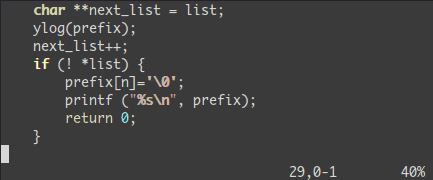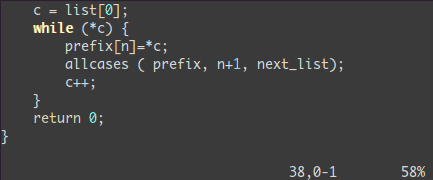
在所有被选择的行后加上点东西:
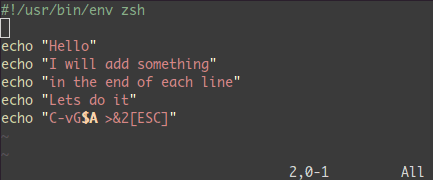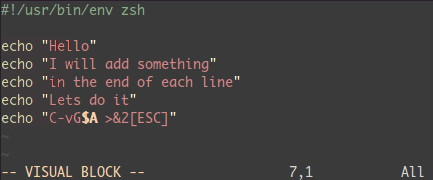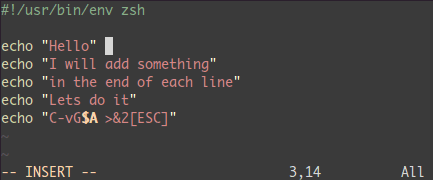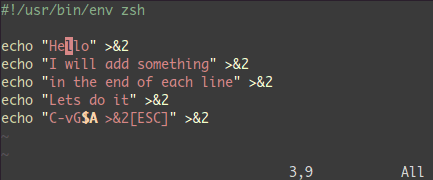
<C-v>- 选中相关的行 (可使用
j 或 <C-d> 或是 /pattern 或是 % 等……) $ 到行最后A, 输入字符串,按 ESC。
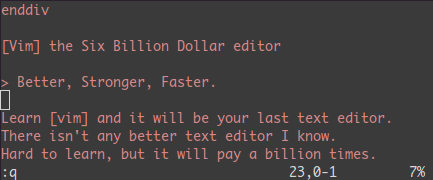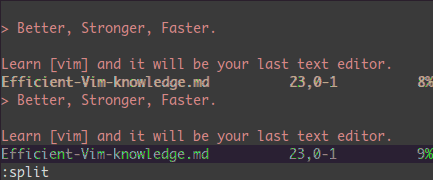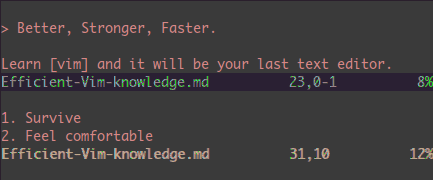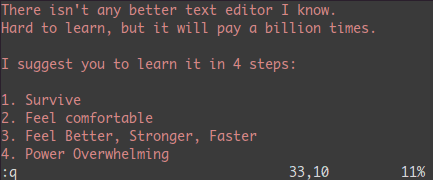
分屏: :split 和 vsplit.
下面是主要的命令,你可以使用VIM的帮助 :help split. 你可以参考本站以前的一篇文章VIM分屏。
:split → 创建分屏 (:vsplit创建垂直分屏)<C-w><dir> : dir就是方向,可以是 hjkl 或是 ←↓↑→ 中的一个,其用来切换分屏。<C-w>_ (或 <C-w>|) : 最大化尺寸 (<C-w>| 垂直分屏)<C-w>+ (或 <C-w>-) : 增加尺寸
结束语
- 上面是作者最常用的90%的命令。
- 我建议你每天都学1到2个新的命令。
- 在两到三周后,你会感到vim的强大的。
- 有时候,学习VIM就像是在死背一些东西。
- 幸运的是,vim有很多很不错的工具和优秀的文档。
- 运行vimtutor直到你熟悉了那些基本命令。
- 其在线帮助文档中你应该要仔细阅读的是
:help usr_02.txt. - 你会学习到诸如
!, 目录,寄存器,插件等很多其它的功能。
学习vim就像学弹钢琴一样,一旦学会,受益无穷。
——————————正文结束——————————
对于vi/vim只是点评一点:这是一个你不需要使用鼠标,不需使用小键盘,只需要使用大键盘就可以完成很多复杂功能文本编辑的编辑器。不然,Visual Studio也不就会有vim的插件了。
(全文完)
本文转自:http://coolshell.cn/articles/5426.html
posted @
2013-11-28 10:56 王海光 阅读(374) |
评论 (0) |
编辑 收藏对于Makefile中的各种变量,可能是我们比较头痛的事了。我们要查看他们并不是很方便,需要修改makefile加入echo命令。这有时候很不方便。其实我们可以制作下面一个专门用来输出变量的makefile(假设名字叫:vars.mk)
vars.mk
1 %:
2 @echo '$*=$($*)'
3
4 d-%:
5 @echo '$*=$($*)'
6 @echo ' origin = $(origin $*)'
7 @echo ' value = $(value $*)'
8 @echo ' flavor = $(flavor $*)'
这样一来,我们可以使用make命令的-f参数来查看makefile中的相关变量(包括make的内建变量,比如:COMPILE.c或MAKE_VERSION之类的)。注意:第二个以“d-”为前缀的目标可以用来打印关于这个变量更为详细的东西(后面有详细说明)
假设我们的makefile是这个样子(test.mk)
test.mk
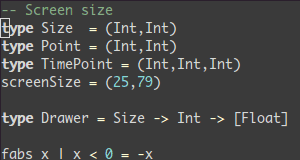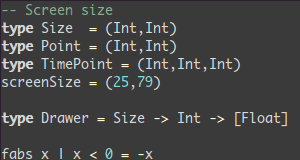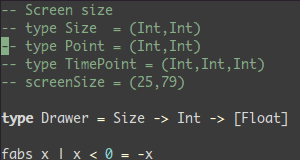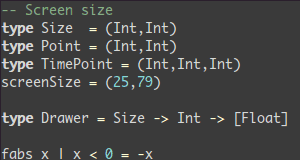
1 OBJDIR := objdir
2 OBJS := $(addprefix $(OBJDIR)/,foo.o bar.o baz.o)
3
4 foo = $(bar)bar = $(ugh)ugh = Huh?
5
6 CFLAGS = $(include_dirs) -O
7 include_dirs = -Ifoo -Ibar
8 CFLAGS := $(CFLAGS) -Wall
9
10 MYOBJ := a.o b.o c.o
11 MYSRC := $(MYOBJ:.o=.c)
那么,我们可以这样进行调试:
演示
1 [hchen@RHELSVR5]$ make -f test.mk -f var.mk OBJS
2 OBJS=objdir/foo.o objdir/bar.o objdir/baz.o
3
4 [hchen@RHELSVR5]$ make -f test.mk -f var.mk d-foo
5 foo=Huh?
6 origin = file
7 value = $(bar)
8 flavor = recursive
9
10 [hchen@RHELSVR5]$ make -f test.mk -f var.mk d-CFLAGS
11 CFLAGS=-Ifoo -Ibar -O -O
12 origin = file
13 value = -Ifoo -Ibar -O -O
14 flavor = simple
15
16 [hchen@RHELSVR5]$ make -f test.mk -f var.mk d-COMPILE.c
17 COMPILE.c=cc -Ifoo -Ibar -O -Wall -c
18 origin = default
19 flavor = recursive
20 value = $(CC) $(CFLAGS) $(CPPFLAGS) $(TARGET_ARCH) -c
我们可以看到:
- make的第一个-f后是要测试的makefile,第二个是我们的debug makefile。
- 后面直接跟变量名,如果在变量名前加”d-”,则输出更为详细的东西。
说一说”d-” 前缀(其意为details),其中调用了下面三个参数。
- $(origin):告诉你这个变量是来自哪儿,file表示文件,environment表示环境变量,还有environment override,command line,override,automatic等。
- $(value):打出这个变量没有被展开的样子。比如上述示例中的 foo 变量。
- $(flavor):有两个值,simple表示是一般展开的变量,recursive表示递归展开的变量。
(全文完)
本文转自:http://coolshell.cn/articles/3790.html#more-3790
posted @
2013-11-28 10:46 王海光 阅读(1058) |
评论 (0) |
编辑 收藏