这几天一个学生在调试视频捕捉程序的时候遇到了一个问题。他使用capGetVideoFormat函数获得视频的格式时,发现m_bmpinfo.bmiHeader.biBitCount为16,他认为这是表示16位的RGB格式。可是不管他是使用RGB565,还是RGB555格式进行转换时,发现转换后的YUV文件都是不对的。在我的Sony笔记本上运行他的程序,其中的m_bmpinfo.bmiHeader.biCompression的值为1498831189,这说明笔记本的摄像头所采集的数据的格式并不是普通的16位RGB数据,而是UYVY格式的。UYVY格式是YUV格式的一个变种,在网上可以找到详细的说明,在此就不赘述了。
要想知道biCompression到底有多少种取值,可以参考一下:http://files.codes-sources.com/fichier.aspx?id=45735&f=src/org/hypik/webcamlib/codecs/Codecs.java。在这里详细的列出了各种视频压缩的编码。
怎样才能知道自己的摄像头到底支持哪种格式的输出呢?可以使用capDlgVideoFormat函数:
capDlgVideoFormat(m_wndVideo);
这个函数会激活摄像头驱动的视频格式设置对话框,如下图所示。
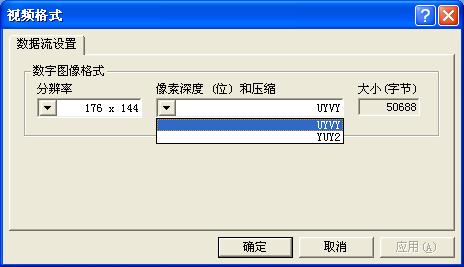
我的这个摄像头支持2种输出格式,一种是UYVY,另一种是YUV2。 如果将m_bmpinfo.bmiHeader.biCompression设置为这两种之外的值,再使用capSetVideoFormat改变输出格式,由于驱动程序不支持而不会获得成功。
posted @
2010-11-16 22:30 zealsoft 阅读(1936) |
评论 (1) |
编辑 收藏
这两天一直希望找个可以移植到VxWorks上的Log库,早就知道大名鼎鼎的Log4c,但一直想找个更好的,本来看上了Pantheios,觉得它的架构非常清晰,使用也很简便,特别是其网站上宣传它的性能非常卓越。但是仔细看了这个库后发现这个库基于STL和STLsoft,STL在VxWorks是很影响性能的,只好放弃。看看其他的Log库,大多数都是基于C++的,对于嵌入式应用还是不适合。我觉得一个理想的轻量级Log库,最好具有以下特征:
- 完全用C编写
- 核心模块不依赖任何第3方的函数库
- 可以动态开关Log功能。当关闭Log功能时,所产生的开销应当明显小于打开Log功能。
- API接口清晰易用,就象printf一样。
找了一圈,发现还是Log4c最合适。所以只好决定在Log4c的基础上移植了,看来找到一个轻量级的Log库不太容易。
posted @
2009-10-10 22:25 zealsoft 阅读(2987) |
评论 (11) |
编辑 收藏
今天尝试用Visual Studio 2005编译以前用Visual Studio 2003编译成功过的一个Wireshark插件,生成后发现居然无法在官方的Wireshark中加载插件。在 KenThompson的“Creating Your Own Custom Wireshark Dissector”一文中提到使用Visual Studio 2005编译生成的插件只能在使用Visual Studio 2005生成的Wireshark版本中测试。使用自己采用Visual Studio 2005生成的Wireshark版本测试,发现确实可以,而官方的就不行了。使用Dependency Walker看了看,发现使用Visual Studio 2005生成的DLL文件需要使用MSVCR80.DLL,而官方的Wireshark使用的是MSVCRT.DLL,两者不兼容,所以会出现错误。在微软的网站上可以找到解决的方法:
mt.exe –manifest MyLibrary.dll.manifest -outputresource:MyLibrary.dll;2
将这样处理后的DLL再拷贝到官方的Wireshark的插件目录中就可以了。不过采用Visual Studio 2005生成的插件要分发时必须同时分发Visual Studio 2005的C语言运行库,看来不如Visual Studio 2003方便。
posted @
2009-04-24 23:26 zealsoft 阅读(2789) |
评论 (4) |
编辑 收藏
今天甲方通知要统计一下我们协议栈代码的行数,好久没有关心过这样的问题,上一次统计代码行数好像是好多年前的事情了,也忘记了用的什么工具。最开始想用NLOC,因为需要.NET 2.0,我的机器装不上。为了这个工具安装.NET 2.0有点不划算。又找了一个C++编写的工具Code Counter Tool。这个工具可以支持Visual C++ 6.0的工程。不过我们的工程是VxWorks工程,对于非VC6的工程需要建立一个.map文件,里面包括所有需要统计的文件。这个工作可以在命令行中完成:
dir /b > prj.map
其中的/b参数表示只显示文件名,dir的结果会写入prj.map文件,正好可以满足要求。
最后的统计结果表明,我们的协议栈有109个文件(不包括需要的运行库),共161,688行代码,其中空白行13,554,注释行为38,311。这是一个小巧的,但是完整的基站协议栈代码。
posted @
2009-01-22 16:30 zealsoft 阅读(1249) |
评论 (1) |
编辑 收藏
因为TETRA标准中分组数据的压缩协议为V.42 bis,让学生在网上找个代码来用。学生找了半天,只找到LZW的代码,没有找到V.42bis,虽然两者差别较少,但是还是不同的,只好自己找。其实找起来很容易,在
Google CodeSearch上输入v42bis就找到了。找到的是
SpanDSP这个库中的一个文件,写得很清晰,注释也比较全。SpanDSP是一个专用于电话领域的信号处理库,包括各种语音编码、采用的协议处理等等,象项目中用到的
HDLC协议在这里也可以找到。在查找代码方面,Google CodeSearch比直接使用Google方便多了。
posted @
2009-01-21 22:07 zealsoft 阅读(1259) |
评论 (0) |
编辑 收藏
最近太太的学校使用思维导图总结教学中的知识点,她因为电脑不熟,我帮了下忙,结果发现这个思维导图真的很方便!今天用思维导图整理了一下项目的知识体系,为下一步安排学生课题、申请专利和发表文章做准备。由于课题内容比较敏感,下面用一些简单的例子代替实际做的工程。
使用思维导图的最大好处是方便,只要使用Enter键就可以添加一个节点,而使用Tab键就可以添加一个子节点,如果发现节点的层次或顺序不对,可以随意地拖动节点进行调整,一起都很方便,不象Visio或者SmartDraw,必须点几下鼠标才能完成这些操作。你可以想到哪里,就画到哪里,特别适合边思考,边整理,比在纸上比划还方便。下面就是一个简单的例子。
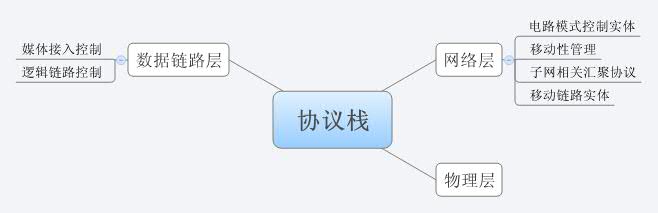
以前我整理项目的知识体系,往往使用SmartDraw(Visio在这方面比SmartDraw更难使)。使用SmartDraw,一是操作比思维导图麻烦,二是如果图太大了,为了便于阅读,就必须将体系结构图按照层次分割成很多文件,然后利用SmartDraw的链接功能将它们链接到一起。而在思维导图中,这一切就变得很容易。你可以在一张图中画下所有层次关系,如果觉得层次多了,可以用鼠标点下节点右侧“减号”,就可以把子节点都收起来,象下图一样。如果想看子节点,再点一下节点右侧“加号”就可以,收缩自如,非常方便。

有时候子节点太多,希望在一个单独的窗口中编辑或显示,可以选择Drill down功能,它可以把所有子节点都显示在一个单独的窗口中,而选择Drill up功能又可以回到顶层。这样既可以方便地观察全局,又可以照顾导细节,比SmartDraw/Visio方便多了。
其实最早接触思维导图,是前段时间在广州,七所的吴挺用MindMap制作了一个项目的进度表,每个节点前可以加上Marker清晰地看出每个项目进展的情况,象下面这张图一样。不过当时误以为这个软件是类似Visio或者Project那样的软件,没有重视,现在才发现完全不是那么回事。
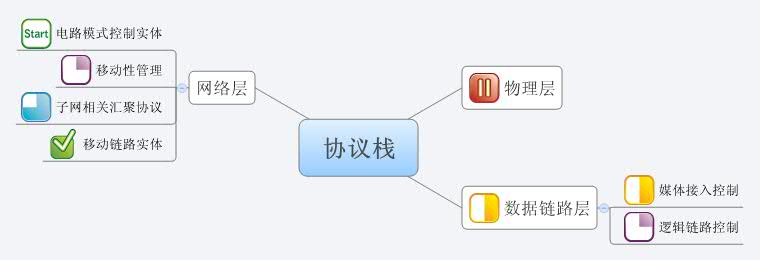
在网上搜索了一下,对思维导图的介绍还真是很多,可惜我今天才用上。我推荐百度百科的相关介绍,值得一读。
支持思维导图的软件很多,前面的博客已经说了,我要尽量使用开源软件。在网上真找到一款相当不错的:XMind。
posted @
2008-12-11 23:29 zealsoft 阅读(3555) |
评论 (7) |
编辑 收藏
Google CTemplate提供了调节器(Modifier)功能。所谓调节器,类似于在模板中可以使用的用户自定义函数,也就是对于相同的数据字典内容,模板中使用不同的调节器就可以显示不同的内容。
要编写一个调节器,需要从template_modifiers::TemplateModifier派生一个类:

 Code
Code
class BitStringModifier : public template_modifiers::TemplateModifier {
void Modify(const char* in, size_t inlen,
const ctemplate::PerExpandData* per_expand_data,
ExpandEmitter* outbuf, const std::string& arg) const;
};
BitString 调节器的作用是将数值型数据转换为二进制字符串显示。其在模板中的使用如下所示:
bstr = bstr + '{{item_type3id:x-bitstring=4}}'b;
用户自定义的调节器一般采用“x-”开头。调节器可以带有用户参数,例如上例的“=4”就是用户参数,表示生成的二进制串的长度为4,如果不足4位,前面自动补0。
调节器的主要功能是在Modify函数中实现的,在该函数中调用outbuf->Emit函数来输出所需要的结果。
Code
void BitStringModifier::Modify(const char* in, size_t inlen,
const ctemplate::PerExpandData* per_expand_data,
ExpandEmitter* outbuf, const std::string& arg) const
{
int x = atoi(string(in, inlen).c_str());
unsigned int len = atoi(arg.c_str() + 1);
string sID = itoa(x, 2);
while(sID.size() < len)
sID = "0" + sID;
outbuf->Emit(sID);
}
要在程序中支持调节器,还需要调用google::template_modifiers::AddModifier函数添加BitStringModifier的实例。如:
Code
BitStringModifier bitStringModifier;
/// 注册自定义的Modifier
google::template_modifiers::AddModifier("x-bitstring=", &bitStringModifier);
posted @
2008-10-15 22:03 zealsoft 阅读(1484) |
评论 (0) |
编辑 收藏
TAU G2程序本身的仿真功能很强,如果程序在目标机上运行时出现逻辑错误,你总是可以在TAU G2的仿真环境下模拟出这个错误并找到出错的原因,一般不需要借助操作系统的C代码调试工具。但是如果是在TAU G2中调用了C语言的函数,或者在环境函数中出现错误,问题就复杂了,因为TAU G2的仿真环境无法跟踪这些C语言的代码,你只能借助操作系统自身的调试功能了。
TAU G2生成的程序至少是2个线程:一个是主线程,就是main函数所在的线程,象环境函数中的xInitEnv和xInEnv都是在主线程中的,主线程设置断点很容易,只要在启动调试器后,使用Debug菜单中的Toggle Breakpoint(F9)就可以了,因为调试器默认就是把主线程当作当前线程的;另一个线程是UML代码所在的线程,通常你不需要在生成的UML代码中设置断点,但是xOutEnv在这个线程中,而且如果在UML代码中调用了C语言的函数,那么这些C语言的函数也在这个线程中,而在这个线程中如果还是用F9直接设置断点就往往不会成功了,程序往往不会停下来而是继续执行。
要想在xOutEnv或者自己编写的C语言函数中设置断点进行调试,可以使用Debug菜单中的Toggle Global Breakpoint(Shift F9)设置全局断点。设置全局断点后,当UML代码所在的线程执行到断点处,这个线程就会停下来,此时可以使用Debug菜单中的Attach功能,将当前线程由主线程变为UML线程,这样就可以单步跟踪调试了。UML线程在Attach对话框中通常是最后一个线程,默认情况下其名字应该为t1,但是有的时候线程名会显示为乱码。
posted @
2008-10-13 23:18 zealsoft 阅读(1306) |
评论 (0) |
编辑 收藏
模板引擎(Template engine)是实现模型和视图分离的一个重要手段。如果你从未接触过模板引擎可以看看
Wiki的介绍。模板引擎的流行最初是因为网站开发的需要,象比较重要的几个模板引擎:SMARTY、Velocity、StringTemplate都是来源于网页设计的。当然,除了网页设计,模板引擎还可以应用于其他领域,而我主要将其应用与代码生成器的设计中。
有关模板引擎,我推荐StringTemplate的作者Terence Parr 写的一篇
英文论文。Terence Parr是一个大学教授,写的文章自然学术性比较强,较难懂,但是很有参考价值。借助这篇文章的分析,我们可以发现当前模板引擎有着两种不同的思路:一种是严格将模型和视图分开的,设计模板系统时往往提供的模板语言比较简单,避免在模板语言中加入运算符号等,另一种是提供强大的模板语言功能,模板语言具有类似高级语言的功能,如各种条件判断语句,甚至数学运算能力。显然从模板编写者的角度看,后者具有更强大的功能,几乎无所不能,但是安全性不如前者,模板的编写者更容易利用系统漏洞做模板系统设计者没有想到的事情。这个问题仁者见仁,智者见智,好在由很多的模板系统可以选择。
绝大多数模板引擎都是支持Java、PHP、Python的,这当然和模板引擎的应用领域相关。我的代码生成器是用C++写的,而且必须支持Windows平台,所以选择的范围就比较有限了,从网络上搜索了一下,似乎只有
Teng、
CT++和
Google CTemplate可以使用了。我对3个系统进行了简单的评估,并实际使用过CT++和CTemplate,现在总结一下自己的心得,希望对大家有一些帮助。
1、操作系统的支持
我的主要工作是在Windows上的,而模板引擎绝大多数是面向Unix/Linux的,这和我的需求有一定距离。当初曾经下载过Teng,但是折腾了半天也没有能够让其在Visual Studio 2003下成功编译,所以就放弃了,后来将CT++ 1.8简单地处理了一下就可以跑了,很开心。而Google CTemplate更提供了完全的Windows支持,这对于我这样的用户当然是非常省心了。
2、软件开发的活跃度
这些软件都是开源的,软件开发的活跃度当然是我关心的,有的工具刚开始用的时候很开心,但是后来开发者没有兴趣不玩了,而又没有人接手,BUG也无法更新了,就比较苦了,典型的象TurboPower。Teng似乎已经很长时间不更新了,CT++一直在更新,但是开发者是俄罗斯人,全部文档是俄文的,包括程序注释,以前1.8还有英文文档,从2.0以后就没有了,虽然最近承诺2.4以后会报告英文文档,但是我担心他哪天不高兴就不玩了,所以最后下定决心转到CTemplate去了。CTemplate虽然是Google的,而且据说Google内部也在使用,但是在模板引擎领域的名气却不大,好像作者的热情仍然很高,持续更新,而且可能很快要升级到1.0版本了,这给我很大的信心。
3、模板语言的功能
在我看来,模板语言的功能越强,提供的函数越多,它可能越受模板编写者的欢迎,但是可能不符合模型和视图严格分离的原则。Teng和CT++都属于模板语言功能强的一类,象Teng甚至提供了大量的运算符,而CTemplate显然是严格按照模型和视图分离原则设计的,它甚至没有提供if/else这样在其他模板系统中都有的功能。如前所述,这个问题仁者见仁,智者见智,不争论了。下面简单地列个表比较一下。由于CT++ 2没有英文文档,一直就没有使用过,可能会遗漏一些新功能。
|
Teng |
CT++ |
CTemplate |
| 变量 |
支持 |
支持 |
支持 |
| 函数 |
支持 |
支持 |
支持(Modifier) |
| 包含 |
支持 |
支持 |
支持 |
| 条件语句 |
支持 |
支持 |
不支持 |
| 循环 |
支持 |
支持 |
支持 |
| 计算 |
支持 |
不支持 |
不支持 |
| 赋值 |
支持 |
不支持 |
不支持 |
| 注释 |
支持 |
支持 |
支持 |
| 安全性设计 |
不支持 |
不支持 |
支持 |
| 用户定义函数 |
不支持 |
支持 |
支持 |
4、C++ API
基本的API几个软件都差不多,我觉得CTemplate更完善一些,特别喜欢它的调试功能。
总体来说,我对CT++还是有些难舍,但是综合考虑之后还是决定转到CTemplate上。
posted @
2008-09-17 21:42 zealsoft 阅读(2675) |
评论 (2) |
编辑 收藏
最近开始尝试使用Doxygen生成程序的文档。程序的源代码采用的是GB2312的格式存储的,而Doxygen输出的文档是UTF-8格式的,出现了乱码。虽然Visual Studio 2003支持以UTF-8格式存储源代码,但是要把所有文件都转换担心太麻烦。于是,在配置文件中增加了一行代码:
INPUT_ENCODING = GB2312
这下问题解决了,Doxygen在生成文档时自动将文件的编码从GB2312转换为UTF-8,输出就没有乱码了。
posted @
2008-09-09 16:49 zealsoft 阅读(1943) |
评论 (0) |
编辑 收藏